



前言:
随着AI技术的飞速发展,ComfyUI与AnimateDiff的结合为视频创作带来了革命性突破。只需5分钟,即可将普通视频转化为丝滑流畅的AI动画,无论是人物动作还是场景转换,都能实现无缝衔接。本教程将手把手教你掌握这一高效工具,开启AI视频创作的新篇章!
用[AnimateDiff]Prompt Travel video-to-video搭配[ComfyUI]制作AI视频,效果丝滑制作[Stable Diffusion]动画
- AnimateDiff的技术原理
AnimateDiff可以搭配扩散模型算法(Stable Diffusion)来生成高质量的动态视频,其中动态模型(Motion Models)用来实时跟踪人物的动作以及画面的改变。
\2. 环境搭建
这里我们使用ComfyUI来搭配AnimateDiff做视频转视频的工作流。我们预设ComfyUI的环境以及搭建好了,这里就只介绍如何安装AnimateDiff插件。
\3. ComfyUI AnimateDiff视频转视频工作流
- 找到一个真人跳舞视频
- 提取视频帧,并用ControlNet Openpose提取人物动作信息
- 根据视频帧里面的动作信息,使用SD重新绘制每一帧视频
- 组合出完整视频
3.1 读取ComfyUI工作流
直接把下面这张图拖入ComfyUI界面,它会自动载入工作流,或者下载这个工作流的JSON文件,在ComfyUI里面载入文件信息。

这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

3.2 安装缺失的node组件
第一次载入这个工作流之后,ComfyUI可能会提示有node组件未被发现,我们需要通过ComfyUI manager安装,它会自动找到缺失的组件并下载安装(!!需要网络通畅)。
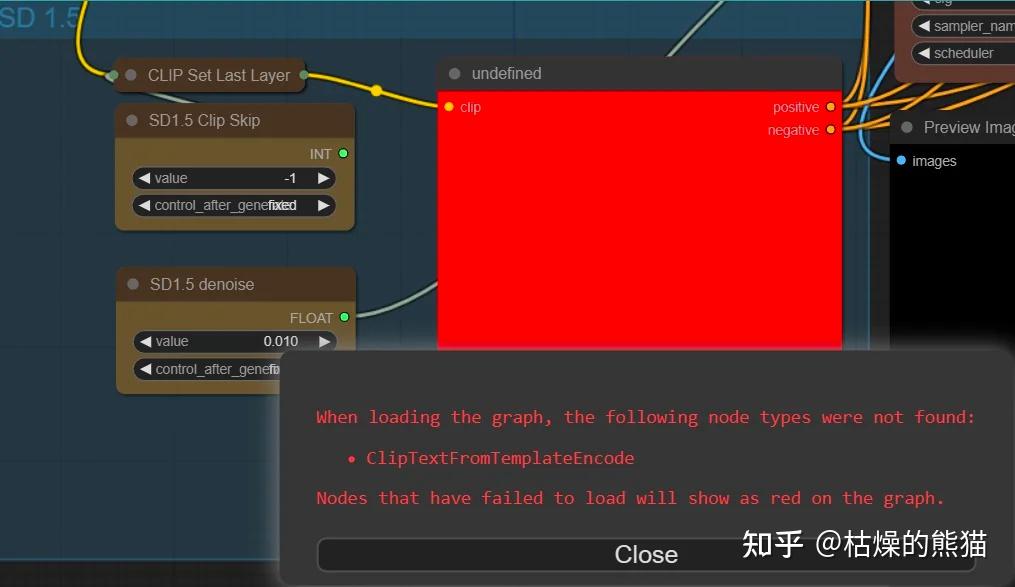
点击ComfyUI Manager按钮打开组件管理

再点击Install Missing Custom Nodes安装组件
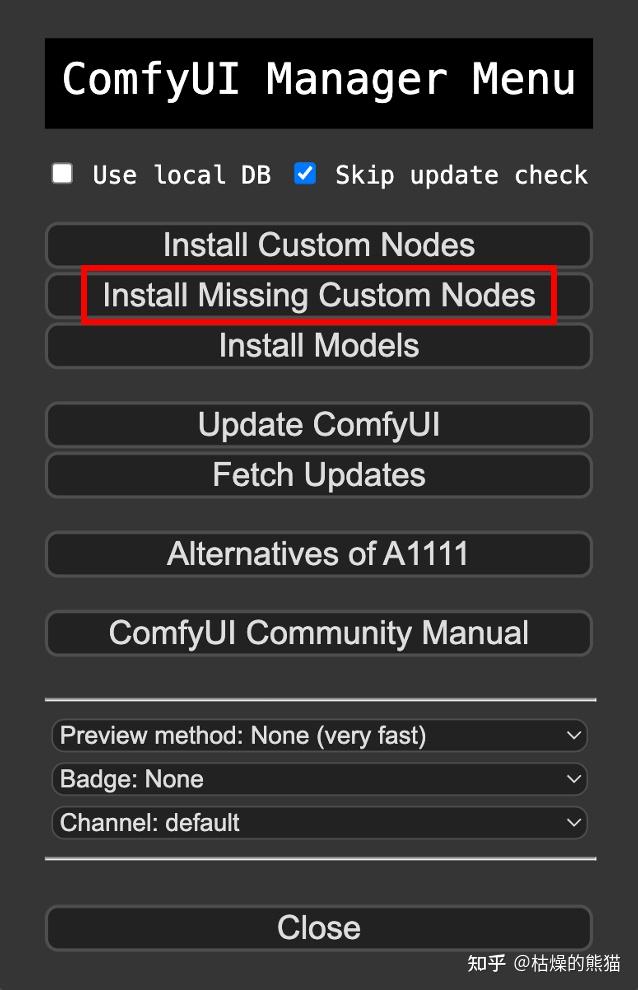
安装完成后要重启ComfyUI才能完成载入刚才缺失的组件。
如果网络状态不好,可能会导致下载组件失败,需要多试几次
3.3 下载一个AI绘画模型
这里比较推荐C站上的**Dreamshaper 8**这个模型,实测动画人物效果比较好,当然大家也可以自己去测试其他的模型,有好的效果,欢迎评论留言。
下载好的模型放到ComfyUI > models > checkpoints目录。
然后刷新页面
在Load Checkpoint这个组件里可以选择不同的模型

3.4 再下载一个VAE模型
下载VAE,放到ComfyUI > models > vae这个目录里。
然后刷新页面
在Load VAE里可以选择不同的编码器模型

3.5 下载AnimateDiff动态特征模型
下载**mm_sd_v15_v2.ckpt,放到ComfyUI > custom_nodes > ComfyUI-AnimateDiff-Evolved > models**文件夹。
刷新页面
在AnimateDiff Loader里,可以选择我们需要的动态特征模型

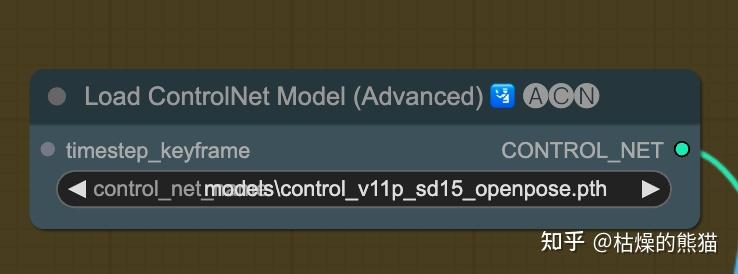
3.6 下载Openpose ControlNet模型
下载control_v11p_sd15_openpose.pth,放到ComfyUI > models > controlnet文件夹。
刷新页面
在 **Load ControlNet Model (Advanced)**里,选择对应模型
3.7 上传原视频
在**Load Video(Upload)**选择视频素材

3.8 生成视频
然后就可以点击Queue Prompt开始生成视频了
视频生成的大部分时间都集中在KSampler这个组件里,在生成过程中上面有一个进度条
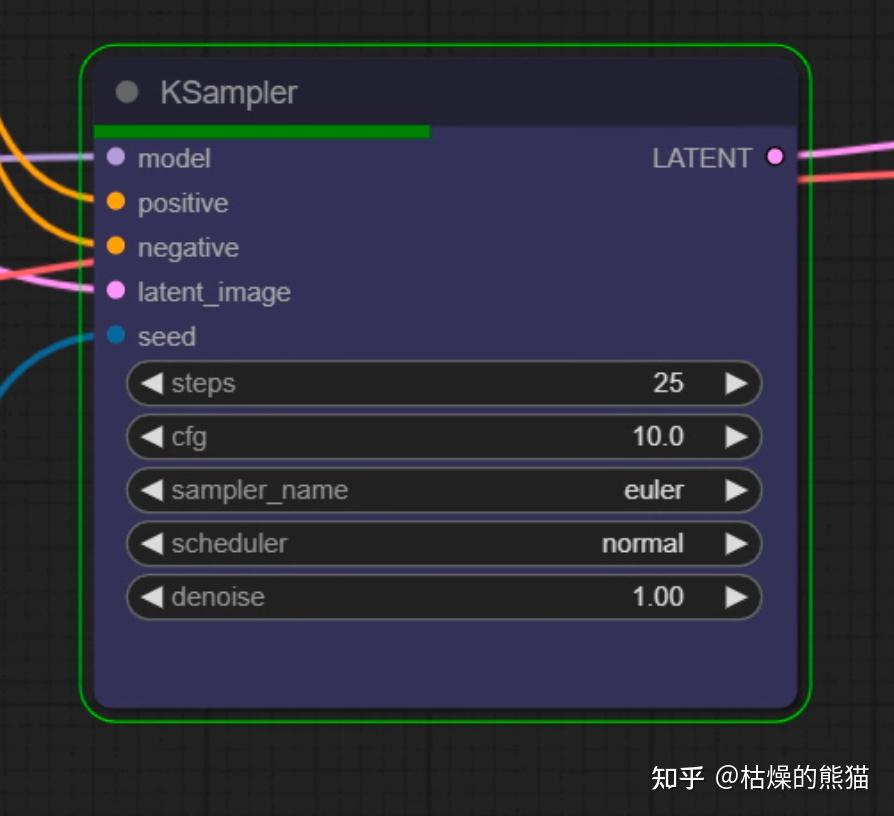
另外在打开ComfyUI的windows终端里也可以看到进度以及错误信息

生成结束后,视频会在AnimateDiff Combine这个组件里合成
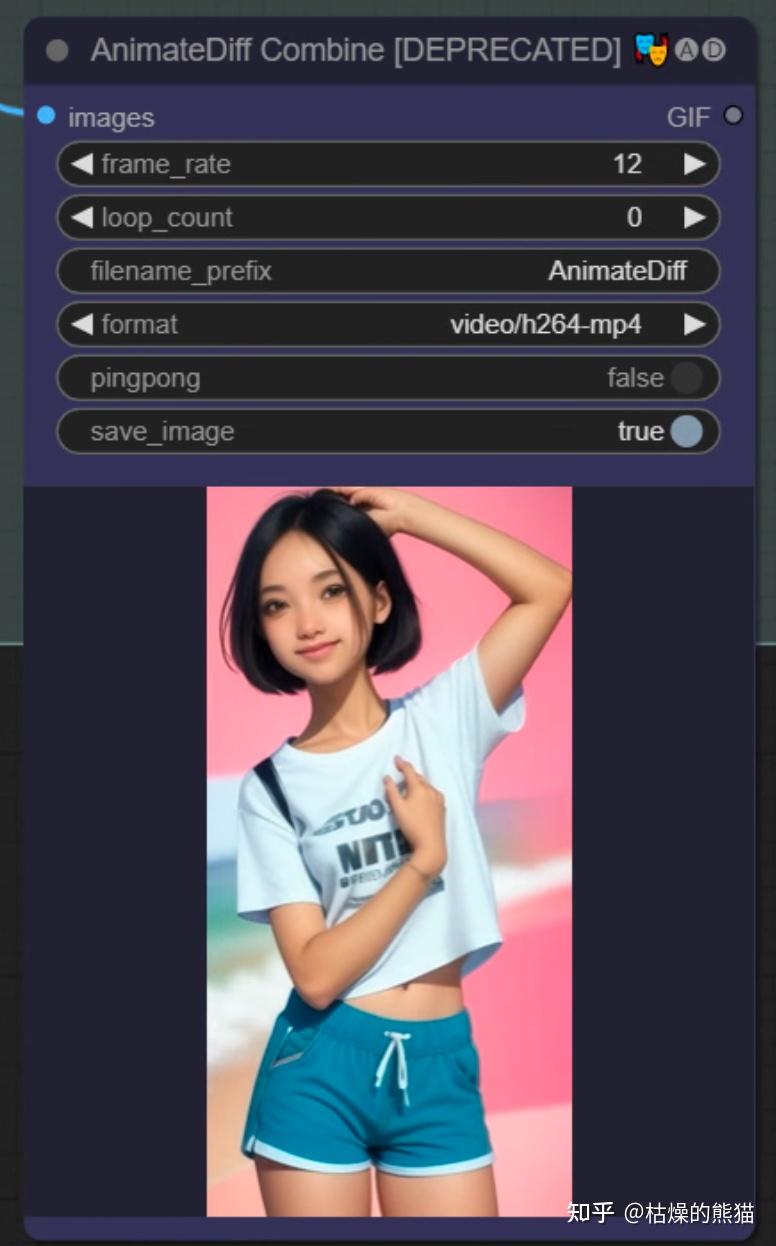
下面是一个结果的对比示例

00:13
\4. Debug
其中有三个组件会储存中间信息帮助分析错误
视频帧

ControlNet OpenPose处理结果
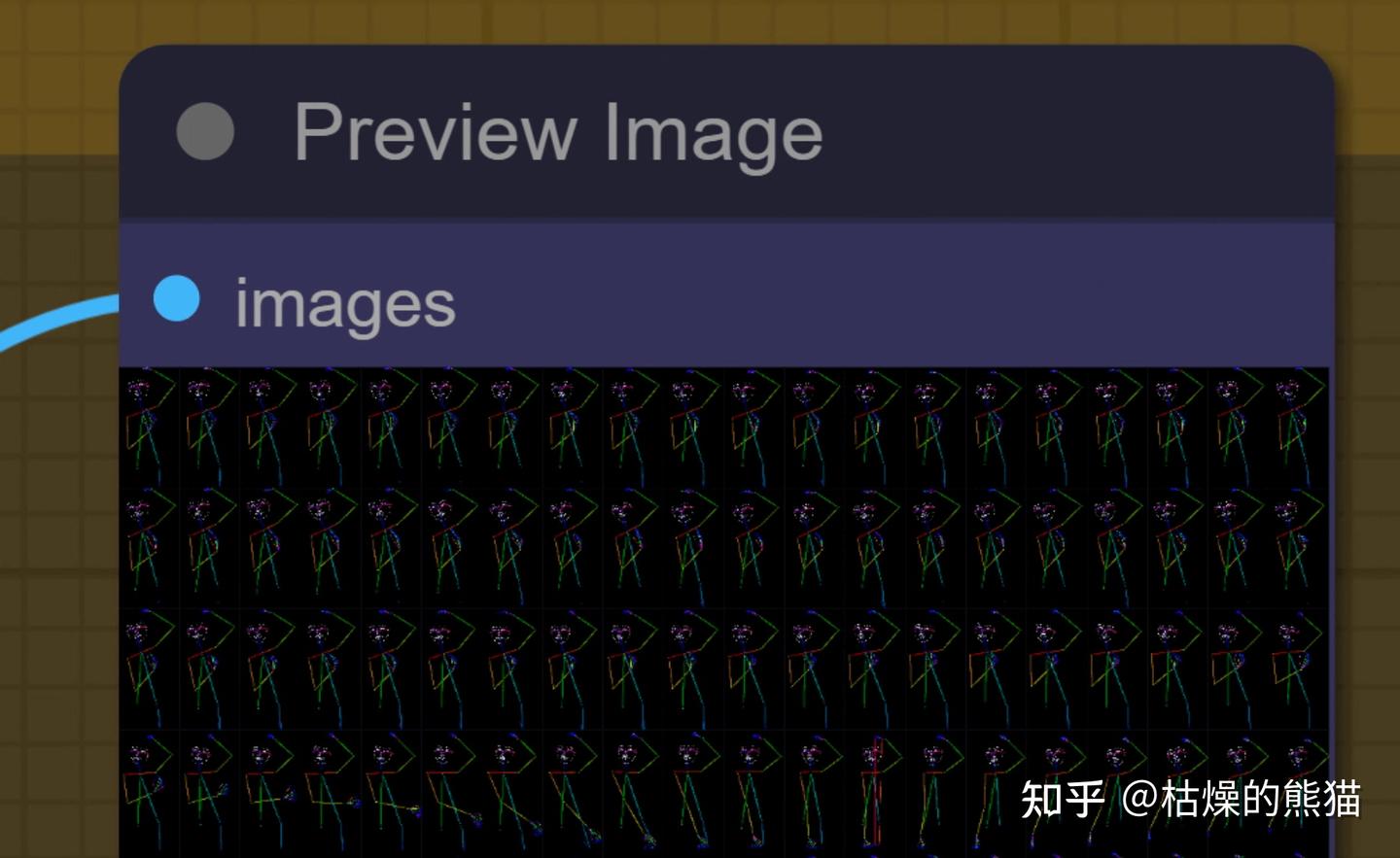
结果视频帧

\5. 其他设置
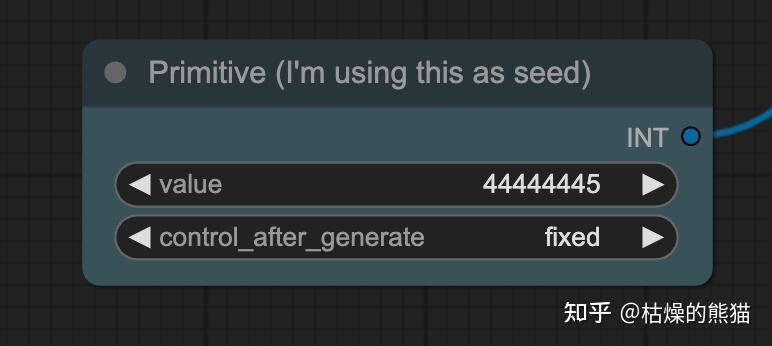
5.1 通过改变图片种子值(seed)来修改图片内容
5.2 修改人物提示词
prompt prefix: 图片主体

prompt travel: 变化的背景内容,会根据不同的frames添加进图片

在这个例子中:
第0-23帧,画面提示词是:
High detail, girl, short pant, t-shirt, sneaker, a modern living room
第24-59帧:
High detail, girl, short pant, t-shirt, sneaker, beach and sun
第60帧之后:
High detail, girl, short pant, t-shirt, on the moon
5.3 输入视频参数

frame_load_cap : 载入视频的最大帧数
select_every_nth : 每隔~帧载入1帧画面,这样会导致跳过一些帧,导致视频不连贯,但是由于减少了需要处理的帧数,这样可以提高处理速度
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









