






文章目录
- 每日一题
- hot100题
- 1. 两数之和
- 2. 两数相加
- 3. 无重复字符的最长子串
- 4. 寻找两个正序数组的中位数
- 5. 最长回文子串
- 11. 盛最多水的容器
- 15. 三数之和
- 17. 电话号码的字母组合
- 19. 删除链表的倒数第 N 个结点
- 20. 有效的括号
- 21. 合并两个有序链表
- 22. 括号生成
- 23. 合并 K 个升序链表
- 31. 下一个排列
- 32. 最长有效括号
- 39. 组合总和
- 33. 搜索旋转排序数组
- 153. 寻找旋转排序数组中的最小值
- 34. 在排序数组中查找元素的第一个和最后一个位置
- 42. 接雨水
- 46. 全排列
- 48. 旋转图像
- 49. 字母异位词分组
- 53. 最大子数组和
- 55. 跳跃游戏
- 56. 合并区间
- 62. 不同路径
- 64. 最小路径和
- 70. 爬楼梯
- 75. 颜色分类
- 75. 颜色分类
- 78. 子集
- 79. 单词搜索
- 94. 二叉树的中序遍历 (TreeNode工具类)
- 96. 不同的二叉搜索树
- 98. 验证二叉搜索树
- 101. 对称二叉树
- 102. 二叉树的层序遍历
- 104. 二叉树的最大深度
- 105. 从前序与中序遍历序列构造二叉树
- 114. 二叉树展开为链表
- 121. 买卖股票的最佳时机
- 128. 最长连续序列
- 136. 只出现一次的数字
- 139. 单词拆分
- 141. 环形链表
- 142. 环形链表 II
- 146. LRU 缓存 ★
- 148. 排序链表 ▲
- 152. 乘积最大子数组
- 155. 最小栈
- 160. 相交链表
- 169. 多数元素
- 198. 打家劫舍
每日一题
1630. 等差子数组
- 先直接暴力,过了再说
public List<Boolean> checkArithmeticSubarrays(int[] nums, int[] l, int[] r) {
ArrayList<Boolean> ans = new ArrayList<>();
for(int i=0;i<l.length;i++){
int[] arrs = Arrays.copyOfRange(nums, l[i], r[i]+1);
Arrays.sort(arrs);
int j=1;
while (arrs.length>1&&j<arrs.length){
if (arrs[j] - arrs[j -1] != arrs[1] - arrs[0]) {
ans.add(false);
break;
}
j++;
}
if(j==arrs.length) ans.add(true);
}
return ans;
}
- 再追求效率
高效率的做法
一次遍历找到最大最小值 那么公差 d = (max-min)/(len-1) 不能整除直接return false
然后再遍历,第i项 a[i] = a[0]+id 不如就算出来i=(a[i]-a[0])/d 若不能整除false 或者出现重复i false Hash[d]记录是否1~d都出现过 真是等差一定会0~len-1各出现一次的
哇:两次遍历2O(n)+一个O(n)空间的数组就OK了,完全不需要排序
public List<Boolean> checkArithmeticSubarrays(int[] nums, int[] l, int[] r) {
ArrayList<Boolean> ans = new ArrayList<>();
int[] Hash = new int[nums.length];
for (int i = 0; i < l.length; i++) {
Arrays.fill(Hash, 0);
int min = Integer.MAX_VALUE, max = Integer.MIN_VALUE;
for (int j = l[i]; j <= r[i]; j++) {
min = Math.min(min, nums[j]);
max = Math.max(max, nums[j]);
}
if ((max - min) % (r[i] - l[i]) != 0) {
ans.add(false);
} else if (max == min) {//所有数字都一样
ans.add(true);
} else {
int d = (max - min) / (r[i] - l[i]);
boolean flag = true;
for (int j = l[i]; j <= r[i]; j++) {
if((nums[j]-min)%d!=0) {//注意这里也得判断
flag = false;
break;
}
int t = (nums[j] - min) / d;
if (Hash[t] == 1) {//等差数列一定每个都一份的 否则一定会有重复
flag = false;
break;
} else Hash[t] = 1;
}
ans.add(flag);
}
}
return ans;
}
hot100题
1. 两数之和
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> map = new HashMap<>();//存放元素下表
for (int i = 0; i < nums.length; i++) {
if(map.containsKey(target-nums[i])){//map.containsKey()时间复杂度是O(1) !!放心大胆用
return new int[]{i,map.get(target-nums[i])};
}
map.put(nums[i],i);//记录下标
}
return null;
}
知识点:java map.containsKey()时间复杂度是O(1), 访问大胆用即可
用map做Hash,简直不要太爽
2. 两数相加
节点个数100,一眼大数,自己再写一次大数吧。确实很简单的大数
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode zero = new ListNode(0);
ListNode head = new ListNode(-1);//头结点使得操作统一
ListNode tail = head;
int carry = 0;
while (l1 != null || l2 != null) {
if (l1 == null) l1 = zero;
if (l2 == null) l2 = zero;
//System.out.println(l1.val+" "+l2.val);
tail.next = new ListNode((l1.val + l2.val + carry) % 10);
tail = tail.next;
carry = (l1.val + l2.val + carry) / 10;
l1 = l1.next;
l2 = l2.next;
}
if (carry!=0){
tail.next = new ListNode(carry);
}
return head.next;
}
3. 无重复字符的最长子串
剑指里好像刷过这题,好像就是dp+Hash, 直接上
public int lengthOfLongestSubstring(String s) {
int max = 0;
int l = 0,r = 0;//首尾双指针 多好 (子串一定是连续的呀)
int[] Hash = new int[128];//ASCII只有128个
char[] chars = s.toCharArray();//习惯用数组
for (r = 0; r < chars.length; r++) {
while (Hash[chars[r]]>0){
Hash[chars[l++]]--;
}
Hash[chars[r]]++;
max = Math.max(max,r-l+1);
}
return max;
}
果然是做过,一点难度没有觉察到
但是看题解发现了java的HashSet专门用来判重
(HashSet底层就是HashMap,也就是专门的Hash表去了下重复,所以contains方法也是O(1) 直接看源码就map.containsKey(o))
public int lengthOfLongestSubstring(String s) {
int max = 0;
int l = 0,r = 0;//首尾双指针 多好 (子串一定是连续的呀)
HashSet<Character> set = new HashSet<>();
char[] chars = s.toCharArray();//习惯用数组
for (r = 0; r < chars.length; r++) {
while (set.contains(chars[r])){
set.remove(chars[l++]);//remove应该也是O(1) Hash表嘛 都是O(1)
}
set.add(chars[r]);
max = Math.max(max,r-l+1);
}
return max;
}
确实好用~
4. 寻找两个正序数组的中位数
先牺牲空间归并一下,时间完全满足O(m+n),这也能过,太水了~ 还hard
public class LC4 {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int[] ans = new int[nums1.length + nums2.length];
int k = 0;
int i = 0, j = 0;
while (i < nums1.length && j < nums2.length) {
if(nums1[i]<nums2[j]){
ans[k++]=nums1[i];
i++;
}else {
ans[k++]=nums2[j];
j++;
}
}
while (i<nums1.length) ans[k++] = nums1[i++];
while (j<nums2.length) ans[k++] = nums2[j++];
/*if(k%2==1) return ans[k/2];
return (ans[k/2]+ans[k/2-1])/2.0;*/
//小trick
return (ans[(k-1)/2]+ans[k/2])/2.0;
}
public static void main(String[] args) {
test(new int[]{1,3},new int[]{2});
test(new int[]{1,2},new int[]{3,4});
test(new int[]{1,3},new int[]{2,3,4,5});//1 2 3 3 4 5
}
static void test(int[] A,int[] B){
LC4 t = new LC4();
double ans = t.findMedianSortedArrays(A, B);
System.out.println(ans);
}
}
- 空间限制O(1) 才能算hard
先想到不存储,直接找到第(l1+l2)/2旁边就截止,不就将空间省下来了吗,没想到边界竟然这么麻烦
还是在用到了奇偶都可以用 (ans[(k-1)/2]+ans[k/2]) /2.0 得到中位数的trick
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int n = nums1.length + nums2.length;
int m1 = (n - 1) / 2;
int m2 = n / 2;
int k = 0, ans1 = 0, ans2 = 0;
//不管奇偶 找这个两个取平均即可
int i1 = 0, i2 = 0;
while (i1 < nums1.length && i2 < nums2.length) {
if(nums1[i1] < nums2[i2]) {
if (k == m1) {
ans1 = nums1[i1];
}
if (k == m2) {
ans2 = nums1[i1];
return (ans1 + ans2) / 2.0;
}
i1++;
k++;
} else {
if (k == m1) {
ans1 = nums2[i2];
}
if (k == m2) {
ans2 = nums2[i2];
return (ans1 + ans2) / 2.0;
}
i2++;
k++;
}
}
while (i1 < nums1.length) {
if (k == m1) {
ans1 = nums1[i1];
}
if (k == m2) {
ans2 = nums1[i1];
return (ans1 + ans2) / 2.0;
}
i1++;
k++;
}
while (i2 < nums2.length) {
if (k == m1) {
ans1 = nums2[i2];
}
if (k == m2) {
ans2 = nums2[i2];
return (ans1 + ans2) / 2.0;
}
i2++;
k++;
}
return -1;
}
- 看题解 简化代码
trick:
总长度 n = l1 + l2
奇数: k/2
偶数:k/2和(k-1)/2
都遍历到下标 k/2
或者 都 k/2和(k-1)/2取平均 (奇数时二者相等 就自然统一了)
或者直接记录pre和now即可
if (n1 < l1 && nums1[n1] < nums2[n2])改成if (n1 < l1 && (n2>=l2|| nums1[n1] < nums2[n2]))
另一个越界了也是我+,小技巧,省了大代码
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int l1 = nums1.length;
int l2 = nums2.length;
int len = l1 + l2;
int n1 = 0, n2 = 0;//
int pre = 0, now = 0;//记录上次的结果
int T = len / 2 +1 ;//找到这就够了 下标len/2,但其实是(len/2)+1多个
while (T-- > 0) {
pre = now;
if (n1 < l1 && (n2>=l2|| nums1[n1] < nums2[n2])) {//nums2越界了也是我+ k2>=l2写前面短路,否则nums2[k2]会越界
now = nums1[n1++];
}else {
now=nums2[n2++];//不用想 肯定走这边 (只有2种逻辑可以走)
}
}
if((len&1)==1) return now;//奇数
return (now+pre)/2.0;
}
5. 最长回文子串
- 先用最简单的dp做一下,先通过再说
public String longestPalindrome(String s) {
char[] arr = s.toCharArray();
int l = arr.length;
int[][] dp = new int[l][l];
int start=0,maxl=1;//维护一个起始下标和长度作为最终结果返回
for (int i = 0; i < dp.length; i++) {
dp[i][i]=1;//长度为1
if(i>0&&arr[i]==arr[i-1]) {
dp[i-1][i]=1;//长度为2 千万注意i<j i-1写到前面 因为我们维护的是起始下标和长度
start=i-1;//i-1不是i 小细节害死人
maxl=2;
}
}
for(int len =2;len<l;len++ ){//长度为3开始遍历 [i,i+len]长度为len+1
for (int i = 0; i+len < l; i++) {
int j = i+len;
if(arr[i]==arr[j]) dp[i][j] = dp[i+1][j-1];
else dp[i][j]=0;//直接就是0 不是回文子串
if(dp[i][j]==1&&len+1>maxl){//len+1才是实际长度
maxl=len+1;
start=i;
}
}
}
return new String(arr,start,maxl);//直接取数组部分初始化为String
}
代码有点长,想优化一下,总感觉优化了个寂寞:
//感觉代码有点长 休整一下
public String longestPalindrome(String s) {
char[] arr = s.toCharArray();
int l = arr.length;
boolean[][] dp = new boolean[l][l];
for (int i = 0; i < dp.length; i++) dp[i][i] = true;//长度为1
int start = 0, maxl = 1;//维护一个起始下标和长度作为最终结果返回
for (int len = 2; len <= l; len++) {//长度真的从2开始遍历
for (int i = 0; i + len - 1 < l; i++) {
int j = i + len - 1;//[i,i+len-1] 长度正好是len
if (arr[i] != arr[j]) dp[i][j] = false;//非回文子串
else if (len == 2) dp[i][j] = true;//长度为2的边界
else dp[i][j] = dp[i + 1][j - 1];
if (dp[i][j] && len > maxl) {//len+1才是实际长度
maxl = len;
start = i;
}
}
}
//return new String(arr, start, maxl);//直接取数组部分初始化为String
return s.substring(start, start + maxl);//参数竟然是首尾下标
}
时间O(n^2) , 空间O(n^2)
接下来就是老老实实看题解,一步一步发掘最优解了
- 方法二:中心扩展算法

此法,时间还是O(n^2),但是空间变成O(1)了
注意回文中心有两种,长度为1或者长度为2
长度为1如: a => bab 也就是奇数子串
长度为2如: aa=> baab 也就是偶数子串
所以得以回文中心为下标专门写一个扩散函数
我的写法:
public String longestPalindrome(String s) {
char[] arr = s.toCharArray();
int l = arr.length;
int begin = 0, maxl = 1;
for (int i = 0; i < l - 1; i++) {
Integer[] ok1 = expandAroundCenter(i,i,arr);
Integer[] ok2 = expandAroundCenter(i,i+1,arr);
if(ok1!=null&&ok1[1]-ok1[0]+1>maxl){
maxl = ok1[1] - ok1[0]+1;
begin = ok1[0];
}
if(ok2!=null&&ok2[1]-ok2[0]+1>maxl){
maxl = ok2[1] - ok2[0]+1;
begin = ok2[0];
}
}
return s.substring(begin, begin + maxl);//参数竟然是首尾下标 当然还是左闭右开
}
public Integer[] expandAroundCenter(int i, int j, char[] arr) {
int k = 0;
while (i - k >= 0 && j + k < arr.length && arr[i-k]==arr[j+k]) k++;
k--;
Integer[] ans = null;
if(k>-1) ans = new Integer[]{i-k,j+k};//返回首尾下标
return ans;
}
题解写法:
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) {
return "";
}
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
//★ 奇偶奇迹般地统一了 i=1 aaaa和aaab 举例验证 是正确的
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
public int expandAroundCenter(String s, int left, int right) {
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
--left;
++right;
}
return right - left - 1;//(right-1)-(left+1)+1
}
巧妙之处在于,不管结果是奇数还是长偶数长,都给你一个式子统一了:
start = i - (len - 1) / 2;
end = i + len / 2;
eg: i=1 “aaaa”
expandAroundCenter(1,1) => 3
expandAroundCenter(1,2) => 4
len取4 此时 :
start = i - (len - 1) / 2 = 1 - 3/2 = 0
end = i + len / 2 = 1+4/2 = 3
正确
eg: i=1 “aaab”
expandAroundCenter(1,1) => 3
expandAroundCenter(1,2) => 2
len取3 此时 :
start = i - (len - 1) / 2 = 1 - 2/2 = 0
end = i + len / 2 = 1+3/2 = 2
正确
理解:
start = i - (len - 1) / 2; //i左偏了 所以 (len-1)
end = i + len / 2; //右边正常
//然后举例论证 2个不同的例子(1奇1偶)能正确 基本全局都正确了

时间紧迫,不看了
11. 盛最多水的容器
面积 = 两个指针指向的数字中较小值∗指针之间的距离
如果我们移动数字较大的那个指针,那么前者「两个指针指向的数字中较小值」不会增加,后者「指针之间的距离」会减小,那么这个乘积会减小。
所以在首尾指针的情况下,让短板变长是我们的目标
本题直接暴力会超时
public int maxArea(int[] height) {
int max = 0;
int i=0,j=height.length-1;
while (i<j){
max = Math.max(max,(j-i)*Math.min(height[i],height[j]));
if(height[i]<height[j]) i++;
else j--;
}
return max;
}
下面这么写,效率会高点:
public int maxArea(int[] height) {
int max = 0;
int i=0,j=height.length-1;
while (i<j){
if(height[i]<height[j]){
max = Math.max(max,(j-i)*height[i]);
i++;
}else {
max = Math.max(max,(j-i)*height[j]);
j--;
}
}
return max;
}
15. 三数之和
直接暴力,O(n3)肯定超时,就先用Hash降为O(n2) 试试。
注意陷阱,不注重顺序必然意味着即使下标不同,但是无序3元组相同,只能算同一个。
i<j<k 可以保证下标不重复出现,但是值相同避免不了,得用Set去重
public List<List<Integer>> threeSum(int[] nums) {
// 直接用set去重试试
Set<List<Integer>> set = new HashSet<>();
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
map.put(nums[i],i);
}
for (int i = 0; i < nums.length; i++) {
for (int j = i+1; j < nums.length; j++) {
int x = -(nums[i]+nums[j]);
if(map.containsKey(x)){
Integer k = map.get(x);
if(k>j){//强制按从小到大顺序即可保证不重复
ArrayList<Integer> list = new ArrayList<>();
list.add(nums[i]);list.add(nums[j]);list.add(nums[k]);
Collections.sort(list);//排序好去重
set.add(list);
}
}
}
}
List<List<Integer>> ans = new ArrayList<>();
for (List<Integer> list : set) {
ans.add(list);
}
return ans;
}
看了下题解,不错,主要是节省了空间。时间还是一样的。
17. 电话号码的字母组合
很简单的排列问题,但是循环实在不会写,难道要写8个循环,太麻烦了吧,突然想到递归,代码确实好写多了。
String[] mp = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
String digits= "";
ArrayList<String> ans = new ArrayList<>();
public List<String> letterCombinations(String digits) {
this.digits = digits;
if(digits==null||"".equals(digits)) return ans;
dfs(0,"");
return ans;
}
void dfs(int i,String s){
if(i==digits.length()) {
ans.add(s);
return;
}
int x = digits.charAt(i)-'0';
for (int j = 0; j < mp[x].length(); j++) {
char c = mp[x].charAt(j);
dfs(i+1,s + String.valueOf(c));
}
}
答案也是递归,思路不错!
19. 删除链表的倒数第 N 个结点
19. 删除链表的倒数第 N 个结点
经典老题了,双指针最优:
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode p=head,q=head;
while (n-- >0&&p!=null) p=p.next;
if(p==null){
if(n>1) return null;//n比总长度还要大
else {//正好删除首结点
return head.next;
}
}
while (p.next!=null){
p=p.next;
q=q.next;
}
q.next=q.next.next;
return head;
}
20. 有效的括号
纯粹水题:
char match(char c){
if(c==')') return '(';
if(c==']') return '[';
if(c=='}') return '{';
return '*';
}
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if(c=='('||c=='['||c=='{') stack.push(c);
else {//右括号
if(stack.empty()||match(c)!=stack.pop()) return false;
}
}
return stack.empty();//用empty比我们自己判断stack.size()==0 要快1ms
}
用empty比我们自己判断stack.size()==0 要快1ms
所以尽量用人家的API,效率比自己写的确实要高
21. 合并两个有序链表
水题
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if (list1 == null) return list2;
if (list2 == null) return list1;
ListNode head = new ListNode(-1);
ListNode tail = head;//头结点
while (list1 != null || list2 != null) {
// 注意这个判断的写法 节省了不少代码
if (list2 == null || (list1!=null && list1.val < list2.val)) {
tail.next = list1;
list1 = list1.next;
tail = tail.next;
} else {//只有两种分支 不必多想 上面的判断写好即可
tail.next = list2;
list2 = list2.next;
tail = tail.next;
}
}
return head.next;//去掉头结点
}
递归看着很有意思,写写看(实际开发,肯定不能写这种难读的代码)
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if(list1==null) return list2;
if(list2==null) return list1;
if(list1.val<list2.val) {
list1.next=mergeTwoLists(list1.next,list2);//难点
return list1;
}else {
list2.next = mergeTwoLists(list1,list2.next);
return list2;
}
}
空间肯定不如上面啦~
22. 括号生成
本题只有一种括号,所以只要左括号数量等于右括号数,且所有前缀都满足左括号数>=右括号数,就一定是合法的,别想复杂了
清楚了这个简单的判定合法规则,接下来就可以用最简单的暴力法试试了
// 暴力法
Integer n =0;
List<String> ans = new ArrayList<String>();
public List<String> generateParenthesis(int n) {
this.n = 2*n;
GeneratePair("");
return ans;
}
void GeneratePair(String pair){
if(pair.length()==n){
if(valid(pair)) ans.add(pair);
return;
}
GeneratePair(pair+"(");
GeneratePair(pair+")");
}
private boolean valid(String pair) {
int balance=0;//当前前缀: 左括号数-右括号数
for (int i = 0; i < pair.length(); i++) {
char c = pair.charAt(i);
if(c=='(') balance++;
else balance--;
if(balance<0) return false;
}
return balance==0;//左右括号数要一样多
}
- 其实上面的方法,可以很容易优化
递归过程中就可以维护左右括号数量了,左<=n, 右<=左 才去递归,大量减枝了,没有多余的递归了
// 剪枝
Integer n =0;
List<String> ans = new ArrayList<String>();
public List<String> generateParenthesis(int n) {
this.n = n;
GeneratePair("",0,0);
return ans;
}
// 改进 递归时就可以判断前缀是否合法了呀
void GeneratePair(String pair,int left,int right){
if(pair.length()==2*n){
ans.add(pair);
return;
}
if(left+1<=n) GeneratePair(pair+"(",left+1,right);
if(right+1<=left) GeneratePair(pair+")",left,right+1);
}
23. 合并 K 个升序链表
- 先多路归并试试
public class LC23 {
public ListNode mergeKLists(ListNode[] lists) {
if(lists.length == 0) return null;
ListNode head = new ListNode(-1);
ListNode tail = head;
while (true){
int min = 0;
for (int i = 1; i < lists.length; i++) {
if(lists[i]!=null){
if(lists[min]==null||lists[i].val<lists[min].val) min = i;
}
}
if (lists[min]==null) break;
tail.next = lists[min];
tail = tail.next;
lists[min] = lists[min].next;
}
return head.next;
}
public static void main(String[] args) {
test("1,4,5","1,3,4","2,6");
test("");
}
public static void test(String... strs){
ListNode[] lists = new ListNode[strs.length];
for (int i = 0; i < strs.length; i++) {
lists[i] = ListNode.create(strs[i]);
}
LC23 t = new LC23();
ListNode ans = t.mergeKLists(lists);
if(ans==null) System.out.println("null");
else ans.show();
}
}
package cn.whu.leetcode.utils;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public class ListNode {
public int val;
public ListNode next;
public ListNode() {
}
public ListNode(int val) {
this.val = val;
}
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
//根据数组初始化一个链表 当前对象为链表头
public ListNode(int[] vals){
this.val = vals[0];
ListNode tail = this;
for (int i = 1; i < vals.length; i++) {
tail.next = new ListNode(vals[i]);
tail = tail.next;
}
}
public ListNode(Queue<Integer> vals){
this.val = vals.poll();
ListNode tail = this;
while (!vals.isEmpty()){
tail.next = new ListNode(vals.poll());
tail = tail.next;
}
}
public static ListNode create(String strs){
if(strs==null||strs.trim().length()==0) return null;
String[] splits = strs.split(",");
Queue<Integer> q = new LinkedList<Integer>();
for (String s : splits) {
Integer i = Integer.parseInt(s);
q.offer(i);
}
return new ListNode(q);
}
public void show(){
ListNode p = this;
while (p!=null){
System.out.print(p.val+" ");
p = p.next;
}
System.out.println();
}
}
- 找最值,用优先队列啊
public ListNode mergeKLists(ListNode[] lists) {
ListNode head = new ListNode(-1);//加头结点 代码好写
ListNode tail = head;
// 优先队列 快多了
PriorityQueue<ListNode> Q = new PriorityQueue<>(((o1, o2) -> o1.val - o2.val));
// 头入队
for (ListNode headNode : lists) {
if(headNode!=null) Q.offer(headNode);
}
while (!Q.isEmpty()){
ListNode node = Q.poll();
tail.next = node;
tail = tail.next;
if(node.next!=null) Q.offer(node.next);//该条队列下一个入队
}
return head.next;
}
优先队列比我们每次都一个个地找快多了(堆和普通线性表的差别)

- 分治法用归并排序的思想进行两两合并,合并次数变logN了。觉得没有优先队列好。不写了
31. 下一个排列
- c++不是有现成的API吗? 先直接试试
void nextPermutation(vector<int>& nums) {
next_permutation(nums.begin(),nums.end());
}
果然直接就通过了
那么这题的含义应该就是让你自己实现next_permutation,也就自己递归写全排列喽。又回到了算法笔记基础知识点了。
- 自己直接实现 next_permutation , 就是c++ STL的算法思想,支持重复
自己写全排列太麻烦了,而且数字有重复,很麻烦,还是直接实现next_permutaton吧

// 半小时没想出来 直接暴力 不要浪费时间 新知识点 看一遍就会了 原创太难了 刷题的意义也是学习
public void nextPermutation(int[] nums) {
boolean flag = false;
for (int i = nums.length - 1; i > 0; i--) {
if(nums[i-1]<nums[i]){
flag = true;
// 从后往前找第一个比nums[i-1]大的 (nums[i-1]可能排在i~end中间)
int j = nums.length-1;
while (nums[j]<=nums[i-1]) j--; //注意==也不行
int t = nums[j];
nums[j]=nums[i-1];
nums[i-1] = t;
// i~end再逆置即可 排序代替逆置
Arrays.sort(nums,i,nums.length);//注意下标范围左闭右开
break;//立刻结束
}
}
if(!flag){
// 全部逆置 (排序代替逆置)
Arrays.sort(nums);
}
}
上面偷懒,逆置直接排序了(因为知道一定是倒序,不必排序,直接逆置即可)
整理一下,逆置也自己写,不直接用排序了
// 半小时没想出来 直接暴力 不要浪费时间 新知识点 看一遍就会了 原创太难了 刷题的意义也是学习
public void nextPermutation(int[] nums) {
boolean flag = false;
for (int i = nums.length - 1; i > 0; i--) {
if(nums[i-1]<nums[i]){
flag = true;
// 从后往前找第一个比nums[i-1]大的 (nums[i-1]可能排在i~end中间)
int j = nums.length-1;
while (nums[j]<=nums[i-1]) j--; //注意==也不行
swap(nums,i-1,j);//交换后面最小的元素
// i~end再逆置即可 排序代替逆置
reverse(nums,i,nums.length-1);//自己写得 下标范围就是[i,j] 左闭右闭
break;//立刻结束
}
}
if(!flag){
// 整个序列都是逆序的 全体逆置
reverse(nums,0,nums.length-1);
}
}
void swap(int[] nums,int i,int j){
int t=nums[i];
nums[i]=nums[j];
nums[j]=t;
}
void reverse(int[] nums,int i,int j){//逆置i~j
while (i<j){
swap(nums,i,j);
i++;j--;
}
}

32. 最长有效括号
之前做过2个hard,太打击自信了,现在遇到hard,有巧方法就用巧方法过了再说,没有巧法,那就思考5min,没思路,直接看题解了。
- 方法1:dp, 我感觉这个状态转移方程我是想不出来的,还好没有硬上
用自己的话写一遍,再贴人家的吧:
dp[i] 表示以下标i为结尾的最长合法串长度,合法串必须包含s[i]且以其为结尾。
那么初始化 s[i]=='(' dp[i]=0
状态转移:
s[i]==’(‘ dp[i]=0s[i]==')'
2.1.s[i-1]=='(' dp[i] = dp[i-2]+2
2.2.s[i-1]==')'此时得s[i-1-dp[i-1]]=='('=>dp[i] = dp[i-1-dp[i-1]-1] + dp[i-1]+2
dp[i-1-dp[i-1]-1]很细节()(())完全因为连续的((((将前面忽略了 断链了 很细节


开头填充一个字符,逻辑简单多了:
public int longestValidParentheses(String s) {
s = " "+s;//开头填充一个用于占位
int[] dp = new int[s.length()];
int max = 0;
for(int i=1;i<dp.length;i++){//注意下标从1开始 0是填充符了
if(s.charAt(i)==')'){
if(s.charAt(i-1)=='(') dp[i]=dp[i-2]+2;
else{//s.charAt(i-1)==')'
if(s.charAt(i-dp[i-1]-1)=='(') dp[i]=dp[i-1]+2+dp[i-dp[i-1]-2];
}
}
max = Math.max(max,dp[i]);
}
return max;
}
不填充,加了很多判断,但是确实快一点
public int longestValidParentheses(String s) {
int[] dp = new int[s.length()+1];
int max = 0;
for(int i=1;i<s.length();i++){// 未填充也可以从1开始 因为dp[0]=0 一定成立 一对括号最短长度为2
if(s.charAt(i)==')'){
if(s.charAt(i-1)=='('){
if(i-2>=0) dp[i]=dp[i-2]+2;
else dp[i]=2;
}else{//s.charAt(i-1)==')'
if(i-dp[i-1]-1>=0&&s.charAt(i-dp[i-1]-1)=='(') {
if(i-dp[i-1]-2>=0) dp[i]=dp[i-1]+2+dp[i-dp[i-1]-2];
else dp[i]=dp[i-1]+2;
}
}
}
if(max<dp[i]) max=dp[i];
}
return max;
}
- 方法二:栈
思路也很牛,先明确,括号只有一种类型()。然后,入栈的是下标,不是字符

public int longestValidParentheses(String s) {
int max = 0;
Stack<Integer> st = new Stack<>();
st.push(-1);
for (int i = 0; i < s.length(); i++) {
if(s.charAt(i)=='(') st.push(i);
else {//s.charAt(i)==')'
st.pop();
if(!st.isEmpty()) {
max=Math.max(max,i-st.peek());
}else {
st.push(i);//无法匹配 我就是最后一个未匹配的右
}
}
}
return max;
}
39. 组合总和
DFS排列:每个元素可选0次,1次以及多次
public List<List<Integer>> combinationSum(int[] candidates, int target) {
//Arrays.sort(candidates);//注释了也能通过
this.candidates = candidates;
ans.clear();
comb(0,target,new ArrayList<Integer>());
return ans;
}
int[] candidates;
List<List<Integer>> ans = new ArrayList<>();
void comb(int k,int target,List<Integer> nums){
if(target==0){
ans.add(nums);
return;
}
// target后判断
if(k>=candidates.length) return;
//不选
comb(k+1,target,nums);
// 选一个或者多个
int t = target;
List<Integer> numst = new ArrayList<Integer>(nums);
while (t-candidates[k]>=0){
t -= candidates[k];// 本结点可以选多次
numst.add(candidates[k]);
comb(k+1,t,numst);
}
}
33. 搜索旋转排序数组
难点在于logN的时间复杂度
旋转之后的数据分为两个分别升序的部分,若能找到分割点(原来的a[0])那么在两部分分别进行两次二分查找,不就logN了
这个时候难点就在找分割点了,旋转次数是未知的,分割点也就未知,还得最高logN找分割点,这个时候题目转换成另外一个问题了。
做完下面的153,再来做本题,就很简单了。
public int search(int[] nums, int target) {
int min = findMin(nums),low=0,high=nums.length-1;
if(target>nums[high]) high = min-1; //左边
else low = min;
// 接下来 low和high里二分查找即可
while (low<=high){//加等号 可能正好相遇时相等呢
int mid = (low+high)/2;
if(nums[mid]==target) return mid;
else if(nums[mid]<target) low = mid+1;
else high = mid-1;
}
return -1;
}
// 153. 寻找旋转排序数组中的最小值 改成返回最小值下标
public int findMin(int[] nums) {
int low=0,high=nums.length-1;
while (low<high){ // 区间长度为1时结束二分
int mid = (low+high)/2;
if(nums[mid]>nums[high]) low = mid+1; //改成+1 low右偏,一定在high相遇
else high = mid;
// 元素互不相同 不会出现相等的情况
}
return high;
}
接下来不找中点,直接用找中点 时nums[high]的性质,判断是在左半段还是右半段,其实用nums[0]也可以判断出来,就用nums[0]吧,target>nums[0] 一定左半段 target<nums[0] 一定在右半段,相等就直接找到了。 其实就是两个方法合二为一了
- 利用性质直接二分
还是二分,但是每次判断3点
- nums[mid]和target 谁大 taregt小,下标变化要舍弃nums里一些偏大的元素, 否则舍弃nums里比较小的元素
- target在左边还是右边 =》 根据target和nums[0]大小可以判断 这会影响舍弃元素时下标变化的策略
- mid 在左边还是右边 =》 根据mid 和nums[0]大小可以判断 这会影响舍弃元素时下标变化的策略
合起来一共23-2 = 6 种情况 。 舍弃的两种是:
- nums[mid]<target<nums[0] : 也就是不会出现 nums[mid]<target,target右边时(target<nums[0]) ,mid在左边(mid>nums[0])
- nums[mid]>target>nums[0] : 也就是不会出现 nums[mid]>target,target左边时(target>nums[0]) ,mid在右边(mid<nums[0])
153. 寻找旋转排序数组中的最小值
不会,直接看题解,真的简单啊。简单分析一下,就会发现,
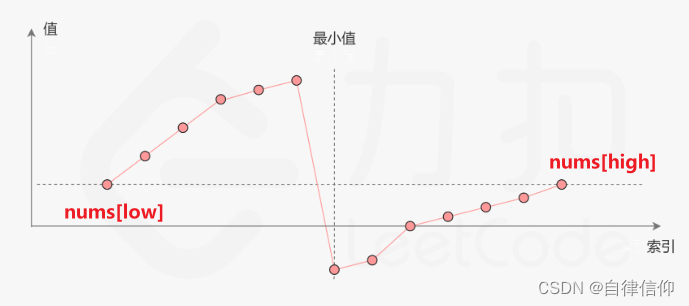
nums[high]有一个非常美的性质,取一个元素t, 若t<nums[high],一定在右半段,若t>nums[high],则一定在左半段。 中点 mid = (low+high)/2 ,中点值 nums[mid]必然也满足这个性质。
(“给你一个元素值 互不相同 的数组 nums” 数组元素互不相同)
mid在右半段,去掉其右边的:
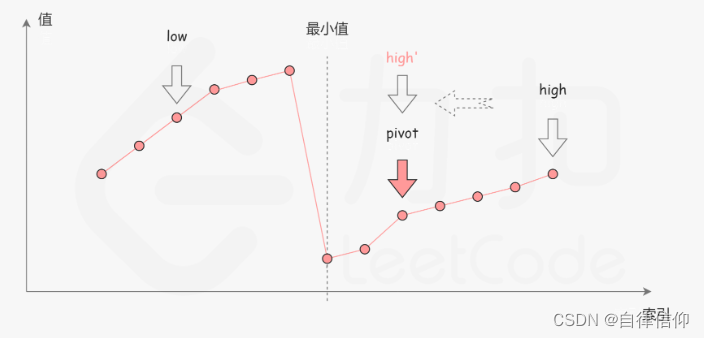
mid在左半段,去掉其左边的:
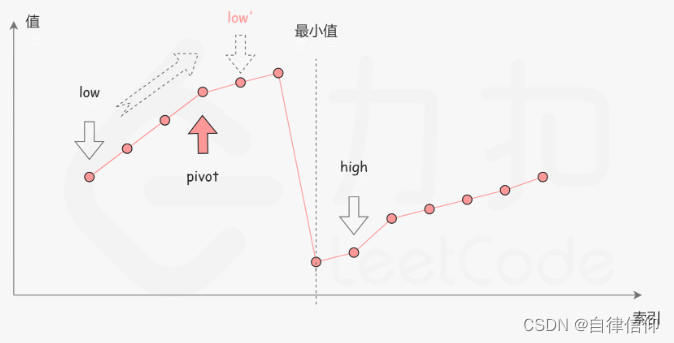
边界就自己举2个例子,一奇一偶,分别手算看看即可。初步分析,因为high在右边小的部分,
- 当然最简单的思路,最终只剩下两个元素时退出二分,取小的一个即可
public int findMin(int[] nums) {
int low=0,high=nums.length-1;
while (high-low>1){ // 区间长度为1时结束二分
int mid = (low+high)/2;
if(nums[mid]>nums[high]) low = mid;
else high = mid;
// 元素互不相同 不会出现相等的情况
}
return Math.min(nums[low],nums[high]); // 最后剩下两个 取一个最小的即可
}
真的要这么麻烦吗,为何要最后两个取最小,因为 mid = (low+high)/2 左偏了,最后一大一小时 会偏向小下标(大值)。而原本就有序时,左偏又是正确的。
那么让一大一小时,mid右偏不就行了,往右偏,最终相遇点一定偏小,(原本有序,肯定nums[0]相遇)
- mid = (low+high)/2+1 右偏即可
public int findMin(int[] nums) {
int low=0,high=nums.length-1;
while (low<high){ // 区间长度为1时结束二分
int mid = (low+high)/2;
if(nums[mid]>nums[high]) low = mid+1; //改成+1 low右偏,一定在high相遇
else high = mid;
// 元素互不相同 不会出现相等的情况
}
return nums[high];
}
34. 在排序数组中查找元素的第一个和最后一个位置
自己实现:lower_bound()和upper_bound()
可能有点难想,其实很简单,快快调试,会发现就那样很简单
注意下找不到要返回-1
public int[] searchRange(int[] nums, int target) {
int l = lower_bound(nums, target);
int r = upper_bound(nums, target);
if(l==-1) return new int[]{-1,-1};
return new int[]{l,r-1};
}
// 第一个 大于等于 target的
int lower_bound(int[] nums,int target){
int l = 0,r = nums.length-1;
boolean flag = false;
while (l<=r){
int mid = (l+r)/2;
if(nums[mid]>=target) r=mid-1;
else if(nums[mid]<target) l=mid+1;
if(nums[mid]==target) flag=true;
}
if(flag) return l;
return -1;
}
// 第一个 大于 target的
int upper_bound(int[] nums,int target){
int l = 0,r = nums.length-1;
while (l<=r){
int mid = (l+r)/2;
if(nums[mid]>target) r=mid-1;
else if(nums[mid]<=target) l=mid+1;
}
return l;
}
看了题解发现,两个方法可以合二为一,小tricks大大减少代码长度:
public int[] searchRange(int[] nums, int target) {
int l = lower_bound(nums, target,true);
int r = lower_bound(nums, target,false);
if(l>=0&&l<=nums.length-1&&nums[l]==target) return new int[]{l,r-1};
return new int[]{-1,-1};
}
// 和2为一: lower==true: 找第一个 大于等于 target的
// lower==false: 找第一个 大于 target的
int lower_bound(int[] nums,int target,boolean lower){
int l = 0,r = nums.length-1;
while (l<=r){
int mid = (l+r)/2;
if(nums[mid]>target||(lower&&nums[mid]==target)) r=mid-1;
else l=mid+1; //注意直接else (才会有动态逻辑 <或者<=)
}
return l;
}
42. 接雨水
- 【不通过】方法一,之前可能行,现在超时了,数据量最大值一大,就会很慢
public int trap(int[] height) {
int h = 1,ans=0;
while (true){
int l=-1,r=-1;
boolean flag = false;
for (int i = 0; i < height.length; i++) {
if(height[i]>=h){
flag = true;
if(l==-1) l=i;
else{
ans += (i-l-1);
l=i;
}
}
}
if(flag) h++;
else break;
}
return ans;
}
- 按列:
hard先放着吧,面试不大会问
46. 全排列
基础题,java版本API细节还是不大熟悉
public List<List<Integer>> permute(int[] nums) {
this.arr = new Integer[nums.length];
permutation(nums,0);
return ans;
}
Set<Integer> set = new HashSet<>();
List<List<Integer>> ans = new ArrayList<>();
Integer[] arr; //这里要Integer[] 不要int[] 否则一下API用不了 细节烦死人
List<List<Integer>> permutation(int[] nums, int n){//就用数组 arr[n]=nums[i]最方便 不需要remove 直接覆盖
if(n==nums.length){
ans.add(new ArrayList<>(Arrays.asList(arr)));//arr必须Integer[] 不能int
return ans;
}
for (int i = 0; i < nums.length; i++) {
if(!set.contains(i)){
set.add(i);//第n个选i
arr[n] = nums[i];
permutation(nums,n+1);
set.remove(i); //第n个不选i了
}
}
return ans;
}
48. 旋转图像
408考过类似的题,就很简单了,先每列逆置,再根据主对角线对称着逆置即可 (或者先每行逆置,再根据次对角线对称着逆置)
果然简单:
注意矩阵行列相等
// 数组就是指针传递 直接改数组就行了
public void rotate(int[][] matrix) {
int n = matrix.length; //矩阵一定是矩形 行列相等
// 每列原地逆置
for (int j = 0; j < n; j++) {
int l = 0, r = n - 1;
while (l<r){
swap(matrix,l,j,r,j);
l++;r--;
}
}
// 上下三角原地对称逆置
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
swap(matrix,i,j,j,i);
}
}
}
void swap(int[][] matrix, int a, int b, int x, int y) {
int t = matrix[a][b];
matrix[a][b] = matrix[x][y];
matrix[x][y] = t;
}
49. 字母异位词分组
太水了,直接暴力也能过:
Map<String,List<String>> mp = new HashMap<String,List<String>>();
public List<List<String>> groupAnagrams(String[] strs) {
for (String str : strs) {
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = new String(chars);
if(mp.containsKey(key)){
mp.get(key).add(str);
}else {
ArrayList<String> list = new ArrayList<>();
list.add(str);
mp.put(key,list);
}
}
List<List<String>> ans = new ArrayList<>();
for (String s : mp.keySet()) {
ans.add(mp.get(s));
}
return ans;
}
看了题解,跟我写法一样,但是人家代码写得比我清爽多了:
map.getOrDefault(getOrDefault(key, default)如果存在key, 则返回其对应的value, 否则返回给定的默认值default)
public List<List<String>> groupAnagrams(String[] strs) {
Map<String,List<String>> mp = new HashMap<String,List<String>>();
for (String str : strs) {
char[] chars = str.toCharArray();
Arrays.sort(chars);
String key = new String(chars);
List<String> list = mp.getOrDefault(key, new ArrayList<String>());
list.add(str);
mp.put(key,list);//无则添加 有则覆盖 就是Hash表
}
return new ArrayList<>(mp.values());
}
53. 最大子数组和
简单DP,但是长时间不写,还是生疏了
核心: dp[i-1]>0 就连上,否则dp[i]=nums[i]只取自己(必须至少取一个啊) 然后到i+1时若dp[i]<0不要就是喽
public int maxSubArray(int[] nums) {
int[] dp = new int[nums.length];
dp[0] = nums[0];
int max=dp[0];
for (int i = 1; i < nums.length; i++) {
/*if(dp[i-1]+nums[i]>nums[i]) dp[i] = dp[i-1]+nums[i];
else dp[i]=nums[i];*/
dp[i] = Math.max(dp[i-1]+nums[i],nums[i]); // 前面的和>0 加上 否则不加
max=Math.max(max,dp[i]);
}
return max;
}
很明显可以滚动来压缩空间,因为每次dp[i]都只是需要用到dp[i-1]
public int maxSubArray(int[] nums) {
int dp = nums[0],max=nums[0];
for (int i = 1; i < nums.length; i++) {
dp = Math.max(dp+nums[i],nums[i]); // 前面的和>0 加上 否则不加
max=Math.max(max,dp);
}
return max;
}
55. 跳跃游戏
public boolean canJump(int[] nums) {
if(nums.length<=1) return true;
// 能跨过0元素即可到达
for (int i = 0; i < nums.length; i++) {
if (nums[i] == 0) {
int j = i;
while (j-- > 0) {
if (nums[j] > i - j) break;
else if(nums[j]==i-j&&i==nums.length-1) break;//刚好到最后一个也行
}
if (j < 0) return false;
}
}
return true;
}
- 代码优化
其实最后一个元素不必判断,能跨过前n-1所有的0,肯定能跨过倒数第2个,也就一定能到最后一个
然后再语法层面做一些优化
public boolean canJump(int[] nums) {
// 能跨过0元素即可到达 (调试发现最后一个不必判断 能跨过前n-1所有的0 一定能到达最后)
for (int i = 0; i < nums.length-1; i++) {
if (nums[i] == 0) {
int j = i;
while (--j>=0 && nums[j]<=i-j);
if (j < 0) return false;
}
}
return true;
}
看题解发现一种特别简洁的做法,直接跳就行了,但是时间上慢了
直接跳就行了
能跳到nums[i]其左边的一定能到
每个元素都往最远的跳 都能跳就行
public boolean canJump(int[] nums) {
// 其实一直跳就行了
int k = 0;
for (int i = 0; i < nums.length; i++) {
if(i>k) return false;
k = Math.max(k,nums[i]+i);//每个元素都往最远的跳 都能跳就行 能跳到nums[i]其左边的一定能到
}
return true;
}
56. 合并区间
先直接贪心取一下
过了,就行了吧
public int[][] merge(int[][] intervals) {
// lambda表达式 指定按照第一维排序一级排序 第二维二级排序
ArrayList<int[]> list = new ArrayList<>();
Arrays.sort(intervals,(a1,a2)->a1[0]-a2[0]);
for (int i = 0; i < intervals.length; i++) {
int l = intervals[i][0],r=intervals[i][1];
while (i+1<intervals.length&&r>=intervals[i+1][0]){//注意是维护的当前最大右边界>=intervals[i+1][0]
r = Math.max(r,intervals[i+1][1]);//需要维护 不一定最后一个第二维就最大
i++;
}
list.add(new int[]{l,r});
}
int[][] ans = new int[list.size()][2];
for (int i = 0; i < list.size(); i++) {
ans[i] = list.get(i);
}
return ans;
}
62. 不同路径
- 方法1,直接用杨辉三角
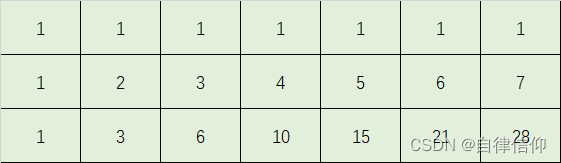
public int uniquePaths(int m, int n) {
int[][] path = new int[m + 1][n + 1];//外围填充一层0就不用判断边界了
for (int i = 1; i <=m ; i++) {
for (int j = 1; j <= n; j++) {
if(i==1&&j==1) path[i][j] = 1; //这个启始条件还是要有的
else path[i][j] = path[i-1][j]+path[i][j-1];
}
}
return path[m][n];
}
记得高中学排列组合时有个公式直接能算出来啊,去题解看看吧:
果然是有:

高中肯定会,读个大学,啥都忘了,唉~
总共移动(m-1)+(n-1)=m+n-2次 , 其中向下m-1次,向右n-1次,也就是m+n-2次中挑出m-1次向下,即: C m + n − 2 m − 1 C_{m+n-2}^{m-1} Cm+n−2m−1
或者m+n-2次中挑出n-1次向右,即: C m + n − 2 n − 1 C_{m+n-2}^{n-1} Cm+n−2n−1
这些细节还真的挺烦人:
1、 用long防止溢出
2、提前除以,防止溢出
3、m-1,n-1取其小者,防止溢出
4、Math.toIntExact(int) java Long->Int
public int uniquePaths(int m, int n) {
Long x=1l;
for(int i=0;i<Math.min(n-1,m-1);i++){//取小的一个 大的容易溢出
x *= (m+n-2-i);
x /= (i+1);
}
return Math.toIntExact(x);
}
- 其实还可以简化
基本类型 long和int是可以直接强行转换的,包装类型不行
public int uniquePaths(int m, int n) {
long ans = 1;
for(int i=0;i<Math.min(m,n)-1;i++){
ans = ans * (m+n-2-i)/(i+1);
}
return (int) ans;
}
64. 最小路径和
最先想到的是D/BFS,没想到都超时了,只能想想别的方法了
仔细想想,不也只是一个杨辉三角嘛,本着 有经验的dp不算dp 试了试
竟然过了
// D/BFS都超时了 不行 只能杨辉试试了 再不行就直接看题解去了
public int minPathSum(int[][] grid) {
int m = grid.length,n=grid[0].length;
int[][] dp = new int[m+1][n+1];
// 找最小 于是边界得填充上MAX_VALUE
for(int i=0;i<=m;i++) dp[i][0] = Integer.MAX_VALUE;
for(int j=0;j<=n;j++) dp[0][j] = Integer.MAX_VALUE;
// 第0行和0列 都已经初始化过了 直接跳过
for(int i=1;i<=m;i++){
for(int j=1;j<=n;j++){
if(i==1&&j==1) dp[i][j]=grid[i-1][j-1];
else dp[i][j] = grid[i-1][j-1] + Math.min(dp[i-1][j],dp[i][j-1]);
}
}
return dp[m][n];
}
- 下面试试不填充直接dp,看看时间能不能快一点
果然可以。一个水题想复杂了
public int minPathSum(int[][] grid) {
int m = grid.length,n=grid[0].length;
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(i==0&&j==0) continue;
else if(i==0&&j>0) grid[i][j] += grid[i][j-1];
else if(j==0&&i>0) grid[i][j] += grid[i-1][j];
else {
grid[i][j] += Math.min(grid[i-1][j],grid[i][j-1]);
}
}
}
return grid[m-1][n-1];
}
70. 爬楼梯
纯水题,没什么好讲的,试试压缩空间的写法
// 题目比较友善 45 刚好没有溢出 否则就要大数了
public int climbStairs(int n) {
if (n < 4) return n;
int a = 2, b = 3, t = 0;
for (int i = 4; i <= n; i++) {
t = b;
b = a + b;
a = t;
}
return b;
}
75. 颜色分类
常数空间的一趟扫描算法
l维护左边最后一个非0
r维护右边最后一个非2
遍历: 遇到0就与l交换
遇到2就与r交换
简单调试一下就OK了
public void sortColors(int[] nums) {
int l=0,r=nums.length-1;
while (nums[l]==0) l++;
while (nums[r]==2) r--;
for(int i=l;i<=r;i++){
if(nums[i]==0) Swap(nums,i,l++);
else if(nums[i]==2) Swap(nums,i,r--);
}
}
75. 颜色分类
先两次遍历试试 不要急
循序渐进
public void sortColors(int[] nums) {
int l = 0;
while (l<nums.length&&nums[l]==0) l++;
for(int i=nums.length-1;i>l;i--){
if(nums[i]==0) {
Swap(nums,i,l++);
while (l<nums.length&&nums[l]==0) l++;
}
}
int r = nums.length-1;
while (r>=0&&nums[r]==2) r--;
for(int i=l;i<r;i++){
if(nums[i]==2){
Swap(nums,i,r--);
while (r>=0&&nums[r]==2) r--;
}
}
}
void Swap(int[] nums, int x,int y){
int t = nums[x];
nums[x] = nums[y];
nums[y] = t;
}
78. 子集
求集合子集,简单dfs
public List<List<Integer>> subsets(int[] nums) {
dfs(nums,0,new ArrayList<Integer>());
return ans;
}
List<List<Integer>> ans = new ArrayList<List<Integer>>();
void dfs(int[] nums,int n,List<Integer> tmp){
if(n==nums.length){
ans.add(new ArrayList<>(tmp));
return;
}
// 不选第n个
dfs(nums,n+1,tmp);
//选第n个
tmp.add(nums[n]);
dfs(nums,n+1,tmp);
tmp.remove(tmp.size()-1);//退栈时删除元素
}
看了题解又找到一种方法,直接迭代。枚举00…00~11…11 , 该位为1表示选,否则不选
注意: 1<<n 是 1向左边移动n位 也就是 0000000000000001 分别移动成
0000000000000001
0000000000000010
0000000000000100
0000000000001000
...
1000000000000000
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> ans = new ArrayList<>();
ArrayList<Integer> t = new ArrayList<>();
int n = nums.length;
for (int mask = 0; mask < (1<<n); mask++) { // 2^n == 1<<n
t.clear();
// 0~2^n-1 每个数字的二进制对应位置1表示选nums中对应位置元素
for(int i=0;i<n;i++){
if((mask&(1<<i))!=0){//&1<<i 分别获取每位上的二进制 看是否为1 (注意不是 i<<1) 1分别向左移动0,1,2,...n-1位
t.add(nums[i]);
}
}
ans.add(new ArrayList<>(t));
}
return ans;
}
时间上似乎比dfs还要慢一点
79. 单词搜索
先用dfs试试
写一半发现太难,突然想到可以有目的地DFS
有目的地深搜,可以,但是太慢了
public boolean exist(char[][] board, String word) {
this.board = board;
this.word = word;
this.M = board.length;
this.N = board[0].length;
this.visted = new boolean[M][N];
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) {
if (board[i][j] == word.charAt(0)) {
for (boolean[] arrb : visted) Arrays.fill(arrb,false);
if (dfs(0, i, j)) return true;
}
}
}
return false;
}
char[][] board;
String word;
int M, N;
int[] dx = {0, 0, 1, -1};
int[] dy = {1, -1, 0, 0};
boolean[][] visted;
boolean judge(int x, int y, int n) {
if (n >= word.length()) return false;
if (x < 0 || x >= M || y < 0 || y >= N) return false;
if(visted[x][y]) return false;
if (word.charAt(n) != board[x][y]) return false;
return true;
}
boolean dfs(int n, int x, int y) {
//System.out.printf("(%d %d): %c\n",x,y,board[x][y]);
visted[x][y] = true;
if (n == word.length() - 1) return true;
// 四个方向挑着走
for (int i = 0; i < dx.length; i++) {
if (judge(x + dx[i], y + dy[i], n + 1)) {
if (dfs(n + 1, x + dx[i], y + dy[i])) return true;
}
}
visted[x][y] = false; // 退栈时可认为没有访问
return false;
}
答案思路和我一样,只是没用这么多全局变量而已,不管了。
java写代码,封装思想,以后尽量少写全局变量吧
94. 二叉树的中序遍历 (TreeNode工具类)
纯纯水题:
List<Integer> ans = new ArrayList<Integer>();
public List<Integer> inorderTraversal(TreeNode root) {
if(root == null) return ans;
inorderTraversal(root.left);
ans.add(root.val);
inorderTraversal(root.right);
return ans;
}
收获是又写了一遍树的工具类
package cn.whu.utils;
import java.util.LinkedList;
import java.util.Queue;
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
public static TreeNode newNode(Integer val) {
if (val == null) return null;
else return new TreeNode(val);
}
// 层序创建二叉树
public static TreeNode create(Integer[] vals) {
if(vals==null||vals.length==0) return null;
Queue<TreeNode> q = new LinkedList<>();
int k = 0;
TreeNode root = new TreeNode(vals[k++]);
q.offer(root);
while (!q.isEmpty()) {
TreeNode top = q.poll();
if (k < vals.length) {
top.left = newNode(vals[k++]);
if (top.left != null) q.offer(top.left);
}
if (k < vals.length) {
top.right = newNode(vals[k++]);
if (top.right != null) q.offer(top.right);
}
}
return root;
}
// 层序创建二叉树 参数为String ',' 隔开 (#,null) 等任意非法字符串都可以表示null
public static TreeNode create(String strs) {
if(strs==null||strs.trim().length()==0) return null;
String[] split = strs.split(",");
Integer[] vals = new Integer[split.length];
for (int i = 0; i < split.length; i++) {
try {
Integer val = Integer.parseInt(split[i].trim());
vals[i] = val;
}catch (Exception e){
vals[i] = null;
}
}
return create(vals);
}
public void preOrder() {
System.out.print(this.val + " ");
if (this.left != null) this.left.preOrder();
if (this.right != null) this.right.preOrder();
}
public void lpreOrder() {
System.out.print("先序: ");
this.preOrder();
System.out.println();
}
public void inOrder() {
if (this.left != null) this.left.inOrder();
System.out.print(this.val + " ");
if (this.right != null) this.right.inOrder();
}
public void linOrder(){
System.out.print("中序: ");
this.inOrder();
System.out.println();
}
public void afterOrder() {
if (this.left != null) this.left.inOrder();
if (this.right != null) this.right.inOrder();
System.out.print(this.val + " ");
}
public void lafterOrder() {
System.out.print("后序: ");
this.afterOrder();
System.out.println();
}
public void levelOrder() {
Queue<TreeNode> q = new LinkedList<>();
q.offer(this);
while (!q.isEmpty()) {
TreeNode top = q.poll();
System.out.print(top.val + " ");
if (top.left != null) q.offer(top.left);
if (top.right != null) q.offer(top.right);
}
}
public void llevelOrder() {
System.out.print("层序: ");
this.levelOrder();
System.out.println();
}
public void show(){
this.lpreOrder();
this.linOrder();
this.lafterOrder();
this.llevelOrder();
}
public static void main(String[] args) {
TreeNode root;
Integer[] vals = {1, null, 2, 3};
root = TreeNode.create(vals);
root.show();
System.out.println("---------------------");
root = TreeNode.create("1, null, 2, 3");
root.show();
}
}
96. 不同的二叉搜索树
先看懂题目意思。问的是1,2,3,… n 这n个节点组成的BST有多少种,也就是中序遍历为1,2,3…n的二叉树有多少种。


看完答案真的好简单,但是自己想,太难想到了
public int numTrees(int n) {
int[] G = new int[n + 1];
G[0] = 1;//也是1 注意了
G[1] = 1;
for (int i = 2; i <= n; i++) {
// 计算1~i总共多种BST 求每个G[i]也是一个循环
for (int j = 1; j <=i; j++) {
// 1~i中 以j为root的BST有多少种 依次累计就是 结点为1~i的BST总数
G[i] += G[j - 1] * G[i - j]; // 这样从小求到大 保证了求后面时 前面的已经都有了
}
}
return G[n];
}
98. 验证二叉搜索树
第一眼看上去,这不水题吗?直接中序遍历一下不就行了吗?
过了,还真就是个水题
TreeNode pre = null;
public boolean isValidBST(TreeNode root) {
if (root == null) return true;
boolean left = isValidBST(root.left);
if (pre != null && pre.val >= root.val) return false;
pre = root;
boolean right = isValidBST(root.right);
return left && right;
}
101. 对称二叉树
又是一个水题,不过剑指里面刷过,dfs两个参数,从而同步地RNL和RLN即可
// RNL 和 RLN 同步遍历即可
public boolean isSymmetric(TreeNode root) {
return RNL_RLN(root,root);
}
public boolean RNL_RLN(TreeNode root1,TreeNode root2){
if(root1==null&&root2==null) return true;
if(root1==null&&root2!=null) return false;
if(root2==null&&root1!=null) return false;
if(root1.val!=root2.val) return false;
//System.out.println(root1.val+"\t"+root2.val);
return RNL_RLN(root1.left,root2.right)&&RNL_RLN(root1.right,root2.left);
}
单纯语法层面可以优化代码:
// RNL 和 RLN 同步遍历即可
public boolean isSymmetric(TreeNode root) {
return RNL_RLN(root,root);
}
public boolean RNL_RLN(TreeNode root1,TreeNode root2){
if(root1==null&&root2==null) return true;
if(root1==null||root2==null) return false;// 必然一个null 一个不为null 同为null的情况上面已经判断过了
return root1.val==root2.val&&RNL_RLN(root1.left,root2.right)&&RNL_RLN(root1.right,root2.left);
}
102. 二叉树的层序遍历
水题,层序遍历而已,只不过人家要的是每一层分别打印而已,稍作修改即可
小技巧是可以直接获取队列长度 int T = q.size(); 然后一次弄T个就都是一层的
public List<List<Integer>> levelOrder(TreeNode root) {
ArrayList<List<Integer>> ans = new ArrayList<>();
if(root==null) return ans;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
while (!q.isEmpty()){
// 每次把队列清完 里面的就是一层的
// 注意 可以直接获取队列的size
int T = q.size();
ArrayList<Integer> list = new ArrayList<>();
while (T-->0){
TreeNode node = q.poll();
list.add(node.val);
if(node.left!=null) q.offer(node.left);
if(node.right!=null) q.offer(node.right);
}
ans.add(list);//每次有新new的内存 也是必须new的内存
}
return ans;
}
104. 二叉树的最大深度
简单递归,或者说DFS,又是一个水题啊
太水了 , 就是写AVL时,求height的一个分支
public int maxDepth(TreeNode root) {
if (root == null) return 0;
if(root.left==null&&root.right==null) return 1;
int h1 = maxDepth(root.left);
int h2 = maxDepth(root.right);
return Math.max(h1,h2)+1;
}
105. 从前序与中序遍历序列构造二叉树
现在写这种题 也很水了
注意细节: inorder找根 得从给定的起点开始找,而不是从0开始找
public TreeNode buildTree(int[] preorder, int[] inorder) {
return create(preorder,inorder,0,preorder.length-1,0,inorder.length-1);
}
// [x,y]是preorder的字串下标 [a,b]是inorder的子串下标
TreeNode create(int[] preorder, int[] inorder, int x, int y, int a, int b) {
if(x>y||a>b) return null;
TreeNode root = new TreeNode(preorder[x]);
int k = a;// 千万注意从给的起点开始找
while (inorder[k]!=root.val) k++;//中序中找根 //只要是合法的就一定能找到
root.left = create(preorder,inorder,x+1,x+(k-a),a,k-1);
root.right = create(preorder,inorder,x+(k-a)+1,y,k+1,b);
return root;
}
效率不高,可以给结点建立一个Hash表,以快速定位到根结点,不用每次在中序序列中找了。牺牲空间换时间的做法,很简单,这里就不写了。
114. 二叉树展开为链表
先两趟遍历,过了再说
public void flatten(TreeNode root) {
preOrder(root);
TreeNode tail = null;
for (TreeNode node : preList) {
if(tail!=null) {
tail.right = node;
tail.left=null;
}
tail=node;
}
}
List<TreeNode> preList = new ArrayList<TreeNode>();
void preOrder(TreeNode root){
if(root==null) return;
preList.add(root);
preOrder(root.left);
preOrder(root.right);
}
- 深刻理解先序遍历的含义,直接一趟修改指针
将左子树插入到右子树的地方
将原来的右子树接到左子树的最右边节点
考虑新的右子树的根节点,一直重复上边的过程,直到新的右子树为 null
public void flatten(TreeNode root) {
if(root==null) return;
TreeNode right = root.right;
TreeNode left = root.left;
// 左子树插到右子树
if(left!=null){
root.right = root.left;
// 原来的右子树不空 插到左子树 最右边
if(right!=null){
TreeNode node = left;
while (node.right!=null) node=node.right;
node.right = right;
}
}
root.left=null;//左子树一定置为null
// 继续拉伸右子树
flatten(root.right);
}
- 还有一种有趣的解法
先遍历每次将前一个的right指向后一个,这样会导致原来的尚未遍历的right右子树丢失
这个时候,使用逆先序遍历,就避免这个问题了
注意先序:NLR => 逆先序:RLN
先写逆先序:
public void flatten(TreeNode root) {
if(root==null) return;
flatten(root.right);//注意先右
flatten(root.left);
System.out.println(root.val);
}
TreeNode pre = null;
public void flatten(TreeNode root) {
if(root==null) return;
flatten(root.right);
flatten(root.left);
root.left = null;
root.right = pre;
pre = root;
}
不得不说,逆先序遍历,太牛了~

121. 买卖股票的最佳时机
一趟遍历,维护当前遍历到的最小值即可
public int maxProfit(int[] prices) {
int min = prices[0];
int max = 0;
for (int i = 1; i < prices.length; i++) {
int t = prices[i]-min;
if(t>0) {
if(t>max) max=t;
}else {
min = prices[i];
}
}
return max;
}
128. 最长连续序列
用Hash表判断相邻元素是否存在
java HashSet 的contain方法就是Hash判断,时间复杂度就是O(1)
关键点:if (!hash.contains(num - 1)),每个串只会遍历一次,保证了O(n)
// 1、看清题意 2、时间O(n)
// 思路,用Hash表O(1)判断相邻元素是否存在
public int longestConsecutive(int[] nums) {
HashSet<Integer> hash = new HashSet<Integer>();
for (int num : nums) {
hash.add(num);
}
int max = 0;
for (int num : nums) {
// 我不是最好的起点 就不做起点 (这样就避免了不必要的遍历 或者说 只会遍历一次)
if (!hash.contains(num - 1)) {
int k = 1;
// 我是最好的起点 可以开始查
while (hash.contains(num + k)) k++;
max = Math.max(max, k);
}
}
return max;
}
136. 只出现一次的数字
剑指刷过 现在做就简单了 直接全部异或即可 异或就是相同取0相异取1嘛 而且有交换律和结合律 最终剩一个就是结果了
public int singleNumber(int[] nums) {
int ans = nums[0];
for (int i = 1; i < nums.length; i++) {
ans ^= nums[i];
}
return ans;
}
139. 单词拆分
- 完全看着题解写的dp,看懂容易,想到难啊
个人觉得核心还是hash表判断一个元素是否存在是O(1)的时间复杂度
public boolean wordBreak(String s, List<String> wordDict) {
HashSet<String> hash = new HashSet<>();
for (String s1 : wordDict) {
hash.add(s1);
}
boolean[] dp = new boolean[s.length()+1];
dp[0] = true;//很重要 默认是false
//先一定明确 dp[j]表示s[0~j-1]是否存在 check[j,i-1]表示s[j~i-1]是否存在
for (int i = 1; i <= s.length(); i++) {//dp[0]已经初始化了 要从1开始
for(int j=0;j<i;j++){
dp[i] |= (dp[j]&hash.contains(s.substring(j,i)));
if(dp[i]) break;//true了就行了
}
}
return dp[s.length()];
}
- 优化,记录一下最长长度,可以减少一些不必要的判断
// 优化 记录一下长度
public boolean wordBreak(String s, List<String> wordDict) {
HashSet<String> hash = new HashSet<>();
int maxl = 0;
for (String s1 : wordDict) {
hash.add(s1);
maxl = Math.max(maxl,s1.length());
}
boolean[] dp = new boolean[s.length()+1];
dp[0] = true;//很重要 默认是false
//先一定明确 dp[j]表示s[0~j-1]是否存在 check[j,i-1]表示s[j~i-1]是否存在
for (int i = 1; i <= s.length(); i++) {//dp[0]已经初始化了 要从1开始
for(int j=0;j<i;j++){
if(i-j>maxl) dp[i]=false;//注意长度是 (i-1)-j+1=i-j //长度超限 直接就可以退出了
else dp[i] |= (dp[j]&hash.contains(s.substring(j,i)));
if(dp[i]) break;//true了就行了
}
}
return dp[s.length()];
}
141. 环形链表
public boolean hasCycle(ListNode head) {
if(head==null) return false;
ListNode p = head,q=head;
// 快慢指针,相遇就是有环
while (true){
p = p.next;
q = q.next;
if(q!=null) q=q.next;
if(q==null) return false;
if (p==q) return true;
}
}
很简单,但是自己造环花了好长时间
public class LC141 {
public boolean hasCycle(ListNode head) {
if(head==null) return false;
ListNode p = head,q=head;
// 快慢指针,相遇就是有环
while (true){
p = p.next;
q = q.next;
if(q!=null) q=q.next;
if(q==null) return false;
if (p==q) return true;
}
}
public static void main(String[] args) {
test(new int[]{3,2,0,-4}, 1);
test(new int[]{1,2}, 0);
test(new int[]{3,2,0,-4}, -1);
test(new int[]{}, -1);
}
private static void test(int[] head, int pos) {
// 1. 创建初始列表
ListNode root = create(head, pos);
print(root, head);
// 4. 测试
LC141 t = new LC141();
boolean b = t.hasCycle(root);
System.out.println(b);
}
private static ListNode create(int[] head, int pos) {
// 1. 创建初始列表
ListNode root = ListNode.create(head);
if(root==null) return root;
// 2. 找到尾结点和环入口
ListNode tail = root;
ListNode circle = null;
for(int i = 0; i< head.length; i++) {
if(i == pos) circle = tail;//pos为负数 circle保持为null
if(tail.next!=null) tail = tail.next;
}
// 3. 成环
tail.next = circle;
//System.out.println(tail.val+" "+circle.val);
return root;
}
static void print(ListNode root,int[] head){
ListNode node = root;
for(int i=0;i<head.length*3;i++){
if(node!=null) {
System.out.print(node.val+" ");
node = node.next;
}
}
}
}
142. 环形链表 II
承接上题: 多走的距离肯定是开始那段距离 (多走的距离指的是 对环长取余后 的距离) 因此让q回归起点再同步走即可
public ListNode detectCycle(ListNode head) {
if(head==null) return null;
ListNode p = head,q=head;
// 快慢指针,相遇就是有环
while (true){
p = p.next;
q = q.next;
if(q!=null) q=q.next;
if(q==null) return null;
if (p==q){
p = head; //多走的距离肯定是开始那段距离 (多走的距离指的是 对环长取余后 的距离) 因此让q回归起点再同步走即可
while (q!=p){
q=q.next;
p=p.next;
}
return p;//一定再环入口处相遇
}
}
}
146. LRU 缓存 ★
写了2个多小时,总算通过了,完全自己的思路,太难了
// 思路没错 Hash表+双向链表
class ListNode {
int value;
int key;
ListNode pre, next;
ListNode head, tail;
ListNode() {
head = this;
tail = head;
}//有头结点
ListNode(int value, int key) {
this.value = value;
this.key = key;
head = this;
tail = head;
}
void addFirst(ListNode node) {
// 带头结点 头插
node.next = head.next;
if (head.next != null) head.next.pre = node;
head.next = node;
node.pre = head;
if (tail == head) tail = node;//千万注意tail的维护
}
ListNode removeLast() {
ListNode ret = tail;
tail.pre.next = null;
tail = tail.pre;
return ret;
}
void move2First(ListNode node) {
if(node==tail) removeLast();//千万注意tail的维护
node.pre.next = node.next;
if (node.next != null) node.next.pre = node.pre;
addFirst(node);
}
}
class LRUCache {
//map[key]->LinkedList->当前结点值就是value
// 帮忙维护key
ListNode cache = new ListNode();
int SIZE = 0;
int len = 0;
// Hash使得取是O(1)
HashMap<Integer, ListNode> map = new HashMap<>();
public LRUCache(int capacity) {
this.SIZE = capacity;
}
public int get(int key) {
if (map.containsKey(key)) {
//移动到最前面
cache.move2First(map.get(key));
return map.get(key).value;
} else return -1;
}
public void put(int key, int value) {
if (map.containsKey(key)) {//直接修改后移动
ListNode node = map.get(key);
node.value = value;
cache.move2First(node);
}else if (len < SIZE){//直接头插 结点数多一个
ListNode node = new ListNode(value,key);
map.put(key, node);
cache.addFirst(node);
len++;//这里new了结点的才需要++
}else { // 删除最后一个 再头部插入一个新的
map.remove(cache.removeLast().key);//删除末尾 同时从hash中去掉呀
ListNode node = new ListNode(value,key);
map.put(key, node);
cache.addFirst(node);
}
}
}
完整测试代码:
package cn.whu.leetcode.lc146_1LRU缓存;
import java.util.HashMap;
// 思路没错 Hash表+双向链表
class ListNode {
int value;
int key;
ListNode pre, next;
ListNode head, tail;
ListNode() {
head = this;
tail = head;
}//有头结点
ListNode(int value, int key) {
this.value = value;
this.key = key;
head = this;
tail = head;
}
void addFirst(ListNode node) {
// 带头结点 头插
node.next = head.next;
if (head.next != null) head.next.pre = node;
head.next = node;
node.pre = head;
if (tail == head) tail = node;//千万注意tail的维护
}
ListNode removeLast() {
ListNode ret = tail;
tail.pre.next = null;
tail = tail.pre;
return ret;
}
void move2First(ListNode node) {
if(node==tail) removeLast();//千万注意tail的维护
node.pre.next = node.next;
if (node.next != null) node.next.pre = node.pre;
addFirst(node);
}
}
class LRUCache {
//map[key]->LinkedList->当前结点值就是value
// 帮忙维护key
ListNode cache = new ListNode();
int SIZE = 0;
int len = 0;
// Hash使得取是O(1)
HashMap<Integer, ListNode> map = new HashMap<>();
public LRUCache(int capacity) {
this.SIZE = capacity;
}
public int get(int key) {
if (map.containsKey(key)) {
//移动到最前面
cache.move2First(map.get(key));
return map.get(key).value;
} else return -1;
}
public void put(int key, int value) {
if (map.containsKey(key)) {//直接修改后移动
ListNode node = map.get(key);
node.value = value;
cache.move2First(node);
}else if (len < SIZE){//直接头插 结点数多一个
ListNode node = new ListNode(value,key);
map.put(key, node);
cache.addFirst(node);
len++;//这里new了结点的才需要++
}else { // 删除最后一个 再头部插入一个新的
map.remove(cache.removeLast().key);//删除末尾 同时从hash中去掉呀
ListNode node = new ListNode(value,key);
map.put(key, node);
cache.addFirst(node);
}
}
}
public class LC146 {
public static void main(String[] args) {
/*String[] cmd = {"LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"};
int[][] vals = new int[][]{{2}, {1, 1}, {2, 2}, {1}, {3, 3}, {2}, {4, 4}, {1}, {3}, {4}};
test(cmd, vals);*/
String[] cmd = {"LRUCache","put","put","put","put","put","get","put","get","get","put","get","put","put","put","get","put","get","get","get","get","put","put","get","get","get","put","put","get","put","get","put","get","get","get","put","put","put","get","put","get","get","put","put","get","put","put","put","put","get","put","put","get","put","put","get","put","put","put","put","put","get","put","put","get","put","get","get","get","put","get","get","put","put","put","put","get","put","put","put","put","get","get","get","put","put","put","get","put","put","put","get","put","put","put","get","get","get","put","put","put","put","get","put","put","put","put","put","put","put"};
int[][] vals = new int[][]{{10},{10,13},{3,17},{6,11},{10,5},{9,10},{13},{2,19},{2},{3},{5,25},{8},{9,22},{5,5},{1,30},{11},{9,12},{7},{5},{8},{9},{4,30},{9,3},{9},{10},{10},{6,14},{3,1},{3},{10,11},{8},{2,14},{1},{5},{4},{11,4},{12,24},{5,18},{13},{7,23},{8},{12},{3,27},{2,12},{5},{2,9},{13,4},{8,18},{1,7},{6},{9,29},{8,21},{5},{6,30},{1,12},{10},{4,15},{7,22},{11,26},{8,17},{9,29},{5},{3,4},{11,30},{12},{4,29},{3},{9},{6},{3,4},{1},{10},{3,29},{10,28},{1,20},{11,13},{3},{3,12},{3,8},{10,9},{3,26},{8},{7},{5},{13,17},{2,27},{11,15},{12},{9,19},{2,15},{3,16},{1},{12,17},{9,1},{6,19},{4},{5},{5},{8,1},{11,7},{5,2},{9,28},{1},{2,2},{7,4},{4,22},{7,24},{9,26},{13,28},{11,26}};
test(cmd,vals);
}
private static void test(String[] cmd, int[][] vals) {
LRUCache lruCache = new LRUCache(vals[0][0]);
for (int i = 1; i < cmd.length; i++) {
if (cmd[i].equals("put")) {
lruCache.put(vals[i][0], vals[i][1]);
System.out.printf("put (%d,%d)\n",vals[i][0],vals[i][1]);
} else {
System.out.printf("【get %d: %d】\n",vals[i][0],lruCache.get(vals[i][0]));
}
print(lruCache.cache);
}
}
static void print(ListNode node){
while (node.next!=null){
System.out.print("("+node.next.key+","+node.next.value+")");
node=node.next;
if(node.next!=null) System.out.print(" -> ");
}
System.out.println();
}
}
现在总结一下中心思想,首先用一个双向链表存储(key-value (2个成员即可))
map(key)->定位到链表结点
每次put或者get的结点都要在头部
双向链表维护首位指针,头插、尾插、删除指定结点,时间复杂度都是O(1)
Trick:维护一个头结点,相当于伪首部
同时可以维护一个伪的tail, 伪尾部
代码会好写很多
改进后的代码如下:
根据题解优化了一下,主要就是多了一个伪首部,方便了点
然后封装了一个单独的removeNode方法
import java.util.HashMap;
// 思路没错 Hash表+双向链表
class LRUCache {
class DLinkedNode {
int key, value;
DLinkedNode pre, next;
DLinkedNode() {}
DLinkedNode(int key, int value) {
this.value = value;
this.key = key;
}
}
// 双向链表的伪首部和伪尾部
DLinkedNode head, tail;
int size, capacity;
//map[key]->ListNode->当前结点值就是value
HashMap<Integer, DLinkedNode> cache = new HashMap<>();// Hash使得取是O(1)
public LRUCache(int capacity) {
this.capacity = capacity;
// 伪首部和伪尾部
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.pre = head;
}
public int get(int key) {
if (cache.containsKey(key)) {
move2Head(cache.get(key));//移动到最前面
return cache.get(key).value;
} else return -1;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node != null) {//直接修改后移动
node.value = value;
move2Head(node);
} else {//肯定要创建新结点
DLinkedNode nodei = new DLinkedNode(key, value);
cache.put(key, nodei);
addFirst(nodei);
size++;
if (size > capacity) {
DLinkedNode tail = removeLast();
cache.remove(tail.key);//为何要存储key 因为这里要用
size--;
}
}
}
private DLinkedNode removeLast() {
DLinkedNode ret = tail.pre;
removeNode(tail.pre);
return ret;
}
private void addFirst(DLinkedNode node) {
node.next = head.next;
head.next.pre=node;
head.next = node;
node.pre = head;
}
private void move2Head(DLinkedNode node) {
removeNode(node);
addFirst(node);
}
// 写一个辅助函数会方便许多
private void removeNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
}
其实java有一个现成的数据结构直接就实现了这个:LinkedHashMap, 非常支持LRU
就是HashMap+双向链表,直接就实现了LRU,直接用他即可
LinkedHashMap里有3个特别好的方法:
1) void afterNodeAccess(Node<K,V> p) { }
只要访问了HashMap里的元素,就会将该元素放到链尾部
这里的访问是指,get或者put
-
- 使用 get 方法会访问到节点, 从而触发调用这个方法
-
- 使用 put 方法插入节点, 如果 key 存在, 也算要访问节点, 从而触发该方法
-
- 只有 accessOrder 是 true 才会调用该方法
-
- 这个方法会把访问到的最后节点重新插入到双向链表结尾
所以最近访问的一定在尾部,已经可以保证了
(删除时得从头部删除了 或者说现在容量超限时 删除头部即可达到题目要求)
2)void afterNodeInsertion(boolean evict) { }
在插入新元素之后,触发此方法,需要回调函数判断是否需要移除一直不用的某些元素!
给一个boolean条件, 这个方法会自动移除一个头部元素
3)void afterNodeRemoval(Node<K,V> p) { } (本题用不到)
在hashmap.remove删除元素之后,会触发这个方法,将元素从双向链表中删除(很容易 因为直接能拿到结点本身)
package cn.whu.leetcode.lc146_3LRU缓存;
import java.util.LinkedHashMap;
import java.util.Map;
class LRUCache extends LinkedHashMap {
int capacity = 0;
//初始化内置HashMap
public LRUCache(int capacity) {
// 第三个参数false: 按照插入顺序排序 true: 按照读取顺序排序 (读取后会重排)
super(capacity, 0.75F, true);
this.capacity=capacity;
}
// 在内置的HashMap内get
public int get(int key) {
return (int) super.getOrDefault(key,-1);
}
// 在内置的HashMap内put
public void put(int key, int value) {
super.put(key,value);
}
// get或者put之后 会触发afterNodeAccess 将刚刚访问得元素移动到内置双向链表末尾
@Override //给 afterNodeAccess() 方法用 插入后且满足此方法条件,会删除一些旧的元素
protected boolean removeEldestEntry(Map.Entry eldest) {
return size()>capacity;//HashMap得size()方法 直接获取长度
}
}
public class LC146 {
public static void main(String[] args) {
String[] cmd = {"LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"};
int[][] vals = new int[][]{{2}, {1, 1}, {2, 2}, {1}, {3, 3}, {2}, {4, 4}, {1}, {3}, {4}};
test(cmd, vals);
}
private static void test(String[] cmd, int[][] vals) {
LRUCache lruCache = new LRUCache(vals[0][0]);
for (int i = 1; i < cmd.length; i++) {
if (cmd[i].equals("put")) {
lruCache.put(vals[i][0], vals[i][1]);
System.out.printf("put (%d,%d)\n", vals[i][0], vals[i][1]);
} else {
System.out.printf("【get %d: %d】\n", vals[i][0], lruCache.get(vals[i][0]));
}
}
}
}
测试结果,和我写的效率差不了多少
不难,确实不难,还是练得不够,得多刷题呀
- 二刷
class LRUCache {
class Node{
int key,value;
Node pre,next;
public Node(){}
public Node(int key,int value){
this.key = key;
this.value = value;
}
}
Node head;//头结点
Node tail;//尾结点 均只是起一个占位作用
int capacity = 0;
HashMap<Integer, Node> map;
public LRUCache(int capacity) {
this.capacity = capacity;
head = new Node();
tail = new Node();
head.next = tail;
tail.pre = head;
map = new HashMap<>();
}
public int get(int key) {
if(map.containsKey(key)){
Node node = map.get(key);
move2Head(node);
return node.value;
}else {
return -1;
}
}
public void put(int key, int value) {
if(map.containsKey(key)){
Node node = map.get(key);
node.value = value;
move2Head(node);
}else {
Node node = new Node(key, value);
addFirst(node);
map.put(key,node);//千万别忘了!!!
if(map.size()>capacity){
map.remove(tail.pre.key); //注意map里也得删除 //不要再remove方法里删除 否则move2First时也会被删除
remove(tail.pre);//删除末尾的
}
}
}
public void remove(Node node){
node.pre.next = node.next;
node.next.pre = node.pre;
}
public void addFirst(Node node){
Node first = head.next;
first.pre = node;
node.next = first;
head.next = node;
node.pre = head;
}
public void move2Head(Node node){
remove(node);
addFirst(node);
}
}
- 二刷完整代码
package cn.whu.leetcode.interview150.lc146LRU缓存.二刷.es02;
import cn.whu.utils.HzaUtils;
import cn.whu.utils.Solution;
import java.util.HashMap;
import java.util.List;
class LRUCache {
class Node{
int key,value;
Node pre,next;
public Node(){}
public Node(int key,int value){
this.key = key;
this.value = value;
}
}
Node head;//头结点
Node tail;//尾结点 均只是起一个占位作用
int capacity = 0;
HashMap<Integer, Node> map;
public LRUCache(int capacity) {
this.capacity = capacity;
head = new Node();
tail = new Node();
head.next = tail;
tail.pre = head;
map = new HashMap<>();
}
public int get(int key) {
if(map.containsKey(key)){
Node node = map.get(key);
move2Head(node);
return node.value;
}else {
return -1;
}
}
public void put(int key, int value) {
if(map.containsKey(key)){
Node node = map.get(key);
node.value = value;
move2Head(node);
}else {
Node node = new Node(key, value);
addFirst(node);
map.put(key,node);//千万别忘了!!!
if(map.size()>capacity){
map.remove(tail.pre.key); //注意map里也得删除 //不要再remove方法里删除 否则move2First时也会被删除
remove(tail.pre);//删除末尾的
}
}
}
public void remove(Node node){
node.pre.next = node.next;
node.next.pre = node.pre;
}
public void addFirst(Node node){
Node first = head.next;
first.pre = node;
node.next = first;
head.next = node;
node.pre = head;
}
public void move2Head(Node node){
remove(node);
addFirst(node);
}
}
public class LC146 extends Solution {
public static void main(String[] args) {
String[] cmds = HzaUtils.string2Strings("[LRUCache, put, put, get, put, get, put, get, get, get]");
List<List<String>> data = HzaUtils.string2StringList2D("[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]");
print(cmds);
print(data);
LRUCache cache = null;
for (int i = 0; i < cmds.length; i++) {
print();
String cmd = cmds[i];
int a = Integer.parseInt(data.get(i).get(0));
int b = 0;
if(data.get(i).size()==2){
b = Integer.parseInt(data.get(i).get(1));
}
if("LRUCache".equals(cmd)){
cache = new LRUCache(a);
}else if("put".equals(cmd)){
cache.put(a,b);
}else if("get".equals(cmd)){
int ans = cache.get(a);
print(ans);
}
//prints(cmd,":",data.get(i));
//show(cache);
}
}
static void show(LRUCache cache){
LRUCache.Node node = cache.head.next;
System.out.print("[");
while (node!=cache.tail){
System.out.print("["+node.key+"->"+node.value+"],");
node = node.next;
}
System.out.println("]");
System.out.print("{");
for (Integer key : cache.map.keySet()) {
System.out.print(key+"="+cache.map.get(key).value+", ");
}
System.out.println("}");
}
}
148. 排序链表 ▲
二刷最优解(代码最优)
package cn.whu.leetcode.interviewing.lc148排序链表;
class ListNode{
int val;
ListNode next;
ListNode(int val){
this.val = val;
}
public static ListNode create(int[] vals){
ListNode head = new ListNode(0);
ListNode tail = head;
for (int i = 0; i < vals.length; i++) {
tail.next = new ListNode(vals[i]);
tail = tail.next;
}
return head.next;
}
void show(){
ListNode p = this;
while (p!=null){
System.out.print(p.val+" ");
p = p.next;
}
System.out.println();
}
}
public class LC148 {
public ListNode sortList(ListNode head) {
//head.show();
if(head==null||head.next==null) return head;
//先划分
ListNode fast = head.next, slow = head;
while (fast!=null&&fast.next!=null){
fast = fast.next.next;
slow = slow.next;
}
ListNode mid = slow.next;
slow.next = null;
//head.show();
//mid.show();
ListNode left = sortList(head);//递归二分
ListNode right = sortList(mid);//递归二分
// 开始回溯归并
ListNode ans = new ListNode(-1);
ListNode tail = ans;
while (left!=null&&right!=null){
if(left.val<right.val){
tail.next = left;
left = left.next;
}else {
tail.next = right;
right = right.next;
}
tail = tail.next;
}
if(left!=null) tail.next = left;
if(right!=null) tail.next = right;
return ans.next;
}
public static void main(String[] args) {
int[] vals = {4,2,1,3};
ListNode head = ListNode.create(vals);
LC148 t = new LC148();
ListNode ans = t.sortList(head);
if(ans==null) System.out.println("null");
else ans.show();
}
}
遇事不要慌,先过了再说
- 暴力通过
public ListNode sortList(ListNode head) {
ArrayList<Integer> list = new ArrayList<>();
ListNode node = head;
while (node!=null){
list.add(node.val);
node = node.next;
}
//Integer[] arr = list.toArray(new Integer[list.size()]);
Collections.sort(list);
node = head;
for (Integer val :list){
node.val=val;
node=node.next;
}
return head;
}
接下来再考虑优化
归并排序 O(n*logn) , 是可以应用于链式结构的
但是 归并,用到递归,空间复杂度目前还是O(logn)
- 归并排序:自顶向下归并排序(递归)-》空间logn 时间O(nlogn)
public ListNode sortList(ListNode head) {
return sortList(head, null); // 左闭右开的好处 这里直接传一个null就行了 下面都保持左闭右开 又不是不能写了
}
// 注意 这条链的区间是 head~tail.pre
public ListNode sortList(ListNode head, ListNode tail) {
if (head == null) return head;
if(head.next == tail) {//递归边界 及时处理 此时就只有一个结点了 (注意都是左闭右开 head.next == )
head.next = null; // 直接单个结点作为一条链返回
return head; // 单个结点就是自己一条链 已经有序了 不需要merge归并
}
//快慢指针找中点
ListNode slow=head,fast = head;
while (fast!=tail){//直接把tail想像成逻辑上的null即可
slow = slow.next;
fast = fast.next;
if(fast!=tail) fast = fast.next;
}
ListNode mid = slow;
return merge(sortList(head,mid),sortList(mid,tail));//都是左闭右开
}
// 合并之后要返回一条新的链表 //都是null结尾
public ListNode merge(ListNode headA, ListNode headB) {
ListNode head = new ListNode();
ListNode tail = head,tailA = headA,tailB=headB;//命名为tail 就不会忘记tail=tail.next的移动了
while (tailA!=null&&tailB!=null){
if(tailA.val<=tailB.val){
tail.next = tailA;
tailA = tailA.next;//别忘了
}else {
tail.next = tailB;
tailB = tailB.next;//别忘了
}
tail = tail.next;
}
if(tailA!=null) tail.next = tailA;
else tail.next = tailB;//就算tailB是null也无所谓 //最后都要以null结尾啊
return head.next;//去掉头节点
}
- 归并排序:自底向上归并排序 -》空间O(1) 时间O(nlogn) 其实就是改为非递归写法
for循环分别 11合并 22合并 44合并 … 直到len/2,len/2合并
这样就节省了空间了
public ListNode sortList(ListNode head) {
if(head==null) return null;
// 计算链表长度
int len = 0;
ListNode node = head;
while (node != null) {
len++;
node=node.next;
}
ListNode preHead = new ListNode(-1,head);//加一个头节点 或者说单独开一条preHead为首的链 后面全部链在头结点后面
for (int step = 1; step < len; step<<=1) {//step*=2 注意是<<=1 不是 <<=2
ListNode preTail = preHead;
ListNode curr = preHead.next;
while (curr!=null){//多次两两归并 curr记录当前归并到哪里了
// 1、找step个元素 单独拆下来成一条链
ListNode head1 = curr;
// i要从1开始 因为curr已经是一个元素了
for(int i=1;i<step&&curr!=null;i++){//注意一下 左毕右开 curr.next!=null
curr = curr.next;
}
ListNode next = null;//后面可能没完 还要接着合并呢 记录下来本次归并到哪里了
if(curr!=null){//curr为null就没有next了
next = curr.next;
curr.next = null;//head1成单独一条链
}
// 2、接着找step个元素 拆下来成另一条链
ListNode head2 = next;//head2的起点 //注意先扯断链 再给新起点
curr = head2;
for(int i=1;i<step&&curr!=null;i++){//curr!=null 防止上来就是null
curr = curr.next;
}
next = null;//后面可能没完 还要接着合并呢 记录下来本次归并到哪里了
if(curr!=null){//curr为null就没有next了
next = curr.next;
curr.next = null;//head2成单独一条链 整个next之前的都会被归并 null是终点嘛 所以下次从next开始归并就行了
}
// 3.、归并两条链 一次连在preh后面
preTail.next = merge(head1,head2);
while (preTail.next!=null) preTail=preTail.next;//再指向链尾 下次接着连呀
curr = next;//接着往后归并啊
}
}
return preHead.next;
}
// 合并之后要返回一条新的链表 //都是null结尾
public ListNode merge(ListNode headA, ListNode headB) {
ListNode head = new ListNode();
ListNode tail = head,tailA = headA,tailB=headB;//命名为tail 就不会忘记tail=tail.next的移动了
while (tailA!=null&&tailB!=null){
if(tailA.val<=tailB.val){
tail.next = tailA;
tailA = tailA.next;//别忘了
}else {
tail.next = tailB;
tailB = tailB.next;//别忘了
}
tail = tail.next;
}
if(tailA!=null) tail.next = tailA;
else tail.next = tailB;//就算tailB是null也无所谓 //最后都要以null结尾啊
return head.next;//去掉头节点
}
节省了空间,但比递归要慢一点
152. 乘积最大子数组
- 老规矩 先暴力 通过再说
// 老规矩 先暴力
public int maxProduct(int[] nums) {
int max = Integer.MIN_VALUE;
for (int i = 0; i < nums.length; i++) {
int sum = 1;
for (int j = i; j < nums.length; j++) {
sum *= nums[j];
max = Math.max(max,sum);
}
}
return max;
}
- 其实也是很简单的dp : 同时维护以i结尾的连续子数组 的最大和最小值 2个数组即可
nums[i]是正数 那么max可能是 nums[i]*dpMax[i-1] min可能是nums[i]*dpMin[i-1]
nums[i]是负数 那么max可能是 nums[i]*dpMin[i-1] min可能是nums[i]*dpMax[i-1]
同时维护两个dp数组
// 其实也是很简单的dp : 同时维护以i结尾的连续子数组 的最大和最小值 数组即可
public int maxProduct(int[] nums) {
int max = nums[0];
int[] dpMax = new int[nums.length];
int[] dpMin = new int[nums.length];
dpMax[0] = nums[0];
dpMin[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
if(nums[i]>0){
dpMax[i] = Math.max(nums[i],nums[i]*dpMax[i-1]);
dpMin[i] = Math.min(nums[i],nums[i]*dpMin[i-1]);
}else {//<=0
dpMax[i] = Math.max(nums[i],nums[i]*dpMin[i-1]);
dpMin[i] = Math.min(nums[i],nums[i]*dpMax[i-1]);
}
max = Math.max(max,dpMax[i]);
}
return max;
}
语法层面优化一下:
第一步优化:
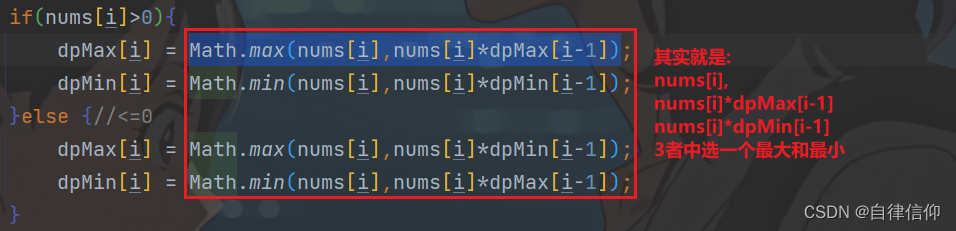
第二步优化: 每次dp[i]都只用得到dp[i-1] 所以可以使用一维滚动数组 节省空间

// 其实也是很简单的dp : 同时维护以i结尾的连续子数组 的最大和最小值 数组即可
public int maxProduct(int[] nums) {
int max = nums[0],dpMax = nums[0],dpMin = nums[0];
for (int i = 1; i < nums.length; i++) {
int mm = dpMax,mn=dpMin;//得先咱暂存下来 否则 第一个dpMax赋值完毕 原来的dpMax值丢失了 dpMin就没法子求了
dpMax = Math.max(nums[i], Math.max(nums[i] * mm, nums[i] * mn));
dpMin = Math.min(nums[i], Math.min(nums[i] * mm,nums[i] * mn));
max = Math.max(max, dpMax);
}
return max;
}
155. 最小栈
不难,双栈维护即可,其中一个mins栈始终重复地压入目前维护的最小值即可
class MinStack {
LinkedList value;
LinkedList mins;
int min;
public MinStack() {
value = new LinkedList<Integer>();
mins = new LinkedList<Integer>();
min = Integer.MAX_VALUE;
}
public void push(int val) {
min = Math.min(val,min);
value.add(val);
mins.add(min);//维护当前最小值即可 最小值被pop之前 都是这个值最小
}
public void pop() {
value.removeLast();
mins.removeLast();
//注意这里也要更新min
if(mins.isEmpty()) min = Integer.MAX_VALUE;
else min = getMin();
}
public int top() {
return (int) value.getLast();//栈都是在末尾操作 一端操作
}
public int getMin() {
return (int) mins.getLast();
}
}
效率有点低,看题解再优化一下吧:
快了1ms
trick: mins栈 底部 始终多维护一个MAX_VALUE
import java.util.LinkedList;
class MinStack {
LinkedList value;
LinkedList mins;
public MinStack() {
value = new LinkedList<Integer>();
mins = new LinkedList<Integer>();
mins.add(Integer.MAX_VALUE);//技巧 栈底部始终多维护一个MAX_VALUE
}
public void push(int val) {
value.add(val);
mins.add(Math.min(val,getMin()));//维护当前最小值即可 最小值被pop之前 都是这个值最小
}
public void pop() {
value.removeLast();
mins.removeLast();
}
public int top() {
return (int) value.getLast();//栈都是在末尾操作 一端操作
}
public int getMin() {
return (int) mins.getLast();
}
}
160. 相交链表
408真题,挺水的了
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
int lenA = 0, lenB = 0;
ListNode node1 = headA, node2 = headB;
while (node1 != null) {
lenA++;
node1 = node1.next;
}
while (node2 != null) {
lenB++;
node2 = node2.next;
}
// 保证node1是长的那个
node1 = headA;
node2 = headB;//注意把值赋回来
if (lenA < lenB) {
ListNode tmp = node1;
node1 = node2;
node2 = tmp;
}
int T = Math.abs(lenA - lenB);
while (T-->0) {
node1 = node1.next;
}
while (node1 != node2) {
node1 = node1.next;
node2 = node2.next;
}
return node1;
}
其实有一种巧妙的省事的写法
A,B 同时移动
谁先到null就指向另一个头部,然后继续同步后移
另一个到头了,这个就恰好走了差值个步数,再同步即可相遇
加入A长B短
图片来自leetcode题解
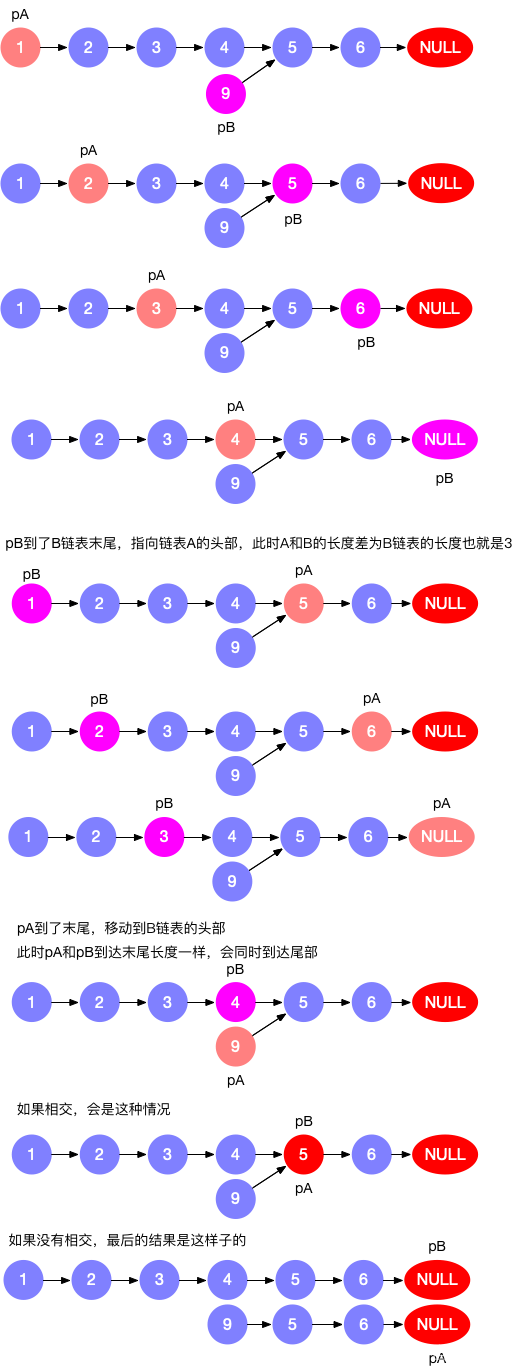
从尾到头也算一步,另一个指针跟着走一步
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode pa = headA, pb = headB;
while (pa != pb) {
pa = pa == null ? headB : pa.next; //pa可以为null 否则无公共点时不好返回
pb = pb == null ? headA : pb.next;
}
return pa;
}
169. 多数元素
408 真题,现在做就很水了,维护一个主元素,和计数器,必要时更新主元素即可
public int majorityElement(int[] nums) {
int provit = nums[0];
int count = 1;
for (int i = 1; i < nums.length; i++) {
if(nums[i]==provit){
count++;
}else {
if(count==1) provit = nums[i];
else count--;
}
}
return provit;
}
198. 打家劫舍
终于自己调出来了一个dp
public int rob(int[] nums) {
int n = nums.length;
int[] dp = new int[n];
dp[0] = nums[0];
for (int i = 1; i < n; i++) {
int a = i >= 2 ? dp[i - 2] : 0;
int b = i >= 3 ? dp[i - 3] : 0;
dp[i] = nums[i] + Math.max(a, b);
}
return Math.max(dp[n - 1], n >=2 ? dp[n - 2] : 0);//最后两个可能最大 (相邻两个维护最大)
}
滚动数组,优化空间:















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









