







分类目录:《深入理解机器学习》总目录
相关文章:
· 集成学习(Ensemble Learning):基础知识
· 集成学习(Ensemble Learning):提升法Boosting与Adaboost算法
· 集成学习(Ensemble Learning):袋装法Bagging
· 正则化(Regularization):Bagging和其他集成方法
集成学习基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上,就是“三个臭皮匠顶个诸葛亮”的道理。
历史上, Kearns和Valiant首先提出了“强可学习(Strongly Learnable)”和“弱可学习(Weakly Learnable)”的概念。他们指出:在概率近似正确(Probably approximately correct, PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。非常有趣的是,Schapire后来证明强可学习与弱可学习是等价的,也就是说,在PAC学习的框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。
集成学习 (Ensemble Learning)就是通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统( Multi-classifier System)、基于委员会的学习( Committee-based Learning)等。
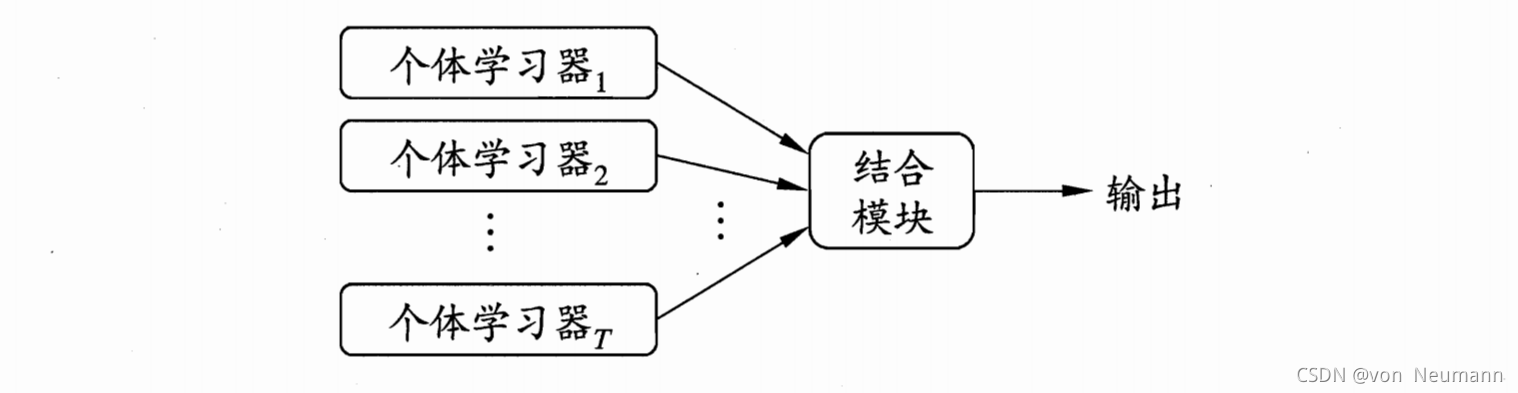
上图显示出集成学习的一般结构:先产生一组“个体学习器”),再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生,例如C4.5决策树算法、BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”
的。同质集成中的个体学习器亦称“基学习器”,相应的学习算法称为“基学习算法”。集成也可包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成是“异质”的。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法;相应的,个体学习器一般不称为基学习器,常称为“组件学习器”或直接称为个体学习器。
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能这对“弱学习器”尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。但需注意的是,虽然从理论上来说使用弱学习器集成足以获得好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用关于常见学习器的一些经验等,人们往往会使用比较强的学习器。在一般经验中,如果把好坏不等的东西掺到一起,那么通常结果会是比最坏的要好一些,比最好的要坏一些。但在集成学习中,把多个学习器结合起来,能获得比最好的单一学习器更好的性能。
考虑一个简单的例子:在二分类任务中,假定三个分类器在三个测试样本上的表现如下图所示,其中√表示分类正确,×表示分类错误,集成学习的结果通过投票法产生,即“少数服从多数”,在下图(a)中,每个分类器都只有66.6%的精度,但集成学习却达到了100%;在下图(b)中我们可以看到,三个分类器没有差别,集成之后性能没有提高;在下图(c)中,每个分类器的精度都只有33.3%,集成学习的结果变得更糟。这个简单的例子显示出:要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器间具有差异。

考虑二分类问题
y
∈
{
1
,
−
1
}
y\in\{1, -1\}
y∈{1,−1}和真实函数
f
f
f,假定基分类器的错误率为
ϵ
\epsilon
ϵ,即对每个基分类器
h
i
h_i
hi有:
P
(
h
i
(
x
)
≠
f
(
x
)
)
=
ϵ
P(h_i(x)\neq f(x))=\epsilon
P(hi(x)=f(x))=ϵ
假设集成通过简单投票法结合
T
T
T个基分类器,若有超过半数的基分类器正确,则集成分类就正确:
H
(
x
)
=
sign
(
∑
i
=
1
T
h
i
(
x
)
)
H(x)=\text{sign}(\sum_{i=1}^Th_i(x))
H(x)=sign(i=1∑Thi(x))
假设基分类器的错误率相互独立,则由 Hoeffding不等式可知,集成的错误率为:
P
(
H
(
x
)
≠
f
(
x
)
)
=
∑
k
=
0
⌊
T
2
⌋
(
T
k
)
(
1
−
ϵ
)
k
ϵ
T
−
k
≤
e
−
1
2
T
(
1
−
2
ϵ
)
2
P(H(x)\neq f(x))=\sum_{k=0}^{\lfloor\frac{T}{2}\rfloor}\binom{T}{k}(1-\epsilon)^k\epsilon^{T-k}\leq e^{-\frac{1}{2}T(1-2\epsilon)^2}
P(H(x)=f(x))=k=0∑⌊2T⌋(kT)(1−ϵ)kϵT−k≤e−21T(1−2ϵ)2
上式显示出,随着集成中个体分类器数目 T T T的增大,集成的错误率将指数级下降,最终趋向于零然而我们必须注意到,上面的分析有一个关键假设:基学习器的误差相互独立。在现实任务中,个体学习器是为解决同一个问题训练出来的,它们显然不可能相互独立。事实上,个体学习器的“准确性”和“多样性”本身就存在冲突。一般的,准确性很高之后,要增加多样性就需牺牲准确性。事实上,如何产生并结合“好而不同”的个体学习器,恰是集成学习研究的核心根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是 Boosting,后者的代表是 Bagging。
参考文献:
[1] 周志华. 机器学习[M]. 清华大学出版社, 2016.
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











