 社区电商项目的Redis缓存架构实战
社区电商项目的Redis缓存架构实战




目录
025_社区电商的业务闭环知识讲解1
进入我们redis模块项目实战部分去了,前面20多讲,把redis内核级别的知识,做了一个深入的讲解,面试跳槽的时候,如果要是被问到redis,可以主动说,你研究过一些redis比较底层的实现原理,学到的东西说一说,还是挺有优势的
redis 完整的项目实战
基于redis作为主体技术,mysql和rocketmq作为一个辅助和配合,业务闭环的社区电商 社区电商,关键点在于社区->电商辅助性质(次要地位,流量变现),社区,分成很多种社 区,美食社区、美妆社区、影评社区、妈妈社区,社区平台有很多很多,中小型的居多,体育社区、汽车社区、本地生活社区
美食社区APP
大家可以在这个APP里分享自己积累的美食的一些食谱,网上看到的,也可以是自己做菜积累的食谱,食谱自己做菜的过程,分享,图文,视频,主题性质的,你自己对美食的看法,食谱,做菜的过程,出门吃饭体验的一些餐馆和美食,美食科普性,跟美食相关的,你很感兴趣,你积累的一些东西,体验的一些东西,都可以发出来给别人进行分享。这就是非常垂直化的电商APP,只关注与一个领域
浏览别人发出来的一些美食食谱、体验、经历、科普,看别人发的帖子,互动,关注,粉丝, 私信,交流,成为好友,跟平台里的好友,成立一个平台里的私密圈子,基于美食兴趣爱好,进行社交活动
美食社区APP,专门提供给别人来分享、浏览和社交活动,APP没法盈利,在这个里面会有一些人是产出的内容特比的优质,很多人来浏览,粉丝,读者,关注人,分享的东西,浏览量是非常大的,种草,发出来一个美食食谱和做法的帖子,你可以推荐一下某款酱油、某款味精,他的好处和优点,种草APP 提供,浏览你的帖子的人,他看到你推荐的商品,可以点击一个商品链接,直接进入商品详情页里去,浏览一下这个商品介绍,可以把这个商品加入自己的购物车里去,就可以直 接发起交易,完成商品购买。支付钱以后,APP可以找第三方商品提供方来合作,也可以自建仓库, 仓库里可以给你进行商品的发货
社区电商,依赖于社区的,KOL,意见大v他们会有很多粉丝和读者,他们会隆重推荐一下某款商品。用户购买商品支付的钱,会被分成3份,一份是用来商品购买和以及物流发货,一份是给 KOL 大v的,还有一份是给社区电商 APP,平台层面,他也得挣钱,整个业务流程就是这样
026_社区电商的业务闭环知识讲解2
社区电商APP的商业运作模式讲解了,商业模式。feed -> 给一些小动物喂东西吃 / 小婴儿小宝宝喂东西吃 -> 放在技术领域里面,feed流, feed技术,如果我们是一个用户,进入了APP,APP如果要做一个feed行为,他会主动的不停的在APP界面里提供各种各样的内容喂给我们,这就是APP主动feed的过程
feed流,APP不断的主动显示各种新的内容给我们,不断的显示出来的大量的新内容,就是feed 流,feed流特殊的场景和行为,没有feed流的,我们仅了一个APP之后,你想要看什么东西,都得自己主动浏览、自己搜索寻找。一页一页的浏览,浏览的是静态的、不动的内容
商品搜索项目,1亿个商品,我们可以主动搜索和浏览,一页一页的翻过去,我们也在不停的看APP里的内容,你自己主动的行为,内容都是你自己主动去找出来的,浏览出来的。
电商APP,首页,你也没搜索,条件,你就是不停在首页往下拉拉拉,每次拉的时候,电商APP 自己根据你过往的喜好、当前的爆款,算法,不停的显示出来一批新的内容给你看,这种就叫做电 商APP的feed流了。
feed 流,社区电商APP里,进入首页以后不停的拉拉拉,算法把你关注过的大v、可能感兴趣的美食帖子、浏览量高的爆款帖子,不停的计算出来新的一批内容显示给你。
今日头条、百度APP,你可以不停的刷新,不停的刷新,不停的刷新每次刷新,他都会根据算法自动给你推一批内容出来,他不停的喂东西给你,这种就是feed流行为。包括微博,别的社交平台,首页不停的刷新,他就不停的靠算法给你推荐一批一批的内容,这种都是feed流行为
027_社区电商的业务闭环知识讲解3
美食帖子、菜谱帖子,在这个平台里,所有的内容都是用户自己生产的,每个用户在这个里面都可以发布自己的美食分享、菜谱分享,海量内容,基于海量内容,就可以结合算法,不停的在首页推内容给你来看
对美食分享,可以基于条件(板块、分类)+ 分页,分页浏览指定范围的分享帖子,这种就不属于feed流了。这是对你的所有的美食数据,进行结构化的查询和分页浏览
用户在APP上看到的这些东西,都是属于类似于一个一个缩略图+标题,这种都属于是粗浏览,首页 feed 流、分页查询,当你对某个美食分享感兴趣的话,就可以点击进去看详情页,包含了你这次分享所有的内容,包括图文,视频,作者
028_社区电商的流量变现交易闭环讲解
小红书就是社区电商,内部不同的人,美妆达人,发布各种分享帖子,你可以去浏览,在帖子里可 以发评论,收藏,点赞,关注达人,社区电商APP来说,社区社交互动的东西给他做好了之后,APP里会有大量的流量,APP有多少注册用户、每天活跃的用户有多少人,这些都是属于你的平台里的流量
使用你的APP,需要技术团队开发,运营团队推广,客服团队来售后、成本、盈利,应该如何来做呢?引入电商,社区类的APP,最好的模式,种草,平时各种人发布分享的时候,可以在分享内容里插播一些对商品推荐,给出商品的链接
别人在里面浏览分享的时候,看到推荐的商品,链接,点击链接就可以进入商品详情页,商品标题、图文、视频、介绍、价格、营销活动、库存,加入购物车,购物车的多个商品发起一个提交订单,支付,履约拿到商品
029_社区电商的交易和履约闭环讲解
香菇滑鸡的制作帖子,里面有诱人的图片,以及制作的方法和过程,录了视频下来,做的特别好。 -> 推荐, 做出来的菜,为什么这么好吃呢,因为我用了xx品牌的酱油,用了原材料,经过九九八十一道工序来加工制作,倍儿香,如果想要做菜好吃,就用xx酱油 -> 酱油的链接,酱油商品缩略图、商品标题、价格、链接,点击 -> 酱油详情页里,具体介绍,图文+视频,复古工艺, 纯天然的原材料 -> 16.8一瓶,而且有活动买3赠1,干脆就买3瓶酱油得了,还能送一瓶 -> 把这个酱油商品点击加入购物车的按钮里去

030_基于社区电商APP原型图理解业务
具体内容见:/v1.0项目资料/社区电商案例全方案设计.pdf - 2. 1 . 1 ⾸⻚feed流展示菜谱
031_本次社区电商项目实战涉及模块讲解
彻底理解了社区电商业务闭环(社区闭环、电商闭环),完整的东西包含的模块太多了,我们最主要的是涉及到里面核心的模块:
首页feed流架构(只做工程架构,不涉及算法)、美食分享/美食查询浏览/详情页(缓存架构)、分享和活动、商品详情页、商品的库存(基于缓存的企业级)、购物车(基于缓存的企业级)。选择这些模块,围绕我们实战主题来的,redis项目实战
社交互动(点赞/评论/收藏/关注/私信)、交易闭环,这些就不会去涉及和开发了
032_Redis 缓存架构解决方案和生产实战
社区电商业务闭环的开发:首页feed流、美食分享/浏览/详情、社交分享和团购活动、商品详情/库存、购物车,主题都是基于mysql是基础,核心是基于redis开发一套企业级的缓存架构实现,rocketmq也是辅助和配合
基于redis为主体的架构,要上生产的,还需要考虑到各种各样的生产问题,这就需要一整套redis的解决方案, 结合社区电商业务进行落地
热key问题:比较典型的是微博,某个明星突然官宣恋爱/离婚,瞬时大量的人涌入那个明星的微博里去看,瞬时可能几十万百万、千万级的请求打到redis里一个节点中的一个key,这就是热key问题
对于我们来说,热key的情况,如果说我们要是有一个比较好的美食分享和团购活动,可能短时间内引发了大量的人把这个美食分享的详情页,给分享到了大量的微信社群、朋友圈里去,短时间内引发大量的人看一个美食分享的详情页,造成redis的热key出现
大value问题:存储的key对应的value特别的大,value多达10mb,这个value如果被读取的频繁一些,就可能会把你的网络带宽给打满,就会导致你别的请求会被阻塞。
如果说遇到了一些问题,某个数据因为各种原因,在缓存里就是查不到,短时间内有很多请求,都穿透到mysql层面去了,此时穿透问题如何处理;
缓存的过期和失效,缓存数据设置了过期的时间,到期失效了以后应该如何来处理
redis如果内存满了,LRU 算法自动淘汰了一些数据,对于这些数据我们应该如何进行处理
redis 集群都崩溃掉了,只有数据库可以访问,这个时候就需要自动识别缓存故障,立马进行限流,对数据库进行保护和防护,让数据库不要崩溃掉。另外立即启动各个接口的降级机制,各个接口,都可以提前在jvm内存缓存里,保存一些少量缓存作为降级备用数据,redis崩了以后,就去查 mysql,限流 -> 降级 -> jvm内存里缓存的默认数据来提供给用户 -> 降级以后的提醒也可以,每个接口都需要有一个降级方案
缓存数据和数据库之间的一致性的保障,双写、异步同步。异步同步如何保证一致性
redis 解决方案:结合业务场景落地,热key和大value,就是比如某个key形成了热点,还 有大value,缓存穿透、失效和LRU被清理 -> 缓存自动加载和重建、雪崩(缓存一旦故障, 自动限流避免数据库被打死)、和数据库的一致性保障
redis 生产实战:上了生产以后,就是模拟出足量的数据灌入redis里,因为都是社区里的人 自发发的这种,可以给大量的数据,比如redis集群部署、然后千万级数据量放redis里,然后就是高并发压测,cachecloud监控运维,可以看到多少个缓存节点、里面放了多少GB的数据、每个节点多少GB、大压力下接口性能如何、QPS多少、redis机器负载如何、缓存命中率如何、数据库回源比例是多少、再就是一些运维,比如redis节点故障的主从切换演示, redis集群扩容演示
033_基于数据库与缓存双写的美食分享功能
业务闭环开发过程中,会大量的运用到我们的redis缓存架构。cookbook就是菜谱/美食分享,美食、标题、介绍、做法、原材料、视频,社交互动,商品种草,社交分享和团购活动
发表一次美食分享、对应代码里的cookbook菜谱创建接口,美食分享都是有一个作者userId,在你发表美食分享之前,你自己作为一个 用户就得先注册和登录到APP里去,你发表的时候,你自己的账号id,就是你的美食分享的userid
平台来说,有的可能是一些个人用户发表的分享,也有的可能是专业的机构/公司,他们有很强的原创美食内容的生产能力,组成了一个公司,专门在各个平台里发布美食类的原创内容,吸引粉丝,自己的内容流量足够大的时候,就可以开始种草->卖商品->流量变现,各个平台里都是很典型的一种商业模式,任何普通人和任何专业公司,注册到平台之后,都可以在这里发表美食分享
034_社区电商APP用户管理功能实现
美食分享核心数据模型 -> 要发表美食分享 -> userid -> 作者 -> 美食电商 APP 用户管 理功能,用户注册、登录 -> 模拟接口,接口可以加入一个社区电商APP的用户
把我们的社区电商APP用户数据在redis缓存里去写一份,并生成随机的过期时间,把用户数据写入到缓存里去,每条用户数据都会在redis里缓存个2天+随机个几个小时的过期时间。用户数据后续高并发读取的时候,就是可以直接从缓存里提取用户数据,用户数据一般是不会变化的。
第一次注册,偶尔修改,写少读多,写0.01%,读99.99%,非常适合用缓存来支持用户数据高并发。设置过期时间,用户数据可能不是说经常会被读取的,有些用户是冷门个人用户,他发表的东西,一般不会有人经常看。默认来说,2天多过期掉,如果后面有人要访问,缓存里没找到数据,从库里加载出来写缓存就可以了。如果经常会读某个用户,则可以不断的延长他的过期时间
同时这个线程在这里,把新数据写入了redis缓存里,此时我认为没问题的,缓存是最新的
035_热门用户数据的缓存自动延期机制
用户数据是写少读多的场景,对用户数据在创建时时候做一下缓存是非常合适的,在各种场景下,读取用户数据就直接从缓存里加载,埋了一个伏笔,用户数据在缓存的时候,过期时间,随机的2天多的时间
少数的用户是热门的,他发表的分享是很多人会看到的,大部分用户他的用数据是冷数据, 一般都没什么人会去care他们发表的内容,没有必要说让所有的用户数据都驻留在缓存里, 占用缓存宝贵的内存空间。没什么人访问这个用户数据,让他默认过期掉就可以了,后续如果真有访问,从数据库里回源,写入到缓存里就可以了;
热门用户数据来说,很多人去访问,每次访问用户数据,我们做一个机制,缓存自动延期设计,过期时间都会延长上一次写入数据:1月1号,expireTime=1月3号,到1月3号有人访问了他,过期延期, 1 月5号,下次在2天多内有人来访问,几乎一直可以从缓存里加载到用户数据,热门据基本都可以从缓存来读取,实现高并发读
冷门的用户数,如果连续2天多没人读取他,expire过期掉了,只能从db里读取,回源数据库里读取,读取完毕了以后,还要再次写入缓存里去

代码地址:E:\儒猿课堂\Redis\4.模块四 基于社区电商场景的Redis缓存架构实战_1- 架构\资料\v1.0项目资料\careerplan-eshop-redis
036_缓存惊群与穿透问题的解决方案
用户数据写入和查询,缓存设计,写入的时候,库+缓存,双写,缓存默认2天多随机时间 的过期,读的时候因为有读延期机制,如果频繁的读,缓存会不停的延期。没有人查呢,会过期从而避免占用缓存的空间,缓存没查到,从数据库里提出来,放到缓存里去
每次写入缓存的时候,为什么一定要设置2天+随机几个小时的时间呢? 答案是为了解决缓存惊群的问题,缓存一批数据同时过期,突然之间一起都没了,过期时间设置的都是一样的,这就是缓存集群都惊了,数据库也惊了,大量缓存同时过期->惊群 ->瞬时大量请求走到mysql,造成压力
解决方案:大量的缓存数据,过期时间都是随机,不要集中在某个时间点一起过期

惊群,典型的术语,突然在某个时间点,出了一个故障,一大片范围线程/进程/机器, 都同时被惊动了,惊群效应
缓存穿透的一个问题,穿透->读取缓存没读到->从db里读->db也没读到->程序bug或者被外部攻击->高并发的读一个数据,缓存和db都没有->每次高并发读取,缓存都会被穿透过去,每次都要读一下db,导致高并发空请求都针对db在走,造成db压力

缓存穿透是指查询一个不存在的key,由于缓存中没有数据,因此会直接查询数据库。如果每次都查询一个不存在的key,那么会导致大量的请求直接到达数据库,从而导致数据库繁忙,甚至宕机的情况。下面是几种避免缓存穿透的方式: 1、布隆过滤器:将所有可能的查询key哈希到一个足够大的bitmap中,如果某个key对应的bitmap值为0,则该key不存在,直接返回;否则可能存在,再进行进一步查询。 2、缓存空对象:对于那些在数据库中不存在的key,在缓存中也缓存一个空对象,这样就不会频繁地查询数据库。 3、设置过期时间:对于查询数据库中不存在的key,在缓存中设置一个较短的过期时间,这样可以避免在一段时间内频繁地查询数据库。 4、熔断器:在缓存中未命中的情况下,可以启动熔断器,暂时停止对该key的请求,直到缓存中有了数据再恢复请求。 为了避免缓存穿透,可以采取多种措施,需要根据实际情况选择适合自己业务场景的方案。
037_基于分布式锁的缓存+数据库双写一致性
缓存+数据库双写的时候,保证一致性,应该如何来确保?他们的一致性,考虑他们如果不一致,是一个什么样的场景?
写缓存可能是在两个场景里发生:第一个是,纯数据库+缓存的双写,也就是用户注册或者用户信息修改时,会同时写数据库和缓存;第二个是,读取用户信息的时候,如果说缓存没读到,就会 读库,读完库再写缓存;
写缓存是两个场景,这两个场景可能并发的产生。那么可能线程B过来,刚好缓存过期,线程B从数据库中读出用户姓名为张三,在准备将张三写入缓存时发生线程切换,此时线程A过来修改用户信息,将用户姓名从张三换成了张小三,并将张小三同时写入了数据库和缓存,最后线程B苏醒过来,又会将旧的“张三”写入缓存,从而覆盖新的“张小三”数据,从而造成数据库和缓存的不一致
这里也得出一个结论,分析并发数据的不一致性时,一定要分析修改数据有哪些源头,比如上面修改缓存就有两个场景,就从两个场景并发执行去分析可能引起数据不一致的情况
038_基于分布式锁的缓存+数据库双写一致性
写缓存 有一个简单易行的方案,读和写,必须是串行化的,经典方案,加分布式锁
用户数据,0.01%是写,99.99%是读,用户注册和信息更新,操作是极为极为少的,平时大部分都是对用户数据做一个查询,美食分享的详情页里,feed流页面,美食分享要查询你的用户信息,比如作者名称
039_缓存+数据库双写分布式锁高并发优化
不知道为什么,可能我们某个作者平时是很冷门的,用户数据早就过期了,突然之间火了, 一瞬间涌入了大量的人来查询他,从而高并发的读已过期的缓存,大量的线程都没从redis中读到谁,从而导致大量的线程都涌入了load db+write redis 这个getUserInfoFromDB()方法里面

上面132行的代码,分布式获取锁的方法,是没有加超时时间的
040_分布式锁自动超时串行转并发机制
大量线程高并发读取某个已经过期的key,最多也就在分布式锁那里阻塞一秒种左右,有部分线程可以在1s之内读取数据返回,超过1s还没读到数据,还在阻塞的线程,1s过后全部都会串行转并发,读到数据返回了。积压个几秒钟,几十秒,这种情况是不可能会出现的
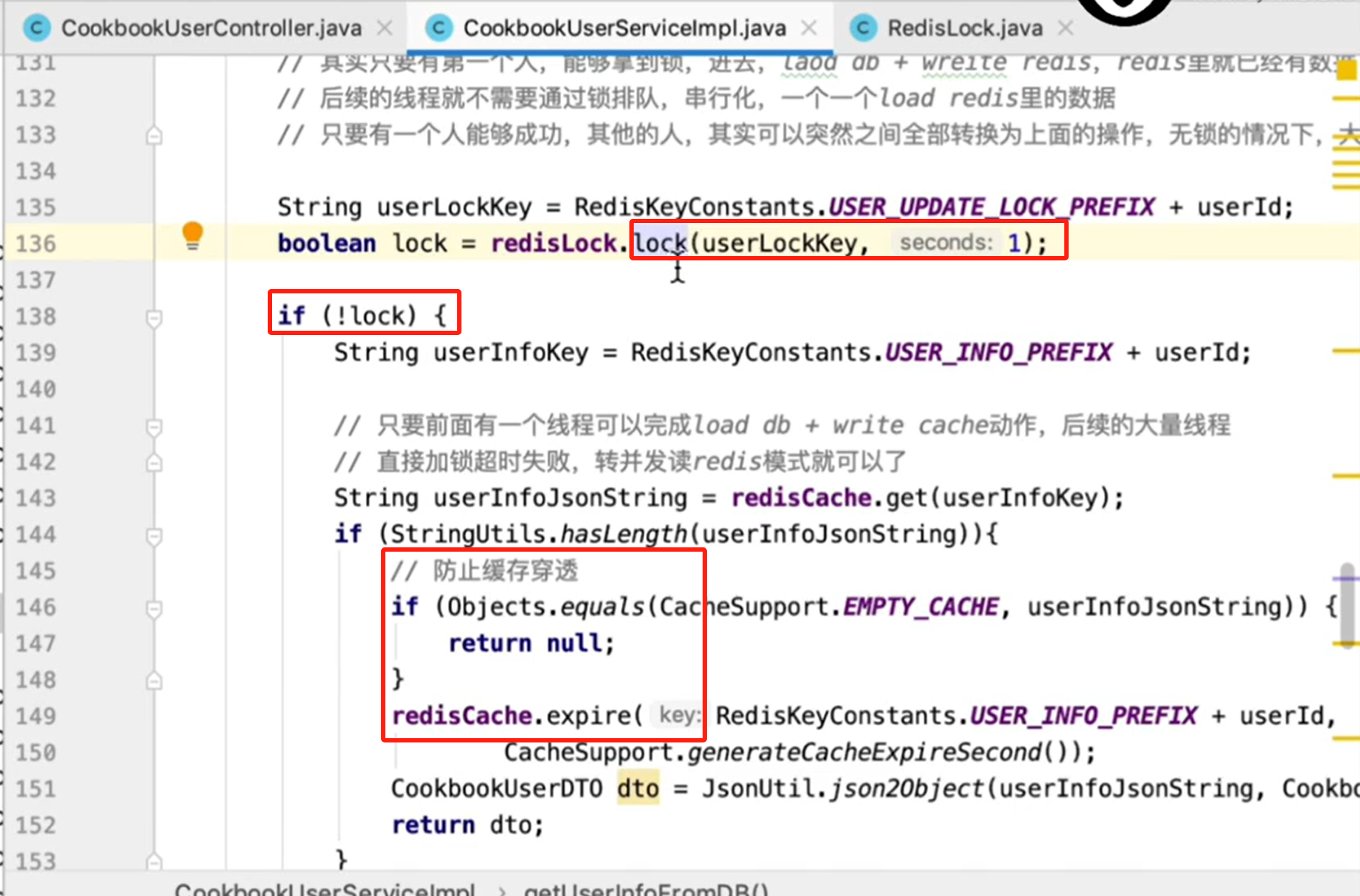
没有抢到锁的,直接在143行,重新去读一次redis,防止多个线程每个都重复的等待获取锁,获取到锁都会走一遍先查DB再回写redis的过程
041_数据库+缓存双写一致代码重构
抽象出了一个通用的getUserFromCache(Long userId)方法
private CookbookUserDTO getUserFromCache(Long userId) {
String userInfoKey = RedisKeyConstants.USER_INFO_PREFIX + userId;
String userInfoJsonString = redisCache.get(userInfoKey);
log.info("从缓存中获取作者信息,userId:{},value:{}", userId, userInfoJsonString);
if (StringUtils.hasLength(userInfoJsonString)){
// 防止缓存穿透
if (Objects.equals(CacheSupport.EMPTY_CACHE, userInfoJsonString)) {
// 缓存穿透后返回空对象
return new CookbookUserDTO();
}
redisCache.expire(RedisKeyConstants.USER_INFO_PREFIX + userId,
CacheSupport.generateCacheExpireSecond());
CookbookUserDTO dto = JsonUtil.json2Object(userInfoJsonString, CookbookUserDTO.class);
return dto;
}
return null;
}
private CookbookUserDTO getUserInfoFromDB(Long userId) {
// 有两个选择,load from db + write redis,加两把锁,user_lock,user_update_lock
// 基于redisson,加多锁,multi lock
// 共用一把锁,multi lock加锁,不同的锁应对的是不同的并发场景
// String userLockKey = RedisKeyConstants.USER_LOCK_PREFIX + userId;
// 有大量的线程突然读一个冷门的用户数据,都囤积在这里,在上面大家都没读到
// 都在这个地方在排队等待获取锁,然后去尝试load db + write redis
// 非常严重的锁竞争的问题,大量的线程就会串行化,一个一个的排队,先拿锁,load一次db,再写缓存
// 下一个人拿到锁了,通过double check,直接读缓存,下一个人,短时间内突然有一个严重串行化,虽然每次读缓存,时间不多
// 其实只要有第一个人,能够拿到锁,进去,laod db + write redis,redis里就已经有数据了
// 后续的线程就不需要通过锁排队,串行化,一个一个都走相同的重复的流程:load redis里的数据
// 只要有一个人能够成功,其他的人,可以突然之间全部转换为上面的操作,无锁的情况下,大量的一起并发的读redis就可以了
String userLockKey = RedisKeyConstants.USER_UPDATE_LOCK_PREFIX + userId;
boolean lock = false;
try {
lock = redisLock.tryLock(userLockKey, USER_UPDATE_LOCK_TIMEOUT);
} catch(InterruptedException e) {
CookbookUserDTO user = getUserFromCache(userId);
if(user != null) {
return user;
}
log.error(e.getMessage(), e);
throw new BaseBizException("查询失败");
}
if (!lock) {
// double check
CookbookUserDTO user = getUserFromCache(userId);
if(user != null) {
return user;
}
// 本次查询失败,用户可以自行后续发起重试再查一次就好了
log.info("缓存数据为空,从数据库查询作者信息时获取锁失败,userId:{}", userId);
throw new BaseBizException("查询失败");
}
try {
// double check
CookbookUserDTO user = getUserFromCache(userId);
if(user != null) {
return user;
}
log.info("缓存数据为空,从数据库中获取数据,userId:{}", userId);
String userInfoKey = RedisKeyConstants.USER_INFO_PREFIX + userId;
// 在这里先读到了db里的用户信息的旧数据
// 这个线程刚刚读到,还没有来得及把旧数据写入缓存里去
CookbookUserDO cookbookUserDO = cookbookUserDAO.getById(userId);
if (Objects.isNull(cookbookUserDO)) {
redisCache.set(userInfoKey, CacheSupport.EMPTY_CACHE, CacheSupport.generateCachePenetrationExpireSecond());
return null;
}
CookbookUserDTO dto = cookbookUserConverter.convertCookbookUserDTO(cookbookUserDO);
// 此时这个线程,在上面的那个线程都已经把新数据写入缓存里去了,缓存里已经是最新数据了
// 把旧数据库,写入了缓存做了一个覆盖操作,典型的,数据库+缓存双写的时候,写和读,并发的时候
// db里是新数据,缓存里是旧数据,旧数据是覆盖了新数据的
// db和缓存,数据是不一致的
redisCache.set(userInfoKey, JsonUtil.object2Json(dto), CacheSupport.generateCacheExpireSecond());
return dto;
} finally {
redisLock.unlock(userLockKey);
}
}注意,分布式锁申请锁的超时时间,只设置为了200ms,200ms对正常的业务执行够用了;注意读的时候的double check机制
042_写少读多的企业级缓存架构设计总结
通过我们社区电商开发的第一个小模块,用户数据写和读模块,针对小模块引出了 一堆的问题,用户数据,写少读多的场景,写:用户注册+用户更新信息占0.01%,99.99%都是在高并发的读,大量的读场景,美食分享详情页、浏览,大量的高并发的读取作者信息,99.99%是在读取
引入redis缓存,是非常有必要,读可能是高并发的,大量用户在浏览,没有必要都去从db里读取,读缓存就可以了
写库的时候,如何写缓存,数据库和缓存如何同步更新?异步最终一致性写缓存;数据库+ 缓存,同步双写,数据库+缓存双写,比较简单
写/更新的时候,库和缓存一起更写,需要设置过期时间,为什么要设置过期时间?让缓存里就留下热数据就可以了,冷门作者没人看的, 就直接过期掉,热门的作者有人看的,就保留在缓存里 过期时间 -> 冷热分离 -> 冷数据停留在mysql里,热数据停留在redis里读的时候,就是,每次读自动expire延期,热数据一直保留在缓存里,冷数据如果没从缓存读到, 就load db + write cache
完整的企业级的解决读多写少场景下的数据库+缓存双写,数据库+缓存双写 + 冷热分离(过期时间+自动expireTime延期)+ load db&write cache + 缓存惊群解决方案(随机过期时间) + 缓存穿透解决方案(db load null -> cache empty data)+ 数据库&缓存一致性方案(写和读,分布式锁+读double check)+ 分布式锁串行转并发方案(读操作的分布式锁,tryLock,自动超时)
043_基于数据库+缓存双写的美食菜谱分享功能
用户数据读多写少的场景,通过数据库+缓存双写、缓存延期的冷热分离、缓存惊群+缓存穿透、数据库和缓存一致性 + 分布式锁串行转并发 -> 数据库+缓存双写的企业级解决方案
社区电商app里,有注册成功了一个用户了以后,该用户就可以发布美食分享,此时就需要代码提供菜谱的创建/发布,和菜谱的更新接口
044_菜谱列表缓存的查询时延迟构建
作为一个用户发布了菜谱,仅仅是把这个菜谱写了一个kv到redis里去,用户可以去分页查询自己发布出去的菜谱列表,或者说,以后可能有别人来关注了你以后,进入到你的用户页面里去,可以分页查询浏览你发布过的菜谱。
对指定用户发布过的菜谱,去进行分页浏览,是一个操作。如果说我们要对一个用户发布过的菜谱进行分页查询,需要用redis里面list类的数据结构。
为什么我们在发布菜谱的时候,没有把菜谱数据直接写入到list类的数据结构里去呢?
如果写入了,后续就可以基于这个list类的数据结构进行你发布过的菜谱数据分页查询。用户数据 -> 写少 -> 读很多(冷热两种数据) 。菜谱数据,指定用户的菜谱列表分页查询,当你发布完一个菜谱数据以后,不是每个人都会不停的去对你发布过的所有的菜谱数据,一页一页的去翻页去查看的,每个人发布过的菜谱数据其实很多,如果说要是把菜谱列表一直放在redis里,对内存消耗很大的
针对list数据结构里去,后续别人会不会对你发布过的菜谱数据一页一页的去看是不一定的,你自己发布完菜谱数据以后的,可能会大概看一眼菜谱列表,别人也不一定会来看了。菜谱列表数据对内存消耗是比较大,有多少人浏览分页列表、都是不一定的,所以,没有必要刚开始就把菜谱列表数据维护的redis的list数据结构中去。而是把这个菜谱列表缓存构建,延迟到有人真的要来浏览菜谱列表,你自己或者是别人,第一次有人要浏览,把菜谱列表缓存构建好,在短时间内,继续来浏览
lRange()函数,进行redis的list结构的分页查询
045_惰性分页缓存构建方案如何节约内存
基于redis 玩企业级的缓存分页查询,写入数据的时候,是不会直接写入到一个list结构里去的,千万级用户群体,每天都有很多人在发布菜谱,每个人发布过的历史菜谱数据很多,很多历史菜谱数据,可能根本就没人会通过redis list分页查询
有一个人可能发布过了100,1000个菜谱,每页显示的是20个菜谱,5页,50页,你自己也不会一页一页的翻,翻到第五页,别人可能更不会看到第五页,也不会去看到50页,根本没有这种情况,你要在redis里维护一个常驻内存的分页list,把每个人历史发布过的菜谱数据都保存在list里,没有这个必要
考虑每个数据是否有必要写缓存或者有没有必要立刻写缓存,用户数据的缓存,随机过期时间+读缓存延期+冷热分离,把经常被访问的数据驻留在redis里,不是阿猫阿狗都直接往redis里去放,常驻内存,没有这个必要, 对不对
分页的时候,我们前端页面里,不支持任意页面的页码的跳转,只能说通过上一页和下一页,两个按钮,上翻和下翻,不允许你12345 10的页码,你任意点击一页。
在数据没有任何更新之前,有人来进行查询,每次查一页构建一页缓存就可以了,慢慢的缓存list 构建的多了以后,有人在过来,就是可以直接从list缓存里去查看到数据了。第一页开始,一页一页翻,分页的时候惰性的构建缓存list,也就是查到哪一页,才开始构建某一页;
046_按页拆分缓存key实现精准过期控制
立马就把所有的历史数据都加载到缓存里来进行构建,浪费缓存里面的内存,所以一般都会采用惰性构建的玩法,发布菜谱数据是一种低频的行为,不会说一直有人频繁的发布菜谱数据,每个人 每天能发布一次新的菜谱,都算非常好了,这种都已经算是大v了。专业大v每天发布一次新的菜谱数据,就非常好了。
没有必要把历史菜谱list都放在内存里。我自己或者是别人,来分页浏览我发布过的菜谱list,别人查一页,构建一页的缓存,list 结构来保存。目前实现,有两个缺点,以目前的代码实现来说,前端界面里没有办法让人来选页,list 里的数据顺序是按一页一页的顺序来存的。随着有人一页一页的翻过去,缓存数据都构建好了,又会导致分页list数据在缓存里常驻,就是他没有办法自动过期。如果针对list key指定了过期时间,菜谱list的第一页,第二页,第三页,频繁的访问不需要进行过期,后续的一些页才需要进行过期的分页
所以,list数据结构需要拆分,每一页数据就是一个key value对,针对每一页数据精准的设置过期时间,如果有的页一直没人访问,就让他自己过期就可以了,频繁有人访问的页, 就自动去做过期时间延期
047_精准分页缓存构建的代码逻辑实现
每次分页查询,当前userId所发布过的菜谱数量总和count,是需要每次分页查询的时候都要用到的,需要根据count精准计算出这个用户当前有多少页的菜谱,才能在前端显示菜谱list的页码。每个userId对应的菜谱count,其实是可以做到常驻内存里的(每次发布新菜谱时,都往内存中写入当前用户的菜谱count总和值 ),给这个count设置过期时间也没问题,读到了这个count就给它作一次延期过期,count占用不了多少内存空间。但是对于菜谱list不一样,如果每个用户都保存菜谱list,菜谱list可能会占用很多内存空间
048_菜谱多key分页缓存的异步更新
我们先不停的去插入一些菜谱数据到db里面去,接下来我们就不更新数据了,此时再分页查询菜谱list的时候,查第几页,就把第几页的缓存构建并设置随机过期时间,经常被访问的菜谱页缓存就会常驻,不经常访问的就会自动过期淘汰掉。
菜谱分页list构建好了之后,又插入一些新菜谱数据,就会导致我们之前构建的那些分页缓存都会失效掉,数据一旦变化,每一页数据都会变化,不管之前我们构建过多少页缓存,此时就会全部失效掉,我们对他们全部进行重建会比较耗时一些
每一页在redis里缓存的,都必须对那一页的数据,到我们的db里重新查一下,查到后再对每一页在缓存里的数据进行重新的更新,这肯定是比较耗时的,所以耗时的操作就必须采取异步操作
如何进行分页菜单的异步构建
用户发布一个新的菜单时,会发出一个MQ消息通知,然后自己写一个listener监听这个消息,执行分页菜单在redis内存中的更新逻辑
log.info("执行作者菜谱缓存数据更新逻辑,消息内容:{}", messageExt.getBody());
String msg = new String(messageExt.getBody());
CookbookUpdateMessage message = JsonUtil.json2Object(msg, CookbookUpdateMessage.class);
Long userId = message.getUserId();
String cookbookUpdateLockKey = RedisKeyConstants.USER_COOKBOOK_PREFIX + userId;
redisLock.blockedLock(cookbookUpdateLockKey);
try {
// 这个时候我们需要在这里对userid的菜谱list页缓存都去做一个重建
String userCookbookCountKey = RedisKeyConstants.USER_COOKBOOK_COUNT_PREFIX + userId;
Integer count = Integer.valueOf(redisCache.get(userCookbookCountKey));
int pageNums = count / PAGE_SIZE + 1;
for(int pageNo = 1; pageNo <= pageNums; pageNo++) {
String userCookbookPageKey = RedisKeyConstants.USER_COOKBOOK_PAGE_PREFIX
+ userId + ":" + pageNo;
String cookbooksJson = redisCache.get(userCookbookPageKey);
if(cookbooksJson == null || "".equals(cookbooksJson)) {
// 缓存中可能只有某几页数据,不是此用户的所有数据都在redis缓存中的
continue;
}
// 缓存中确实有这一页数据,此时就需要对这一页数据缓存去进行更新
List<CookbookDTO> cookbooks = cookbookDAO.pageByUserId(userId, pageNo, PAGE_SIZE);
redisCache.set(userCookbookPageKey,
JsonUtil.object2Json(cookbooks),
CacheSupport.generateCacheExpireSecond());
// 只要缓存异步实现了更新操作,用户发表完了菜谱以后,去菜谱list分页,但凡是之前有缓存的page
// 都会看到page最新的数据,就算是有一些延迟,也不会太高的
}
} finally {
redisLock.unlock(cookbookUpdateLockKey);
}
注意这里不是该用户的所有数据库中的菜单都重建到redis中去,而是只有redis中有的页码分页,才会被重新构建分页
因为菜谱更新后,菜谱分页缓存的更新逻辑比较耗费资源,所以,这种更新或者新建菜谱后的缓存分页数据重建,只适合读多写少的场景
049_菜谱分页数据的DB与缓存不一致问题
此时又出现了并发更新缓存,导致数据库和缓存不一致的问题;
更新菜谱的时候,会发出MQ导致redis中的每一页缓存都会重建、外部读取page的时候,也可能会去更新的页缓存。不做任何的措施的话,导致两个地方都有菜谱page缓存写入的操作,并发的问题
举例
当线程A去查询用户jack的第1页菜谱,用户jack的第1页菜谱还未在缓存中构建或者刚好第1页菜谱过期了,此时线程A就会去DB中查出第1页菜谱的数据库旧数据,在准备将这第1页菜谱的数据库旧数据回写到redis之前,线程B执行了用户jack的一次菜谱M的新增,并发出了用户Jack菜谱新增的MQ,消费此MQ准备进行redis中的分页菜谱缓存重建时,发现用户Jack在redis中的第1页缓存不存在(还未在缓存中构建或者刚好第1页菜谱过期了),所以此时缓存重建也会跳过第1页的重建,因为只重建redis中存在页码对应的分页缓存数据。最后,线程A将第1页菜谱的数据库旧数据回写到redis中
此时就会出现一个问题,缓存中是第1页旧数据,旧分页数据是不包含线程B执行了用户jack的一次菜谱新增进数据库的菜谱M的,而数据库中,此时已经有了菜谱M。最终的结果是,2天多之内,有人访问用户Jack的第一个菜谱分页page缓存,读到的都是旧数据,没包含你最新发布的菜谱M
050_DB 与缓存的分页数据一致性方案
通过分布式锁解决,让新增/修改菜谱接口,和listCookbookInfoFromDB()方法共用同一把分布式锁lock-A。当pageNo对应在redis中的那一页缓存刚好过期,此时有当前pageNo对应的分页的查询进来时,开始执行listCookbookInfoFromDB(),内部先获取分布式锁lock-A,然后去数据库中通过userId和pageNo查询某一页旧的菜谱数据并准备去回写redis中的那一页缓存时,是不允许新增菜谱接口来往数据库中插入新的菜谱数据的。新增接口获取分布式锁时,如果发现当前分布式锁正在被占用,那么当前新增接口对应的线程会立刻返回,不会阻塞式等待分布式锁,通过这种fail fast快速失败的机制,让用户自己去再次重试执行菜谱的新增
当listCookbookInfoFromDB()去数据库中通过userId和pageNo查询某一页旧的菜谱数据并已经回写完redis中的那一页缓存,此时缓存中会由pageNo对应的那一页旧数据,最后释放分布式锁。然后用户点击新增菜谱,接口成功获取分布式锁,从而往数据库中插入一条新的菜谱数据,并发送了一条新增菜谱的MQ通知
在listener成功处理完这条MQ之前,用户如果会有新的pageNo对应的分页的查询进来,此时,也会从redis缓存中查到pageNo对应的那一页旧数据,从而产生短暂的redis和db中的菜谱数据的不一致,但是不要紧,在listener成功处理完这条MQ之后很快就会恢复一致
listener拿到这条MQ后,同样会去分布式锁lock-A,此时拿到分布式锁lock-A是很快的,因为用户刚执行了菜谱新增,也不会再有新的新增去抢分布式锁lock-A,另外如果有新的pageNo对应的查询进来,因为redis中有pageNo对应的那一页旧数据,则直接走到redis就返回这一页旧数据了,不会进一步走到listCookbookInfoFromDB()
listener处理这条MQ,拿到分布式锁lock-A后,发现redis中有pageNo对应的那一页旧数据,则直接从数据库中取出pageNo对应的那一页新数据,并更新redis,此时数据库和redis中的pageNo对应的那一页缓存数据,也就再次保持一致了。后续,如果有新的pageNo对应的查询进来,都会从redis中取到pageNo对应的那一页新数据
新增菜谱接口先拿到锁从而往数据库中插入一条新菜谱,并发出了通知MQ。后续listener先拿到锁发现redis中没有pageNo对应的那一页缓存则直接跳过,什么都不做就释放锁。最后listCookbookInfoFromDB()拿到锁从而从数据库中取出带有最新菜谱的分页数据,并回写到redis中去
新增菜谱接口先拿到锁从而往数据库中插入一条新菜谱,并发出了通知MQ。后续listCookbookInfoFromDB()先拿到锁从而从数据库中取出带有最新菜谱的分页数据,并回写到redis中去。listener最后拿到锁发现redis中有pageNo对应的那一页缓存则又去数据库中查一次,还是会把带有最新菜谱的分页数据查出来并回写到redis中
总之,在以上三种场景下,最终都会保持redis和db的分页缓存数据一致
实际上,只需要listCookbookInfoFromDB()和listener保持同一把分布式锁就够了,新增菜谱接口不需要和前两者保持同一把分布式锁,具体分析流程同上
051_热门作者第一页缓存失效串行转并发
惰性分页缓存构建、按页拆分缓存、页缓存读延期(页冷热分离)、异步更新页缓存、数据库和缓存的一致性、分布式锁串行转并发
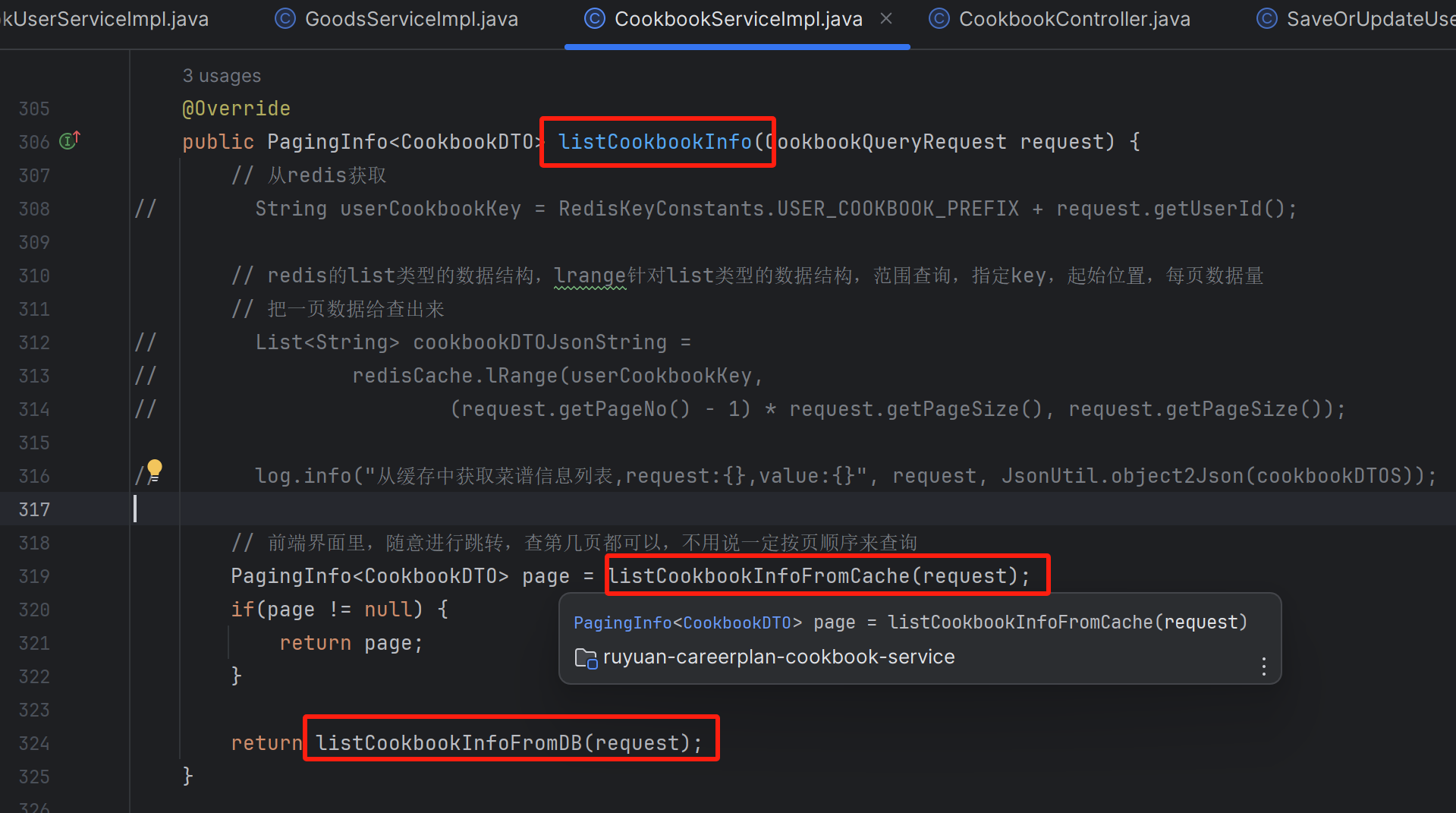
private PagingInfo<CookbookDTO> listCookbookInfoFromDB(CookbookQueryRequest request) {
String userCookbookLockKey = RedisKeyConstants.USER_COOKBOOK_PREFIX + request.getUserId();
boolean lock = false;
try {
lock = redisLock.tryLock(userCookbookLockKey, USER_COOKBOOK_LOCK_TIMEOUT);
} catch(InterruptedException e) {
PagingInfo<CookbookDTO> page = listCookbookInfoFromCache(request);
if(page != null) {
return page;
}
log.error(e.getMessage(), e);
}
if (!lock) {
// 没有抢到锁的其余线程,都直接串行转并发,再去并发的去redis中读取分页数据
PagingInfo<CookbookDTO> page = listCookbookInfoFromCache(request);
if(page != null) {
return page;
}
log.info("缓存数据为空,从数据库查询用户菜谱信息时获取锁失败,userId:{}", request.getUserId());
throw new BaseBizException("查询失败");
}
try {
// double check
PagingInfo<CookbookDTO> page = listCookbookInfoFromCache(request);
if(page != null) {
return page;
}
log.info("缓存数据为空,从数据库中获取数据,request:{}", request);
LambdaQueryWrapper<CookbookDO> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.eq(CookbookDO::getUserId, request.getUserId());
int count = cookbookDAO.count(queryWrapper);
// 这里是从db里查到的一页数据
List<CookbookDTO> cookbookDTOS =
cookbookDAO.pageByUserId(request.getUserId(), request.getPageNo(), request.getPageSize());
// 基于redis的list数据结构,rpush,lrange
// 把你的用户发布过这一页数据,给怼到list数据结构里去
// 此时在list缓存里,仅仅只有第一页的数据而已,惰性分页list缓存构建
// redisCache.rPushAll(userCookbookKey, JsonUtil.listObject2ListJson(cookbookDTOS));
// 第一页的page缓存是没有包含刚才写入最新数据,旧数据
// 数据库和缓存不一致了
// 2天多之内,有人访问第一个page,缓存,读到的都是旧数据,没包含你最新发布的新数据
String userCookbookPageKey = RedisKeyConstants.USER_COOKBOOK_PAGE_PREFIX
+ request.getUserId() + ":" + request.getPageNo();
redisCache.set(userCookbookPageKey,
JsonUtil.object2Json(cookbookDTOS),
CacheSupport.generateCacheExpireSecond());
PagingInfo<CookbookDTO> pagingInfo =
PagingInfo.toResponse(cookbookDTOS, (long) count, request.getPageNo(), request.getPageSize());
return pagingInfo;
} finally {
redisLock.unlock(userCookbookLockKey);
}
}注意上面的double check和串行转并发的代码写法
有一个极端场景:用户新增成功一个菜谱,同时pageNo对应的旧分页数据在redis中过期了,然后listener先抢到锁会什么都不做,后续,同时有大量线程来读取pageNo对应的分页菜谱,那么大量线程会进入listCookbookInfoFromDB(),进入后只有一个线程能拿到锁并从数据库中取出带有最新菜谱的分页数据回写redis,另外的所有线程无非就是等第一个线程释放锁后抢到锁,从而进去double check逻辑从redis中取出最新pageNo对应的分页数据,或者抢锁失败,导致进去大量进去串行转并发的逻辑,还是会从redis中取出最新pageNo对应的分页数据
052_菜谱分页缓存的多处加锁优化
发布菜谱分享之后,我们自己和其他人可以来浏览我发布过的菜谱list,分页去浏览,还可 以点击一个菜谱,进入菜谱详情页,读取菜谱详情数据
多处优化内容主要是,仅让listCookbookInfoFromDB()和listener保持同一把分布式锁,新增菜谱接口不需要和前两者保持同一把分布式锁,新增菜谱仅持有针对菜谱Id的分布式锁
053_菜谱详情缓存与DB一致性实现
菜谱更新接口、和菜谱查询的getCookbookFromDB(Long cookbookId)需要保持同一把锁
package com.ruyuan.careerplan.cookbook.service.impl;
/**
* 菜谱服务
*
* @author zhonghuashishan
*/
@Service
@Slf4j
public class CookbookServiceImpl implements CookbookService {
private static final long USER_COOKBOOK_LOCK_TIMEOUT = 200;
private static final long COOKBOOK_UPDATE_LOCK_TIMEOUT = 200;
@Autowired
private RedisCache redisCache;
@Autowired
private RedisLock redisLock;
@Autowired
private CookbookDAO cookbookDAO;
@Autowired
private CookbookSkuRelationDAO cookbookSkuRelationDAO;
@Autowired
private CookbookUserDAO cookbookUserDAO;
@Autowired
private CookbookConverter cookbookConverter;
@Autowired
private GoodsService goodsService;
@Autowired
private DefaultProducer defaultProducer;
@Transactional(rollbackFor = Exception.class)
@Override
public SaveOrUpdateCookbookDTO saveOrUpdateCookbook(SaveOrUpdateCookbookRequest request) {
// 针对菜谱自身id进行加锁
String cookbookUpdateLockKey = RedisKeyConstants.COOKBOOK_UPDATE_LOCK_PREFIX + request.getId();
Boolean lock = null;
if(request.getId() != null && request.getId() > 0) {
// 此时说明是菜谱更新操作,而不是操作新增操作,仅菜谱更新操作会进行加锁
lock = redisLock.lock(cookbookUpdateLockKey);
}
// 新增菜谱时,lock会为null
if (lock != null && !lock) {
log.info("操作菜谱获取锁失败,operator:{}", request.getOperator());
throw new BaseBizException("新增/修改失败");
}
try {
// 构建菜谱信息
CookbookDO cookbookDO = buildCookbookDO(request);
// 保存菜谱信息
// 菜谱 = 美食分享,关于美食、菜品,图,视频,如何做,原材料,信息
cookbookDAO.saveOrUpdate(cookbookDO);
// 菜谱和商品的关联信息,一个菜谱可以种草多个商品,可以保存菜品跟多个商品关联关系
List<CookbookSkuRelationDO> cookbookSkuRelationDOS = buildCookbookSkuRelationDOS(cookbookDO, request);
// 保存菜谱商品关联信息
cookbookSkuRelationDAO.saveBatch(cookbookSkuRelationDOS);
// 更新缓存信息
updateCookbookCache(cookbookDO, request);
// 发布菜谱数据更新事件消息
publishCookbookUpdatedEvent(cookbookDO);
// 返回信息
SaveOrUpdateCookbookDTO dto = SaveOrUpdateCookbookDTO.builder()
.success(true)
.build();
return dto;
}finally {
if(lock != null) {
redisLock.unlock(cookbookUpdateLockKey);
}
}
}
private void publishCookbookUpdatedEvent(CookbookDO cookbookDO) {
// 发消息通知作者的菜谱信息变更
CookbookUpdateMessage message = CookbookUpdateMessage.builder()
.cookbookId(cookbookDO.getId())
.userId(cookbookDO.getUserId())
.build();
defaultProducer.sendMessage(RocketMqConstant.COOKBOOK_UPDATE_MESSAGE_TOPIC,
JsonUtil.object2Json(message), "作者菜谱变更消息");
}
private CookbookDO buildCookbookDO(SaveOrUpdateCookbookRequest request) {
CookbookDO cookbookDO = cookbookConverter.convertCookbookDO(request);
cookbookDO.setFoods(JsonUtil.object2Json(request.getFoods()));
cookbookDO.setCookbookDetail(JsonUtil.object2Json(request.getCookbookDetail()));
cookbookDO.setUpdateUser(request.getOperator());
// 新增数据
if (Objects.isNull(cookbookDO.getId())) {
// 菜谱状态为空,则设置为未删除
if (Objects.isNull(cookbookDO.getCookbookStatus())) {
cookbookDO.setCookbookStatus(DeleteStatusEnum.NO.getCode());
}
// 设置创建人
cookbookDO.setCreateUser(request.getOperator());
}
return cookbookDO;
}
private void updateCookbookCache(CookbookDO cookbookDO, SaveOrUpdateCookbookRequest request) {
CookbookDTO cookbookDTO = buildCookbookDTO(cookbookDO, request.getSkuIds());
// 修改菜谱信息缓存数据
String cookbookKey = RedisKeyConstants.COOKBOOK_PREFIX + cookbookDO.getId();
redisCache.set(cookbookKey, JsonUtil.object2Json(cookbookDTO), CacheSupport.generateCacheExpireSecond());
String userCookbookCountKey = RedisKeyConstants.USER_COOKBOOK_COUNT_PREFIX + request.getUserId();
// 这里用increment不合适,还是应该用set
redisCache.increment(userCookbookCountKey, 1);
}
private CookbookDTO buildCookbookDTO(CookbookDO cookbookDO, List<String> skuIds) {
CookbookDTO cookbookDTO = cookbookConverter.convertCookbookDTO(cookbookDO);
CookbookUserDO userDO = cookbookUserDAO.getById(cookbookDO.getUserId());
cookbookDTO.setUserName(userDO.getUserName());
cookbookDTO.setCookbookDetail(
JSON.parseArray(cookbookDO.getCookbookDetail(), StepDetail.class));
cookbookDTO.setFoods(JSON.parseArray(cookbookDO.getFoods(), Food.class));
cookbookDTO.setSkuIds(skuIds);
return cookbookDTO;
}
private List<CookbookSkuRelationDO> buildCookbookSkuRelationDOS(CookbookDO cookbookDO, SaveOrUpdateCookbookRequest request) {
List<String> tags = request.getFoods().stream().map(food -> food.getTag()).collect(Collectors.toList());
List<SkuInfoDTO> skuInfoDTOS = goodsService.getSkuInfoByTags(tags);
List<String> skuIds = skuInfoDTOS.stream().map(skuInfoDTO -> skuInfoDTO.getSkuName()).collect(Collectors.toList());
request.setSkuIds(skuIds);
List<CookbookSkuRelationDO> cookbookSkuRelationDOS = new ArrayList<>();
for (String skuId : skuIds) {
CookbookSkuRelationDO cookbookSkuRelationDO =
buildCookbookSkuRelationDO(cookbookDO.getId(), skuId, request.getOperator());
cookbookSkuRelationDOS.add(cookbookSkuRelationDO);
}
return cookbookSkuRelationDOS;
}
/**
* 构建菜谱商品关联对象
* @param cookbookId
* @param skuId
* @param operator
* @return
*/
private CookbookSkuRelationDO buildCookbookSkuRelationDO(Long cookbookId,
String skuId,
Integer operator) {
CookbookSkuRelationDO cookbookSkuRelationDO = CookbookSkuRelationDO.builder()
.cookbookId(cookbookId)
.skuId(skuId)
.delFlag(DeleteStatusEnum.NO.getCode())
.createUser(operator)
.updateUser(operator)
.build();
return cookbookSkuRelationDO;
}
@Override
public CookbookDTO getCookbookInfo(CookbookQueryRequest request) {
Long cookbookId = request.getCookbookId();
CookbookDTO cookbook = getCookbookFromCache(cookbookId);
if(cookbook != null) {
return cookbook;
}
return getCookbookFromDB(cookbookId);
}
private CookbookDTO getCookbookFromCache(Long cookbookId) {
String cookbookJsonString = redisCache.get(RedisKeyConstants.COOKBOOK_PREFIX + cookbookId);
if (StringUtils.hasLength(cookbookJsonString)){
log.info("从缓存中获取菜谱数据,cookbookId:{},value:{}", cookbookId, cookbookJsonString);
// 防止缓存穿透
if (Objects.equals(CacheSupport.EMPTY_CACHE, cookbookJsonString)) {
return null;
}
redisCache.expire(RedisKeyConstants.COOKBOOK_PREFIX + cookbookId,
CacheSupport.generateCacheExpireSecond());
CookbookDTO dto = JsonUtil.json2Object(cookbookJsonString, CookbookDTO.class);
return dto;
}
return null;
}
/**
* 从数据库中获取菜谱信息
*
* @param cookbookId
* @return
*/
private CookbookDTO getCookbookFromDB(Long cookbookId) {
// 我们主要针对的是菜谱数据的更新操作加锁
// 对某个菜谱进行更新操作,同时在读取这个菜谱的详情,缓存过期,锁粒度,其实cookbookId
String cookbookLockKey = RedisKeyConstants.COOKBOOK_UPDATE_LOCK_PREFIX + cookbookId;
boolean lock = false;
try {
// 使用tryLock,是为了使用串行转并发
lock = redisLock.tryLock(cookbookLockKey, COOKBOOK_UPDATE_LOCK_TIMEOUT);
} catch(InterruptedException e) {
CookbookDTO cookbook = getCookbookFromCache(cookbookId);
if(cookbook != null) {
return cookbook;
}
log.error(e.getMessage(), e);
}
// 串行转并发
if (!lock) {
CookbookDTO cookbook = getCookbookFromCache(cookbookId);
if(cookbook != null) {
return cookbook;
}
log.info("缓存数据为空,从数据库查询菜谱信息时获取锁失败,cookbookId:{}", cookbookId);
throw new BaseBizException("查询失败");
}
try {
// double check
CookbookDTO cookbook = getCookbookFromCache(cookbookId);
if(cookbook != null) {
return cookbook;
}
log.info("缓存数据为空,从数据库中获取数据,cookbookId:{}", cookbookId);
String cookbookKey = RedisKeyConstants.COOKBOOK_PREFIX + cookbookId;
CookbookDTO dto = cookbookDAO.getCookbookInfoById(cookbookId);
if (Objects.isNull(dto)) {
redisCache.set(cookbookKey, CacheSupport.EMPTY_CACHE, CacheSupport.generateCachePenetrationExpireSecond());
return new CookbookDTO();
}
redisCache.set(cookbookKey, JsonUtil.object2Json(dto), CacheSupport.generateCacheExpireSecond());
return dto;
} finally {
redisLock.unlock(cookbookLockKey);
}
}
}
054_种草商品查询mock接口代码实现
菜谱详情页,可以查看到种草进去的商品,种草的商品的查询接口,本次只是做了一个mock,这个接口按说应该是电商里的商品系统来提供的
菜谱详情页中,用户作者信息也是要查询的
055_社交分享功能的代码逻辑实现
进入菜谱详情页,浏览美食菜谱信息,如果某个菜谱绑定了一个开团的团长信息,后续如果别的用户跟着团长一起,分享了这个菜谱出去,就可以获得后续的奖励
056_菜谱团长活动的奖励规则逻辑实现
当菜谱分享超过了2次,就可以触发后续的奖励逻辑,奖励逻辑里面就会有一个金额,提现多少还剩多少等等
057_社交活动进入与参与代码逻辑实现
进入菜谱详情页,社交活动发起、社交活动分享、活动进入与参与,社交活动业务逻辑闭环, 这块代码实现,用了很多缓存,跟我们的社区电商主业务闭环关系不大
对于社区电商来说, 主要还是发布菜谱数据、feed 流浏览、查看菜谱、看种草商品、加购物车和库存实现企业级缓存架构,以及最后走交易的闭环。
菜谱发起社交活动 社交活动这一块,对缓存页用了,我们先不去重点去讲解这块,跟大家大致过一下,如果说 大家对这块感兴趣的,可以仔细的去看这个里面代码逻辑。不感兴趣也可以把这块给略过去
购物车,他的实现架构是比较依赖于缓存,购物车与库存是比较企业级的,所以这块我们可以好好的去看一下

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









