







ZooKeeper
1. ZooKeeper入门
1.1. 教学目标
1.1.1. 掌握ZooKeeper的是什么
1.1.2. 掌握ZooKeeper的角色
1.1.3. 掌握ZooKeeper的数据模型和节点
1.1.4. 掌握ZooKeeper的单机和集群安装
1.1.5. 掌握ZooKeeper的基本操作
1.1.6. 了解ZooKeeper的应用场景
1.2. 课程内容
1.2.1. ZooKeeper是什么
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
一言以蔽之,ZooKeeper是分布式系统中的协调系统。
有如下特点:
Ø 简单
ZooKeeper的核心是一个精简的文件系统,它支持一些简单的操作和一些抽象操作,例如,排序和通知。
Ø 丰富
ZooKeeper的原语操作是很丰富的,可实现一些协调数据结构和协议。例如,分布式队列、分布式锁和一组同级别节点中的“领导者选举”。
Ø 高可靠
ZooKeeper支持集群模式,可以很容易的解决单点故障问题。
Ø 松耦合交互
不同进程间的交互不需要了解彼此,甚至可以不必同时存在,某进程在ZooKeeper中留下消息后,该进程结束后其它进程还可以读这条消息。
Ø 资源库
ZooKeeper实现了一个关于通用协调模式的开源共享存储库,能使开发者免于编写这类通用协议。
1.2.2. ZooKeeper的角色
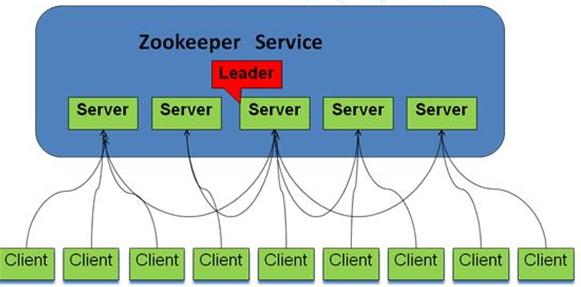
领导者(leader):负责进行投票的发起和决议,更新系统状态。
学习者(learner):包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并向客户端返回结果,在选举过程中参与投票。Observer可以接受客户端连接,将写请求转发给leader,但observer不参与投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
客户端(client),请求发起方。
1.2.3. ZooKeeper的数据模型和节点
1.2.3.1. 数据模型
1.2.3.2. 节点
ZooKeeper节点znode有两种类型,临时节点(ephemeral)和持久节点(persistent)。Znode的类型在创建时确定并且之后不能再修改。
ephemeral节点在客户端会话结束时,将会被zookeeper删除,并且ephemeral节点不可以有子节点。
Persistent节点不依赖与客户端会话,只有荡客户端明确要删除该persistent节点时才会被删除。
目前Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL
Znode可以是临时节点,一旦创建这个znode的客户端与服务器失去联系,这个znode也将自动删除,ZooKeeper的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称之为session,如果znode是临时节点,这个seesion失效,znode也就删除了;持久化目录节点,这个目录节点存储的数据不会丢失;顺序自动编号的目录节点,这种目录节点会更具当前已经存放在的节点数自动加1,然后返回给客户端已经成功创建的目录节点名;临时目录节点,一旦创建这个节点的客户端和服务器端口也就是session超时,这种节点会被自动删除。
1.2.4. ZooKeeper的安装
ZooKeeper的安装和配置十分简单,既可以配置成单机模式,也可以配置成集群模式,下面就一一介绍这几种安装方式。
官方网址:http://zookeeper.apache.org。
讲课采用的版本:zookeeper-3.4.6.tar.gz。
下载地址:
http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
1.2.4.1. 单机模式
将ZooKeeper的安装包解压到/usr/local/目录下。当然为了以后使用其命令的方便,可以在环境变量中配置ZOOKEEPER_HOME。
进入ZooKeeper目录下的conf子目录。
将zoo_sample.cfg备份为zoo.cfg,在次基础上进行修改配置
主要配置以下括起来的几项内容
说明:
tickTime:ZooKeeper中使用的基本时间单位,毫秒值。
dataDir:ZooKeeper数据文件,可以是任意目录。
dataLogDir:ZooKeeper日志文件,同样可以是任意目录,需要手动创建。
clientPort:ZooKeeper监听client连接的端口号。
至此,zookeeper的单机模式我们已经配置好了,启动server只需要运行其脚本。
sh $ZOOKEEPER_HOME/bin/zkServer.sh start
如上图,ZooKeeper服务已经启动,这个时候可以启动ZooKeeper客户端来连接server。
sh $ZOOKEEPER_HOME/bin/zkCli.sh -serverlocalhost:2181
1.2.4.2. 伪分布模式
所谓伪分布模式,是指在单台物理机器上启动多个ZooKeeper进程,并组成一个集群。一般的ZooKeeper的节点个数都2n+1,这里以启动3个进程为例,将上述的zookeeper的目录拷贝2份。
修改zookeeper0/conf/zoo.cfg配置文件为如下,新加几项配置项。
新增参数含义如下:
initLimit:ZooKeeper集群中的包含多台server,其中一台为leader,集群中其余为follower。initLimit参数配置初始化连接时,follower和leader之间的最长心跳时间。此时该参数设置为10,说明时间限制为10倍tickTime,即10*2000=20000ms=20s。
syncLimit:该参数配置leader和follower之间发送消息,请求和应答的最大时间长度。此时该参数设置为5,说明时间限制为5倍tickTime,即10s。
server.X=A:B:C 其中X是一个数字,表示这是第几号server,A是该server所在的IP地址,B配置该server和集群中的leader交换消息所需要使用的端口,C配置选举leader时所使用的端口。由于配置的是伪分布模式,所以各个server的B,C参数必须不同。
参照zookeeper0/conf/zoo.cfg,配置zookeeper1/conf/zoo.cfg和zookeeper2/conf/zoo.cfg文件,只需要修改dataDir、dataLogDir、clientPort
在之前设置的dataDir中新建一个myid文件,写入一个数字,该数字表示这是第几号server,该数字必须和server.X中的X一一对应。
/usr/local/zookeeper0/data/myid文件写入0,以此类推。
这个时候,分别进入zookeeper*/bin目录下,启动个子server
查看各个节点状态:
连接客户端和单机模式连接一样,进入任何一个节点
bin/zkCli.sh -server localhost:2181/2812/2183
1.2.4.3. 完全分布式模式
完全分布式模式和伪分布模式基本一致。由于完全分布式模式下,各个server部署在不同的机器上,因此各server的conf/zoo.cfg文件可以完全一样。
以下为一个配置示例:
其中三台机器的zoo.cfg完全一致。只不过这里的myid改为150,151,152了,需要互相保持一致。启动服务,客户端连接都和上述一致。
1.2.5. ZooKeeper的基本操作
1.2.5.1. Shell操作
ZooKeeper相关操作如下:
1、连接到ZooKeeper服务
[root@service zookeeper0]# bin/zkCli.sh-server localhost:2181
2、使用ls命令查看当前ZooKeeper中包含的内容
3、创建新的znode,使用create命令
4、获取节点中的值,get命令
5、使用set命令来对znode关联的字符串进行设置
6、删除节点
1.2.5.2. Java api操作
客户端要连接ZooKeeper服务器可以通过创建org.apache.zookeeper.ZooKeeper的一个实例对象,然后调用提供的api与服务器进行交互。
之前已经了解了ZooKeeper主要是用来维护和监控一个目录节点数中存储的数据的状态,所有我们能够操作的ZooKeeper的也和操作目录节点树大体一致,如果见一个目录节点,给某个目录节点设置数据,获取某个目录节点的所有子目录节点等等。
相关主要接口如下列表所示:
| 方法名称 | 描述 |
| String create(final String path, byte data[], List acl, CreateMode createMode) | 创建一个znode节点。 参数:路径、znode内容、ACL(访问控制列表)、znode创建类型 |
| void delete(final String path, int version) | 删除一个znode节点, 参数:路径、版本号;如果版本号与znode不一致,将无法删除,是一种乐观加锁机制;如果将版本号置为-1,不回去检测版本,直接删除 |
| Stat exists(final String path, Watcher watcher) | 判断某个znode节点是否存在 参数:路径、Watcher(监视器);当这个znode节点呗改变时,将会触发当前Watcher |
| Stat exists(String path, boolean watch) | 判断某个znode节点是否存在 参数:路径、并设置是否监控这个目录节点,这里的watcher是在创建ZooKeeper实例时指定的watcher |
| Stat setData(final String path, byte data[], int version) | 设置某个znode上的数据 参数:路径、数据、版本号;如果为-1,跳过版本检查 |
| byte[] getData(final String path, Watcher watcher, Stat stat) | 获取某个znode上的数据 参数:路径、监视器、数据版本等信息 |
| List getChildren(final String path, Watcher watcher) | 获取某个节点下的所有子节点 参数:路径、监视器;该方法有多个重载 |
Znode创建类型(CreateMode)
PERSISTENT 持久化节点
PERSISTENT_SEQUENTIAL 顺序自动编号持久化节点,这种节点会更具当前已存在的节点数自动加1
EPHEMERAL 临时节点,客户端session超时就会自动删除
EPHEMERAL_SEQUENTIAL 临时自动编号节点
Zookeeper基本操作:
public class ZooKeeperTest {
privateZooKeeper zookeeper;
/**
* 连接zookeeper
* @throws Exception
*/
@Before
public void setUp() throws Exception {
StringconStr = "service.bigdata.jack.cn:2181";
int sessionTimeout =30000;
zookeeper = new ZooKeeper(conStr, sessionTimeout , new Watcher() {
@Override
public voidprocess(WatchedEvent event) {
System.out.println("已经触发了" + event.getType()+ "事件!");
}
});
}
@Test
public void testCRUD() throws Exception {
// 创建一个目录节点
zookeeper.create("/testZK", "testZKData".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 创建一个子目录节点
zookeeper.create("/testZK/childOne", "childOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new
String(zookeeper.getData("/testZK",false,null)));
// 取出子目录节点列表
System.out.println(zookeeper.getChildren("/testZK",true));
// 修改子目录节点数据
zookeeper.setData("/testZK/childOne","modifyChildDataOne".getBytes(),-1);
System.out.println("目录节点状态:
["+zookeeper.exists("/testZK",true)+"]");
// 创建另外一个子目录节点
zookeeper.create("/testZK/childTwo", "childTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new
String(zookeeper.getData("/testZK/childTwo",true,null)));
// 删除子目录节点
zookeeper.delete("/testZK/childTwo",-1);
zookeeper.delete("/testZK/childOne",-1);
// 删除父目录节点
zookeeper.delete("/testZK",-1);
}
@After
public void cleanUp() throwsInterruptedException {
zookeeper.close();
}
}
输出结果如下:
已经触发了None事件!
testZKData
[childOne]
目录节点状态:[73,73,1474613743218,1474613743218,0,1,0,0,10,1,74
]
已经触发了NodeChildrenChanged事件!
childTwo
已经触发了NodeDeleted事件!
已经触发了NodeDeleted事件!
当对目录节点监控状态打开时,一旦目录节点的状态发生变化,Watcher对象的process方法就会被调用。
1.2.6. ZooKeeper典型应用场景
ZooKeeper从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,ZooKeeper就讲负责通知已经在ZooKeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。
下面详细介绍一下这些典型的应用场景,也就是ZooKeeper到底能帮我们解决什么问题呢?
1.2.6.1. 统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用于树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,即对人友好又不会重复。有点类似JNDI(Java Naming and DirectoryInterface,Java命名和目录接口,一个简单的例子就是通过配置一些xml文件,方便用户直接调用API使用某些通用的资源,如jdbc,tomcat配置),他们都是将有层次的目录结构关联到一定资源上,但是ZooKeeper的Name Service更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复的名称,就像数据库中产生一个唯一的主键一样。
1.2.6.2. 配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台PC Server运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给ZooKeeper来管理,将配置信息保存在ZooKeeper的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到ZooKeeper的通知,然后从Zookeeper获取新的配置信息引用到系统中。
图:ZooKeeper配置管理结构图
1.2.6.3. 集群管理(Group Membership)
ZooKeeper能够很容易的实现集群管理的功能,如有多台Server组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器状态,一旦有机器不能提供服务,集群中其它机器必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力是,就会增加一台或多台Server,同样也必须让“总管”知道。
ZooKeeper不仅能够帮你维护当前的集群中的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是ZooKeeper的另一个功能Leader Election。
他们的实现方式都是在ZooKeeper上创建一个EPHEMERAL类型的目录节点,然后每个Server在他们创建目录节点的父目录节点上调用getChildren(String path, boolean watch)方法并设置watch为true,由于是EPHEMERAL目录节点,当创建她的Server死去,这个目录节点也随之被删除,所以Children将会变化,这时getChildren上的Watch将会被调用,所以气他Server就知道已经有某台Server死去了。新增Server也是同样的道理。
ZooKeeper如何实现Leader Election,也就是选出一个Master Server。和前面的一样每台Server创建一个EPHEMERAL目录节点,不同的是它还是一个SEQUENTIAL目录节点,所以它是个EPHEMEAL_SEQUENTIAL目录节点。之所以它是EPHEMERAL_SEQUENTIAL目录节点,是因为我们可以给每台Server编号,我们可以选择当前是最小编号的Server为Master,加入这个最小编号的Server死去,由于是EPHEMERAL节点,死去的Server对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前Master。这样就实现了动态选择Master,避免了传统意义上单Master容易出现单点故障的问题。
集群管理结构图:
Leader Election关键代码
1.2.6.4. 队列管理
ZooKeeper可以处理两种类型的队列:
1、当一个队列的成员都聚齐是,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
2、队列按照FIFO方式进行入队和出队操作,列入实现生产者和消费者模型。
同步队列用ZooKeeper实现的思路如下:
创建一个父目录/synchronizing,每个成员都监控标志(Set Watch)位目录/synchronizing/start是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建/synchronizing/member_i的临时目录节点,然后每个成员获取/synchronizing目录的所有目录节点,也就是member_i。判断i的值是否已经是成员的个数,如果小于成员个数等待/synchronizing/start的出现,如果已经相等就创建/synchronizing/start。
以下是流程图:
同步队列的关键代码如下,
当对列没满是进入wait(),然后会一直等待Watch的通知,Watch的代码如下:
FIFO队列用ZooKeeper实现思路如下:
就是在特定的目录下创建SEQUENTIAL类型的子目录/queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过getChildren()方法可以返回当前所有的队列中的元素,然后先飞其中最小的一个,这样就能保证FIFO。
下面是生产者和消费者这种队列形式的示例代码。
生产者代码
消费者代码















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









