







为啥要写这篇wiki?
最近在一个新项目中掉了不少坑,其中一项就是竞对数据分析,于是想做些总结并分享出来,既能让其他朋友少掉坑,也能让自己对此的认识更加深刻。
我本来先自己做了些总结,但随后意识到,我所碰到的问题一定不是什么新问题,一定有比我更专业的人早就做好了总结,于是google了一下,果不其然有很多发现,这些总结大多都聚焦于具体的数学分析方法、数据分析理论,虽然这些都不错,但却比较艰深晦涩。然而功夫不负有心人,通过调整搜索关键词,我终于找到了一篇数据分析一般性原则的总结,类似于我自己的总结是思维方式上的一些总结,但却远比我的总结全面,也更加通俗易懂,于是就想把它分享出来,相信能对数据分析的工作有些帮助。
下面并不是对这篇文章逐字逐句的翻译,它更多地是我基于自己的理解,用自己语言的一个转述,对原文感兴趣的同学可以看这里。
做好数据分析的基本原则:
原则1:明确目标和方法
做数据分析前要清楚知道我们通过分析想回答什么问题,达成什么目标。此外我们还应该对我们要分析的数据有些基本了解,比如有些什么数据可用?数据是如何组织的?存储在哪里?我们有什么分析工具等等。磨刀不误砍柴工,先想清楚这些问题往往能让后面的工作更加聚焦和高效
原则2:了解数据是如何生成的
举个例子,比如你是Amazon的一名数据分析师,接受了一项任务来做订单分析。数据库里有张订单表,你可能需要考虑的是,这张订单表会保存未完成的订单吗?这张表的一条记录在网站上是如何生成的?如果用户创建了一个订单但是没有付款这张表里会有数据吗?这张表里每个字段具体是什么含义?
(我们在项目中的这个环节就掉了大坑,因为涉及具体的业务,此处省略1万字… )
原则3:检查数据的有效性
在整个分析过程不断地检查以确保数据有效性,这可以及早地发现问题。
比如,作者给出的一个例子是,他曾经帮一个朋友分析一个非常大的基于时间序列的数据集(~10G),分析的结果他直觉上觉得不对,于是进一步深挖,按照日期对事件排序后,发现有两天没有任何数据,而这种情况本不应该出现。
(我们在原则2掉的那个大坑,如果遵循原则3也可以及早发现问题)
原则4:从不同角度对数据进行分析
首先需要了解的辛普森悖论,也就是有些趋势在子数据集中非常明显,但是当这些子数据集汇总在一起后,这个趋势却消失了。
一个例子:
如下表,这是加州伯克利大学1973年秋男女生的入学率数据,基于此,该大学被起诉性别歧视。
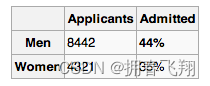
但是当我们结合性别和院系来看的话,我们就会发现很多院系的女生入学率是高于男生的:
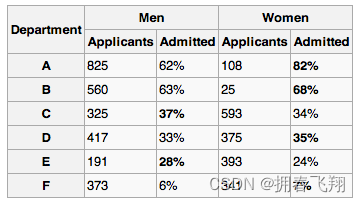
所以在做数据分析的时候,需要谨记辛普森悖论,明白有时汇总的数据统计可能是有误导性的,我们需要从不同的角度来分析我们的数据
原则5:保持怀疑
除了要对数据的有效性做检查外,我们在整个分析的过程中都要保持一个怀疑的态度。如果有什么看起来不太对,那么在我们能将其解释清楚之前,就先不要继续往前分析了。
那么数据很多,我们到底要对哪些数尤其关注呢?结合在另外一个关于数据分析的文章学习到的要点就是:看大数、略小数、看关键指标、看异常数据.
(我们在这个环节又掉了坑,再次省略1万字 )
原则6:像一个律师那样思考
一个好律师在准备他们的case时也会考虑他们的对手会怎么回应,类似地,我们也需要考虑我们的听众会问什么问题,通过提前对此做出准备,能让我们的工作更加令人信服,没人会愿意听到类似于“我不确定,我还没看那个”这样的回答
原则7:澄清我们的假设
做数据分析的时候,很多情况下我们往往无法获取足够的数据来做一个彻底,详尽的分析 — 这种情况下,我们一般要做一些条件假设。在share我们的分析结果的时候,我们需要明确地告知大家我们所做的条件假设。此外,我们还应该尽量地从与该分析相关的同学或者该领域的专家那寻求帮助,以确保我们所做得假设是不片面、符合逻辑的。
原则8:检查我们的工作结果
这个看起来很显而易见,但是由于项目工期,快速的变化,以及突发的需求等各种原因,很多人常常跳过这一步,但我想你的受众相对于一个快出产出的分析结果,他们更想要的是一个正确的分析结果。
(我们就是因为偶尔检查时发现了数据的不一致性才发现了原则5处提到的大坑,如果我们能早一点常态化这个检查,我们的工作会高效的多)
原则9:沟通
最后,在整个的分析过程中都应该和该分析相关的同学(尤其是老板)保持沟通,也许他根本就不关心小数点的精度,他可能只关心趋势。数据分析往往是为了解答某个问题的,而每个问题背后都有一群与之息息相关的同学(老板),所以和他们一起解决问题才是最关键的,千万别只是自己蒙头做分析, 别既没有得到应有的帮助又走偏了方向。















 2099
2099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











