






前言
这几晚在看进程相关的内核原理,正好看到了pid这块,看起来不是很复杂,但是引入了pid namespace后增加了一些数据结构,看起来不是那么清晰了,参考了Linux内核架构这本书,看完后感觉还没有理解。所以就在网上找了一些文章参考,其中我发现了一篇质量相当不错的文章,为什么说质量不错呢主要是因为笔者在博文中并没有乱贴代码一桶,也没有按照常规的代码分析,而是以一种追踪溯源的方法还原了整个pid的框架,读了这篇文章后感觉甚好,因此有了本文,本文算不上原创,只是在此基础上将自己的理解重新进行了梳理,相关的图表进行了重绘,加入了一些数据结构的含义表述。关于这篇文章的链接可以参考附录A
PID框架的设计
一个框架的设计会考虑很多因素,相信分析过Linux内核的读者来说会发现,内核的大量数据结构被哈希表和链表链接起来,最最主要的目的就是在于查找。可想而知一个好的框架,应该要考虑到检索速度,还有考虑功能的划分。那么在PID框架中,需要考虑以下几个因素.
- 如何通过task_struct快速找到对应的pid
- 如何通过pid快速找到对应的task_struct
- 如何快速的分配一个唯一的pid
这些都是PID框架设计的时候需要考虑的一些基本的因素。也正是这些因素将PID框架设计的愈加复杂。
原始的PID框架
先考虑的简单一点,一个进程对应一个pid
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
是不是很easy,回到上文,看看是否符合PID框架的设计原则,通过task_struct找到pid,很方便,但是通过pid找到task_struct怎么办呢?好吧,基于现在的这种结构肯定是无法满足需求的,那就继续改进吧。
注: 以上的这种设计来自与linux 2.4内核的设计
引入hlist和pid位图
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
这样就很方便了,再看看PID框架设计的一些因素是否都满足了,如何分配一个唯一的pid呢,连续递增?,那么前面分配的进程如果结束了,那么分配的pid就需要回收掉,直到分配到PID的最大值,然后从头再继续。好吧,这或许是个办法,但是是不是需要标记一下那些pid可用呢?到此为此这看起来似乎是个解决方案,但是考虑到这个方案是要放进内核,开发linux的那帮家伙肯定会想近一切办法进行优化的,的确如此,他们使用了pid位图,但是基本思想没有变,同样需要标记pid是否可用,只不过使用pid位图的方式更加节约内存.想象一下,通过将每一位设置为0或者是1,可以用来表示是否可用,第1位的0和1用来表示pid为1是否可用,以此类推.到此为此一个看似还不错的pid框架设计完成了,下图是目前整个框架的整体效果.
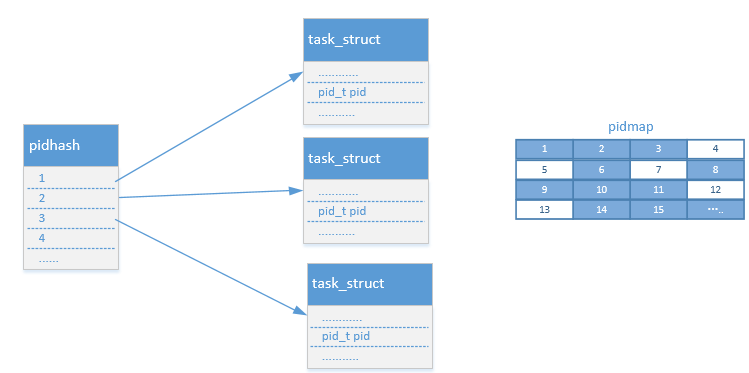
引入PID类型后的PID框架
熟悉linux的读者应该知道一个进程不光光只有一个进程pid,还会有进程组id,还有会话id,(关于进程组和会话请参考(进程之间的关系)那么引入pid类型后,框架变成了下面这个样子,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
对于进程组id来说,信号需要知道这这个id,通过这个id,可以实现对一组进程进行控制,所以这个id出现在了signal这个结构体中.所以直到现在来说框架还不是那么复杂,但是有一个需要明确的就是无论是session id还是group id其实都不占用pid的资源,因为session id是和领导进程组的组id相同,而group id则是和这个进程组中的领导进程的pid相同.
引入进程PID命名空间后的PID框架
随着内核不断的添加新的内核特性,尤其是PID Namespace机制的引入,这导致PID存在命名空间的概念,并且命名空间还有层级的概念存在,高级别的可以被低级别的看到,这就导致高级别的进程有多个PID,比如说在默认命名空间下,创建了一个新的命名空间,占且叫做level1,默认命名空间这里称之为level0,在level1中运行了一个进程在level1中这个进程的pid为1,因为高级别的pid namespace需要被低级别的pid namespace所看见,所以这个进程在level0中会有另外一个pid,为xxx.套用上面说到的pid位图的概念,可想而知,对于每一个pid namespace来说都应该有一个pidmap,上文中提到的level1进程有两个pid一个是1,另一个是xxx,其中pid为1是在level1中的pidmap进行分配的,pid为xxx则是在level0的pidmap中分配的. 下面这幅图是整个pidnamespace的一个框架
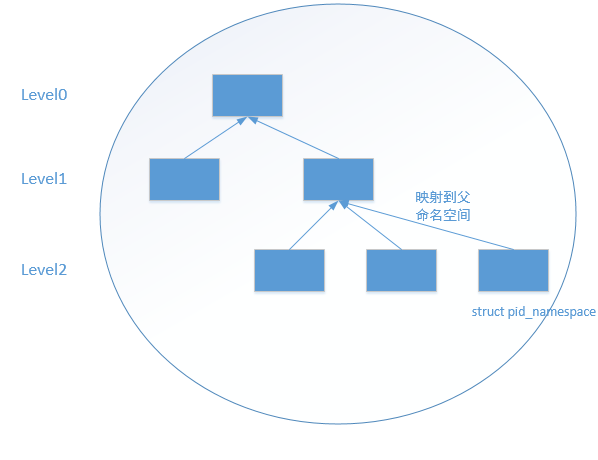
.引入了PID命名空间后,一个pid就不仅仅是一个数值那么简单了,还要包含这个pid所在的命名空间,父命名空间,命名空间多对应的pidmap,命名空间的pid等等.因此内核对pid做了一个封装,封装成struct pid,一个名为pid的结构体,下面是其定义:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
引入了pid namespace后,的确变得很复杂了,多了很多看不懂的数据结构.进程如何和struct pid关联起来呢,内核为了统一管理pid,进程组id,会话id,将这三类id,进行了整合,也就是现在task_struct要和三个struct pid关联,还要区分struct pid的类型.所以内核又引入了中间结构将task_struct和pid进行了1:3的关联.其结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
到此为止一个看起来已经比较完善的pid框架构建完成了,整个框架的效果如下:
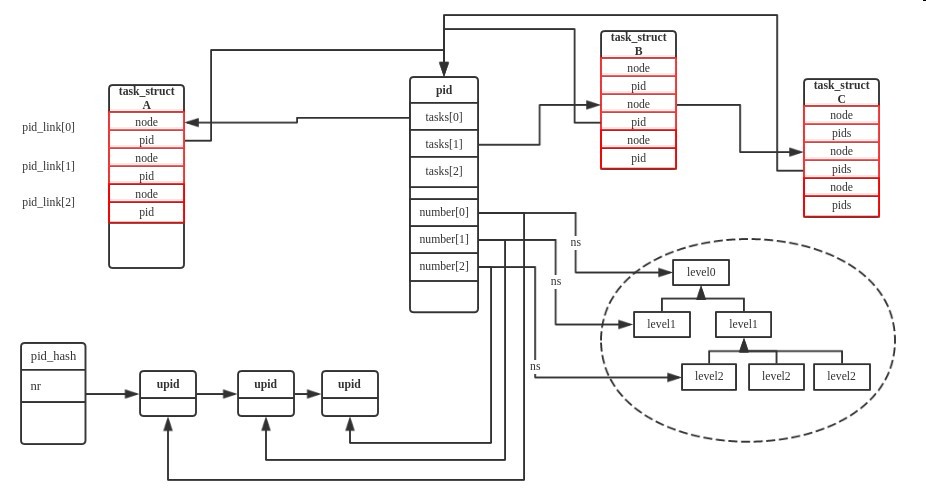
其中进程A,B,C是一个进程组的,A是组长进程,所以B,和C的task_struct结构体中的pid_link成员的node字段就被邻接到进程A对应的struct pid中的tasks[1].struct upid通过pid_hash和pid数值关联了起来,这样就可以通过pid数值快速的找到所有命名空间的upid结构,numbers是一个struct pid的最后一个成员,利用可变数组来表示这个pid结构当前有多少个命名空间.
注: 2016/08/28 修正上图的一个错误,pid_hash的key并不是nr,应该是
pid_hashfn(upid->nr, upid->ns)]唯一确定一个upid结构(具体可以参考pid_hashfn的实现),这样就可以通过nr和ns来找到其对应的upid结构了。
为了验证我们这个框架,下面是一些PID相关的函数,通过函数的实现来验证下这个框架.
进程PID相关的API分析
获取三种类型的pid结构
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
获取pid结构中的某一个名字空间的pid数值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
看看如何分配一个pid吧
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61















 1912
1912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









