







一.保存对象的方式:
1. 数组 -编译器支持的类型,效率高,保存一组基本类型推荐使用;但长度固定,不够灵活;
2. 容器 -Java实用类库(java.util)提供,基本类型是List、Set、Queue和Map。也成为集合类型(collection classes),但Java类库的Collection另有所指。容器可以动态调整大小。
二.Java SE5之前的容器存在的问题:编译器允许向容器中插入不正确的类型。 (因为以前的容器实现保存的是Object对象引用)这会产生运行时异常。
Java SE5引入泛型(generics),可以解决这个问题,把运行时异常转变为编译时错误。
使用泛型的好处:编译器可以检查放置到容器中的对象类型;使用容器中的对象时,可以使用更加清晰地语法(不需要转型,更清晰的使用foreach)。自动向上转型也可以在泛型中很好的工作,即可以使用泛型参数指定的类的子类。
三.@SuppressWarnings 抑制警告
四.Java明确区分两种类型的异常 :那些扩展了java.lang.Exception的异常称为checked exceptions , 编译器要求这些异常必须被捕获或者重新抛出;那些扩展了java.lang.RuntimeException的异常称为unchecked exceptions , 它们不是必须捕获的;当然, 也可以捕获这些异常并相应地扩展调用栈, 就像通常对checked exceptions做的那样。
正统的Java做法:使用checked exceptions,而unchecked exceptions预示编程上的错误。 (更多参见转帖文章《checked or unchecked》)
五."保存对象"两个不同的概念,也是Java容器类类库不同的基本接口:
1. Collection:独立元素的序列,元素服从一条或多条规则 。如List必须按照插入的顺序保存元素;Set不能有重复元素;Queue按照排队规则(queuing discipline)来确定对象产生的顺序(通常与插入的顺序相同)。
2. Map:一组"键-值"对象对(a group of key-value object pairs),允许使用键来查找值。 Map使得可以用一个对象来查找另一个对象,也被称为"关联数组"或"字典"。(某种意义上来说,ArrayList何尝不是一种Map,以为允许用数字来查找值,即将数字和对象关联在了一起)。
Collection接口概括了序列(一种存放一组对象的方式)的概念。所有Collection都可以使用foreach。
Collection add()的准确描述:确保Collection包含指定的元素。 主要是考虑到Set的含义。
六.理想情况下,编写的大部分代码都是在与这些接口打交道,并且唯一需要指定所使用的精确类型的地方就是在创建的时候。好处在于修改实现时,只需要在创建处修改代码。 例如,使用List,而不是直接使用ArrayList,像这样List<Apple> apples = new ArrayList<Apple>,这样在需要修改实现时,只需要在定义的时候修改,如把ArrayList改为LinkedList。
当然,当你需要用到具体类的额外功能时,就不能采用这种方式 。如需要用到LinkedList具有的额外方法。
七.添加一组元素的方法
1. collection的构造器: 可以接受一个collection对象来初始化自己,因此可用Arrays.asList()来获得List对象,传递给构造器;
2. Arrays.asList()方法 :具有可变参数列表,可接受数组或元素列表;返回List对象。返回的List对象可以直接赋值给另一个List,但此时底层仍是以数组形式表示,不能改变大小,即不能添加和删除元素 (运行时报"不支持的操作"错误);另一个限制:会对所产生的List的类型做出最理想的假设,而不关心对它赋予的类型。 例:
解决办法:使用显式类型参数说明(explicit type argument specification) ,象上面的例子中最后所做的那样。
3. Collections.addAll()方法 :接受一个collection对象,及一个数组或元素列表(可变参数列表);把数组或列表的元素添加到collection对象中。这种方法比构造器快,因此首选方法是:定义一个空的collection对象,用该方法添加元素 。注意的是,不能用这种方法来构造一个Collection (我想,是不能这样:Collection<integer> collection = Collections.addAll(collection, 1,2,3,4,5))。
4. Collcetion对象的addAll()方法 :只能接受collection对象,没有前面两种方法灵活。
Map除了用另一个Map的元素外,没有别的方式自动初始化。
八.容器的打印
数组需要用Arrays.toString(),容器不需要任何其它手段 (它们的toString()方法就足够了)。
Collection打印出来的内容以[]括住,逗号分隔;Map则用{},逗号分隔,键和值用=连接。
Hash提供最快的查找技术,存储顺序无实际意义;List按照被插入的顺序保存元素;Tree按照比较结果的升序保存对象。
九.List:以特定的顺序保存对象;扩展Collection接口,添加了插入和删除List中间元素的方法;一种可修改的序列(增加、减少、改变元素)。
两类:
1. ArrayList :随机访问元素快,但在List中间插入和移除元素慢;
2. LinkedList :优化顺序访问,插入和移除元素代价低;随机访问慢;提供的功能比ArrayList多。
注意:contains()、indexOf()、remove()及相关方法都要用到对象的equals()方法,所以List的行为将会随equals()的行为变化而变化。
效率问题 :ArrayList插入和移除元素慢,但不应因此觉得永远不要在ArrayList中插入元素,而是切换到LinkedList。要做的只是记住这一点。当在ArrayList中执行了很多插入操作,而程序开始变慢时,知道应该查看自己的List实现。策略就是置之不顾,直到发现需要担心时。
注意:subList()方法并不是返回一个全新的List对象,而只是返回原List中包含的这个subList的引用,因此对subList的任何操作都会影响到原始List 。另外,如果对原List执行removeAll(subList)操作,会产生运行时ConcurrentModificationException。见习题7。
List重载了一个addAll(int, Collection)方法,可以插入一个新的列表到List中间; Collection的addAll方法追加到结尾。
toArray()方法:有一个重载;无参数的返回Object[];传递目标类型的数组,将返回指定类型的数组, 传递的数组如果太小,该方法新创建一个合适尺寸的数组。
十.迭代器(Iterator)--一种设计模式
迭代器的工作 :在不知道或不关心序列底层结构的情况下,遍历序列,选择每一个元素。
迭代器是一种轻量级对象(lightweight object) --创建代价低。
Java的迭代器只能单向移动 ,用法:
1. 使用iterator()方法返回Collection的迭代器 ;迭代器准备返回序列的第一个元素;
2. 使用next()方法获取下一个元素;
注意:iterator()返回的迭代器是"准备返回序列的第一个元素",而不是已经指向了第一个元素,因此要获取第一个元素也得调用一次next() ,即c.iterator().next()得到的是第一个元素。见习题8。
3. hasNext()方法检验序列是否还有元素;
4. 使用remove()方法删除迭代器返回的最后一个元素。 注意,remove()是一种可选方法,依赖于具体实现,但Java标准容器类库都实现了这个方法。
当仅仅是遍历并获取每个元素,用foreach语法更简练 ;但迭代器可做的工作更多(remove())。调用remove()之前必须调用next()方法 。注意ConcurrentModificationException异常(所谓的fail-fast iterator)。
迭代器的威力在于:将遍历序列的操作与序列的底层结构分离,统一了对容器的访问方式。
十一. ListIterator-Iterator的子类,只能用于List类的访问,可双向移动;可以返回前一个和后一个元素的索引;可以使用set()方法替换最后访问的元素;listIterator()方法返回指向List开始处的ListIterator;listIterator(n)方法返回指向索引为n的元素处的ListIterator。
注意 :反向移动,要想ListIterator初始化指向最后一个元素,listIterator(n)中的n应=size(),而不是size()-1,而后用previous()方法获得最后一个元素;而正向移动时,设获取第三个元素,n = 2,即索引为n,用next()获取,因此如果要next()获取最后一个元素,n=size()-1。见习题12。也就是说,listIterator(n)返回的listIterator,next()得到的是索引为n的元素,而previous()获取的是索引为n-1的元素。之所以有这种区别,在于底层的实现,看代码,区别一目了然。
十二. LinkedList
LinkedList添加了一些可以使其用于Stack、Queue或双端队列(double-ended queue,或称为deque)的方法。
某些方法只是别名,或者只存在些许差异,以使得它们在特定用法的上下文环境中更加适用(尤其是在Queue中)。
如getFirst()和elements()方法完全相同,都返回列表的头,而并不移除它,如果List为空,抛出NoSuchElement异常;peek()方法与他们基本相同,只是列表为空时返回null。
类似的,removeFirst()与remove()方法相同,移除并返回列表的头,List为空,抛出NoSuchElement异常;poll()方法只是在列表为空时返回null。
offer()、add()、addLast()相同,都将某个元素插入到列表的尾端。
addFirst()将元素插入到列表的头。
removeLast()移除并返回列表的最后一个元素。
类似的还有很多。
十三. Stack
java.util中的Stack类采用了继承的方式实现,实际上使用LinkedList实现更好。
十四. Set
查找是Set最重要的操作,因此通常选择HashSet,因为快速查找正是它的长项。
Set的接口与Collection接口完全相同,只是行为不同而已,典型的继承与多态。
HashSet使用散列函数来保存对象,TreeSet使用红黑树数据结构,LinkedHashSet也使用散列来优化查找速度,但看起来使用链表来维护元素的插入顺序。
TreeSet默认按照字典序(lexicographically)排序,如果需要改变排序方法,可将比较器传给TreeSet构造器,如String.CASE_INSENTIVE_ORDER(按照字母表顺序alphabetically)。
十五. Map
get(key)返回key所对应的值,如果key不在Map中,返回null。
containKey()和containValue()方法。
多维Map:值为Map或者别的Array、Collections。
Map可以返回它的键的Set(keySet()方法),它的值的Collection(values()方法),或者它的键值对的Set(entrySet())。
十六. Queue-FIFO
Queue常被用来可靠、安全地传输对象, 如从程序的一个区域传输到另一个区域,或者并行编程中从一个任务传输给另一个任务。
LinkedList实现了Queue接口,因此可用作Queue的一种实现(向上转型为Queue) 。
add()、offer()在允许的情况下将元素插入到队尾,否则前者抛出IllegalStateException异常,后者返回false;
peek()、element()返回但不移除队头,队列为空时前者返回null,后者抛出NoSuchElementException异常;
poll()、remove()返回并移除队头,队列为空时结果与peek()、element()相同。
十七. PriorityQueue
队列规则(Queue discipline)--给定一组队列中的元素,确定下一个弹出队列的元素的规则 。FIFO是典型的一种规则,声明的是下一个元素应该是等待时间最长的元素。
优先级队列(Priority Queue)--下一个元素是最需要的元素(优先级最高的元素)。 Java SE5添加了这种队列。
offer()一个对象到PriorityQueue时,会在队列中被排序 (实际上依赖于具体实现,典型的是插入时排序,但也可以在移除时选择最重要的元素,如果对象的优先级在队列等待时可以改变,那算法的选择就很重要)。默认排序使用对象的自然顺序(natural order),但可以通过提供Comparator(如Collections.reverseOrder(),since Java SE5)改变这个顺序。peek()、poll()和remove()可以获得优先级最高的元素 (对于内置类型,最小值拥有最高优先级)。
如果要在PriorityQueue使用自定义类型,就需要添加额外的功能以提供自然顺序,或者提供自己的Comparator。
十八. Collection or Iterator
可以选择实现Collection接口,也可以选择实现Iterator()。
实现Collection接口可以通过继承AbstractCollection,但必须实现Iterator()和size();如果类继承自其它类,就必须实现完整的Collection,但此时实现Iterator()似乎是一种更明智的选择 ,因为生成Iterator是将队列与使用队列的方法连接在一起耦合度最小的方式,并且与实现Collection相比,在序列类上所施加的约束也少得多。
十九. foreach与迭代器
foreach可以用于数组,也可以用于Collection对象。因为Collection对象实现了Iterable接口(Java SE5引入,包含一个产生Iterator的iterator()方法)。也就是说,foreach可以用于数组和实现了Iterable接口的类(数组并不是Iterable) 。
当类需要提供多种在foreach语句使用的方法时,可以采用适配器方法的惯用法 。当已经拥有一个接口并需要另一个接口时,就可以编写适配器。例如,想在默认前向迭代器的基础上,添加产生反向迭代器的能力,此时不能使用覆盖,而是应该添加一个能够产生Iterable对象的方法,该对象可以用于foreach语句,像这样
通过这种方法,可以创建不同行为多个迭代器,如随机访问random()等。
二十. 新程序中不应该使用过时的Vector、Hashtable和Stack。
二十一. Java容器简图
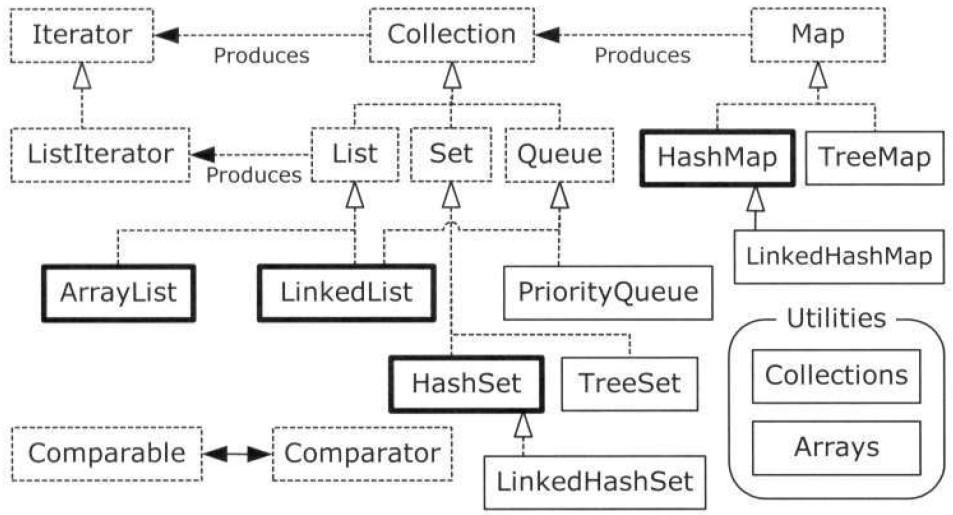
注意,标记接口RandomAccess附着到了ArrayList上,而没有到LinkedList上,这为想要根据所使用的特定的List而动态修改其行为的算法提供了信息。
二十二. 仍需注意对象与引用的问题
容器中包含的是对象的引用;当用一个容器构造另一个容器时(构造器,或者相关方法),执行的都是浅复制,即把引用本身复制过去,按照新容器的规则排列或者做相应处理,而不是克隆对象本省,因此两个容器都可以通过引用对对象本身进行相应操作,其结果会反映在两个容器上。














 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









