







目录
hive三种安装模式:
- 嵌入模式:使用内嵌的Derby数据库存储元数据,元数据不能共享,是hive默认安装方式,但是一次只能连接一个客户端,适合用于测试,不适合生产环境。
- 本地模式:采用外部数据库存储元数据,该模式不需要单独开启metastore服务,因为本地模式使用的是和hive在同一个进程的Metastore服务。
- 远程模式:采用外部数据库存储元数据,该模式需要单独开启metastore服务,然后每个客户端都在配置文件中配置连接该Metastore服务。远程模式中,Metastore服务和hive运行在不同的进程中。
注:
本地和远程模式:本质上都是将hive默认的元数据存储介质由自带的Derby数据库替换为MySQL数据库,这样无论在任何目录下以任何方式启动hive,只要连接的是同一天hive服务,那么所有节点访问的元数据信息是一致的,从而实现元数据的共享。
Hive安装之嵌入安装:
- 下载Hivea安装包
- 输入命令:bin/hive就进入到hive中了
Hive本地安装
1.安装mysql服务
下载安装mysql

启动mysql服务

下载安装mariadb

启动mariadb服务;
永久启动mariadb服务;
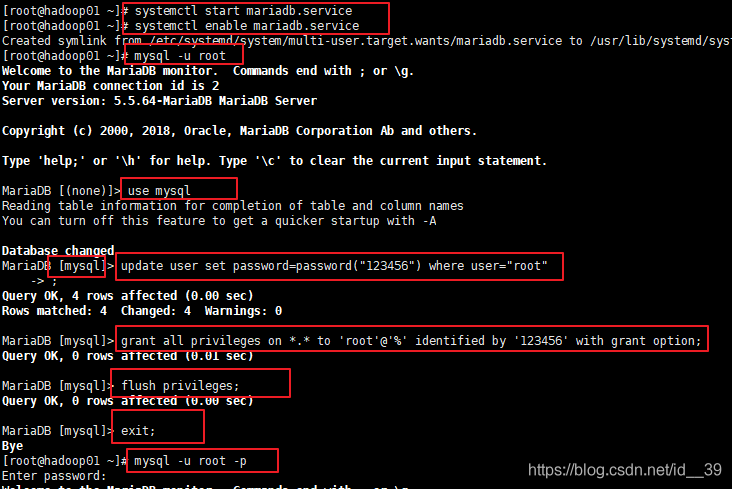
登录mysql服务;
使用mysql;
设置密码;
授予root权限,可以用于远程登录;
退出mysql;
使用密码登录mysql;
2.安装hive
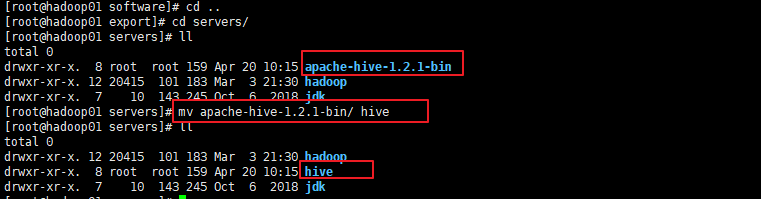
导入hive压缩包(也可以使用rz来上传)

解压到servers

为刚解压的文件改一个简单的名字hive
进入hive;
找到conf目录;
可以看到没有hive-env.sh,所以用临时文件复制一份
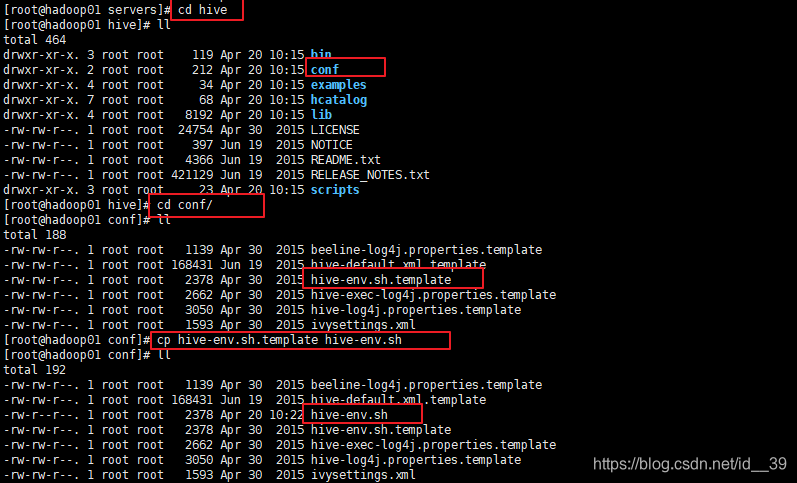
打开配置文件

修改配置文件

新建一个hive-site.xml文件

添加如下内容
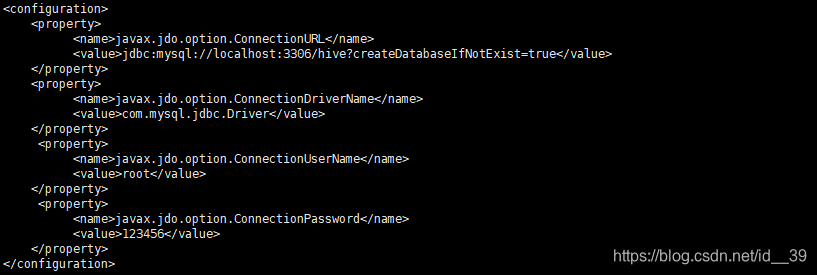
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
hive-site.xml文件中用到了一个数据库驱动文件,所以下面,我们要导入到hive/lib中(也可以用rz,前提是需要首先yum一个包)
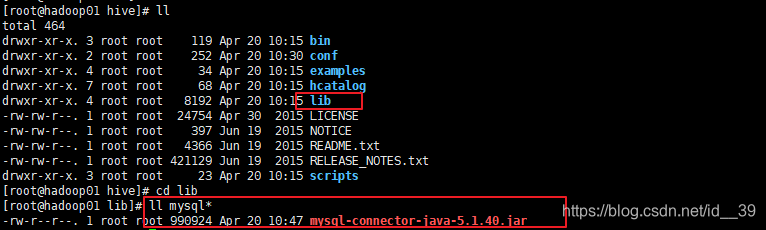
将hadoop01中的hive配置复制到hadoop02 和hadoop03中


3.Hive的远程管理:
首先需要先开启集群


开启一个hiveserver2服务

开启hive成功会出现如下进程

在hadoop02中进入beeline(也可以在其他节点操作)
输入远程连接命令:bin/beeline

输入远程连接协议,连接到指定hive服务的至极名和端口(默认10000),连接hadoop01
回车后,输入用户名和密码,可以看到连接成功(成功进入)

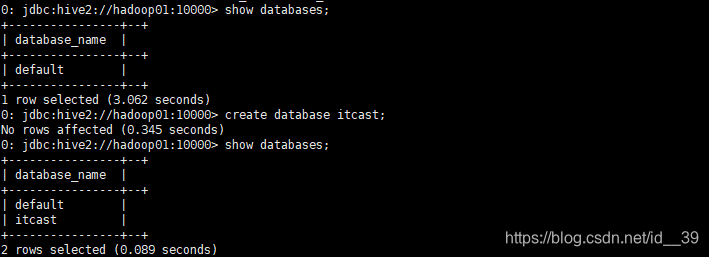
接下来的操作就和mysql语句差不多,查看数据库

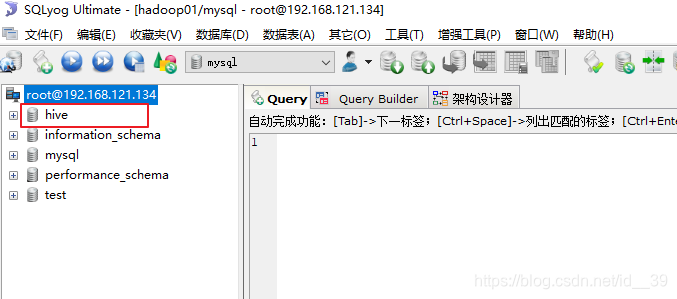
开启hive后,用sqlyog连接hadoop01的mysql数据库,刷新后会看到,出现一个hive数据库,里面存放的都是元数据表格。
创建数据库
切换数据库,查看表格

4.Hive内部表操作

创建内部表,第二行为使用逗号为分隔符,导入到表格中

可以看到表格创建成功,但是没有数据
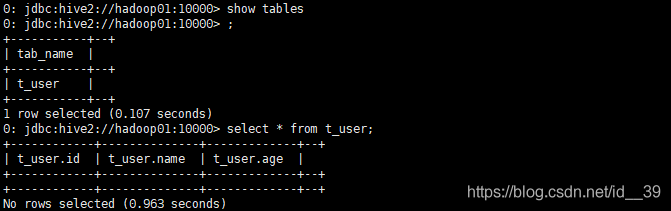
将数据放入到itcast数据库中的t_user表格中
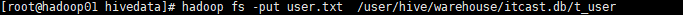
再查询表格,就有数据了
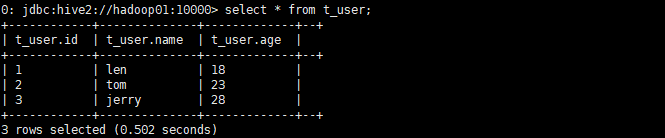


删除数据,下面看第二种方法导入数据


使用load data local inpath,指定数据所在的位置,进而加载数据到指定表格中
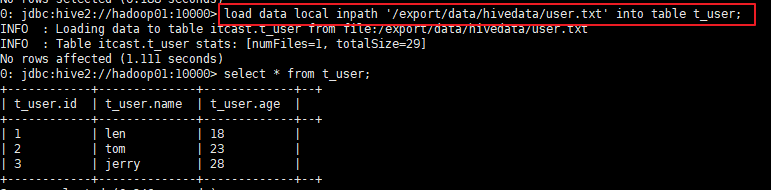
查看数据的总数,我们可以看到这里用到了map和reduce。把没一行数据为一个key,value为1,reduce再加和,进而统计。
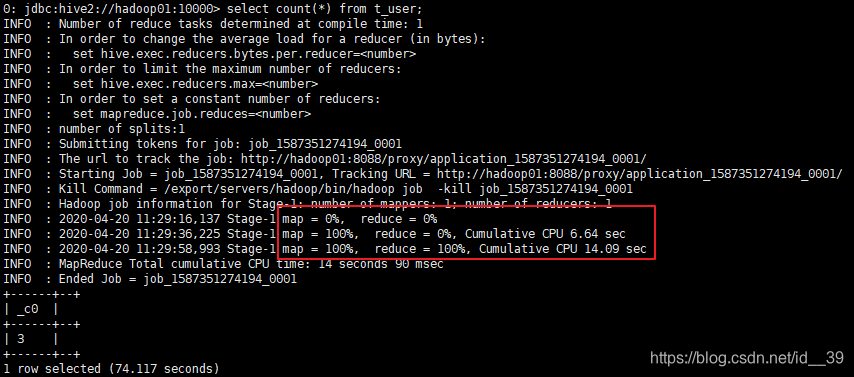
hive中的DBS表放数据库的路径
这里放的是我们创建的表格

5.hive外部表操作
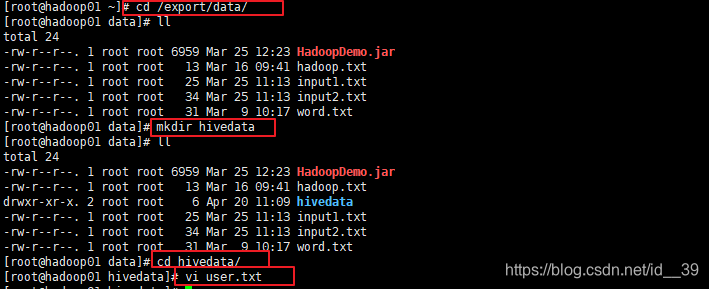
首先新建一些数据
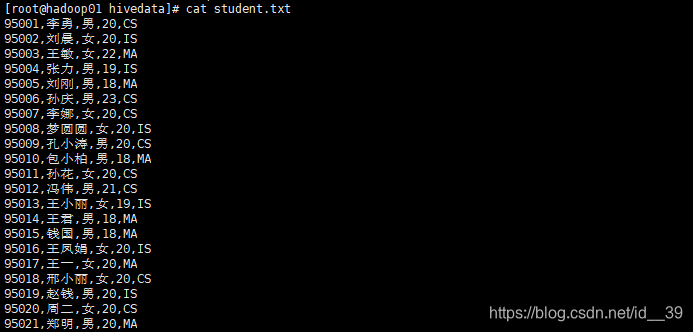
把数据放到分布式文件系统中的/stu下

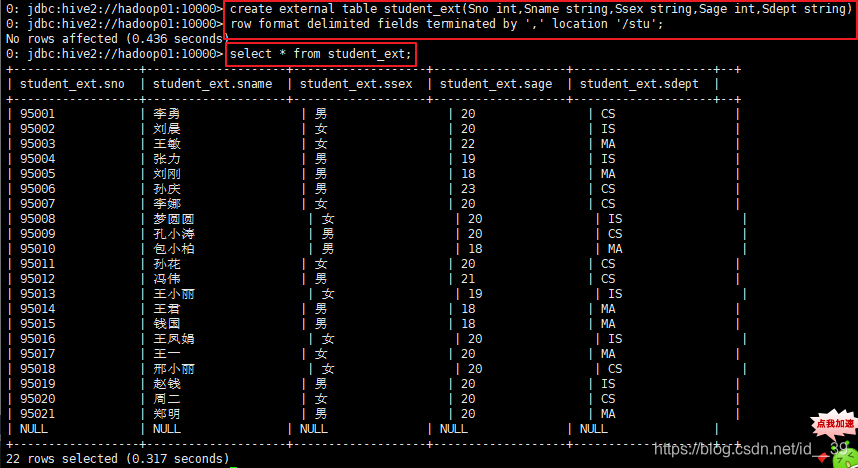
创建一个外部表,加了关键词external,同样使用逗号为分隔符,文件来自于本地的文件系统下的根目录下的stu下的数据。
我们每执行一个命令,这里就会显示一条,最后可以用ctrl+c退出
这里也可以用ctrl+c退出

思考:如何选择使用内部表或外部表?
如果所有处理都有hive来完成,则使用内部表;
如果需要用hive和外部其他工具处理同一组数据集,则使用外部表;
数据比较大时候用外部表。
hive基本数据类型
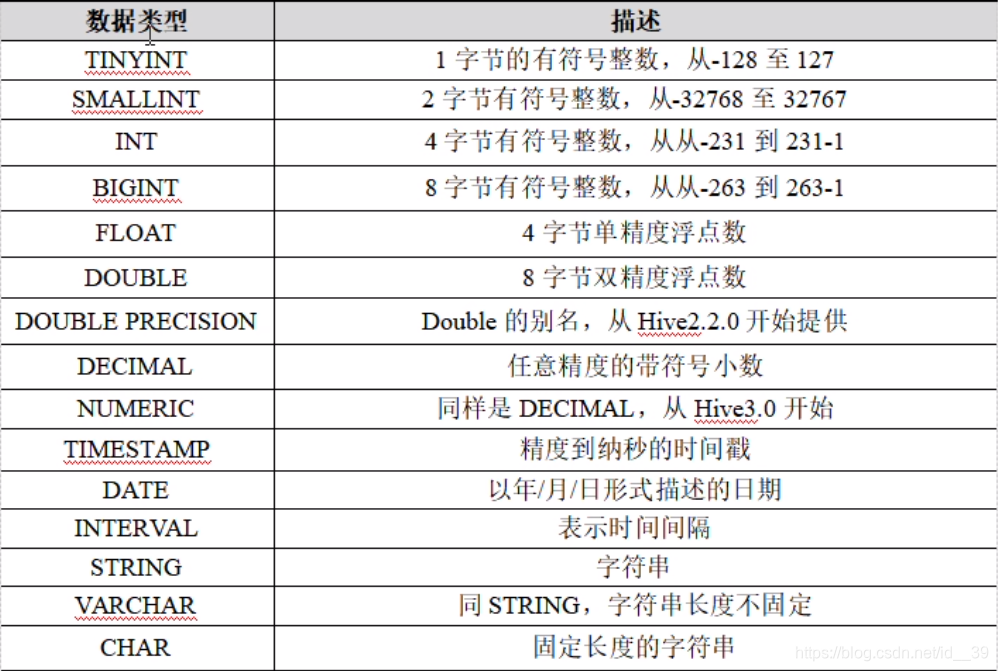

hive复杂数据类型:



Hive数据库操作

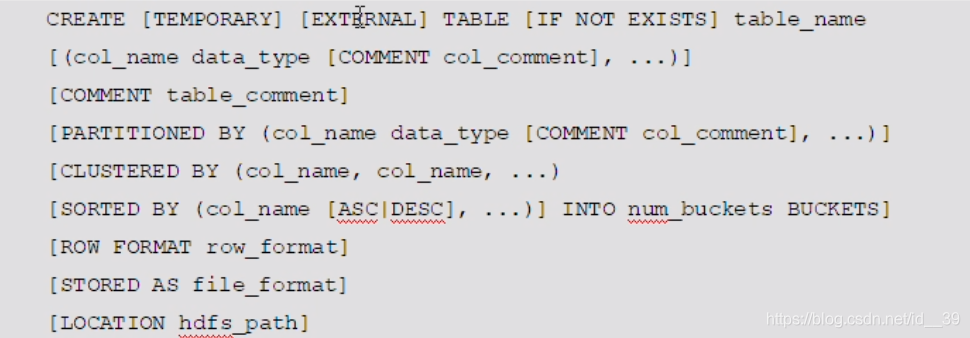


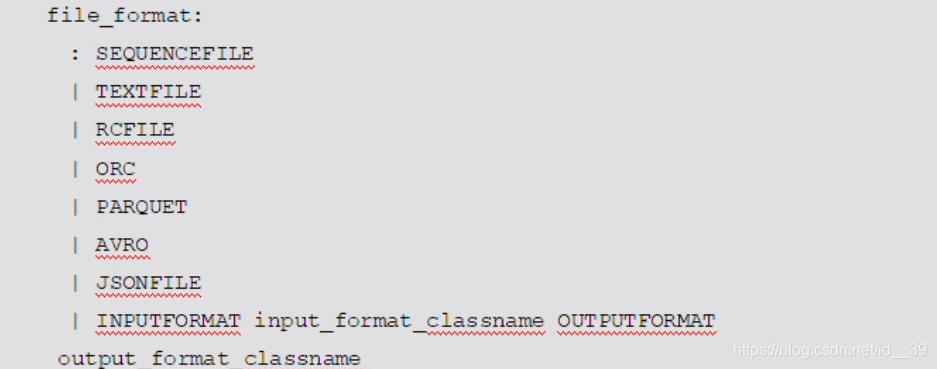
hive分区表操作
Hive分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过where子句中的表达式选择查询指定分区,这样查询效率会提高。
- Hive普通分区
创建分区表分为两种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另一种是多分区,表文件夹下出现多文件夹嵌套模式。
创建分区表:

例子:
准备数据:

创建分区表;
映射数据;
查看数据;
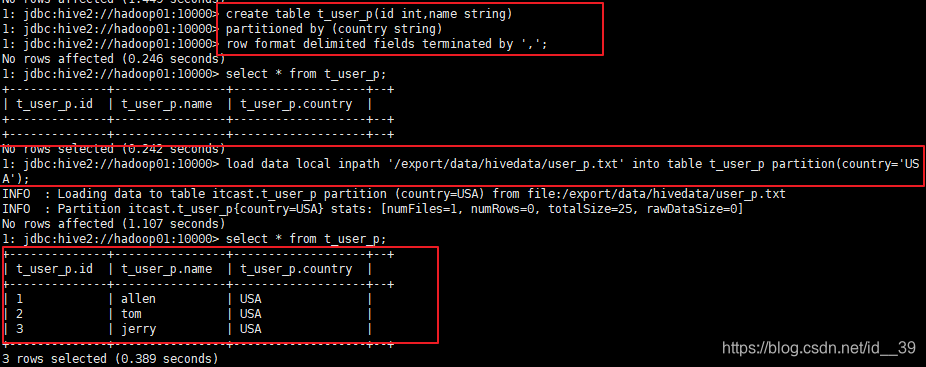
新增一个分区:


修改分区:

删除分区:

2. Hive动态分区
开启动态分区功能;
指明允许所有字段可以使用动态分区;

动态分区数据的插入:

例子:
开启动态分区,指明允许所有字段可以使用动态分区

准备数据:

创建原始表:

加载数据到原始表:
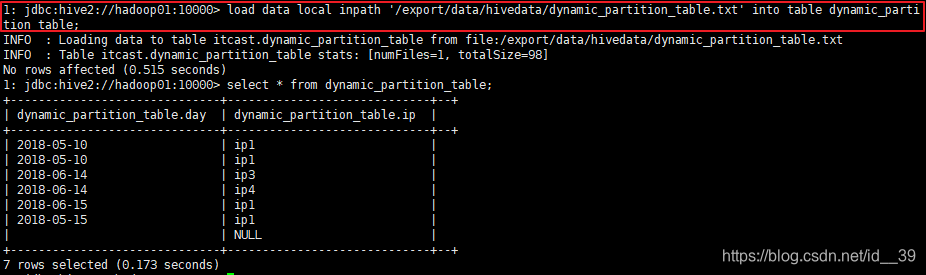
创建目标表;
动态插入数据;
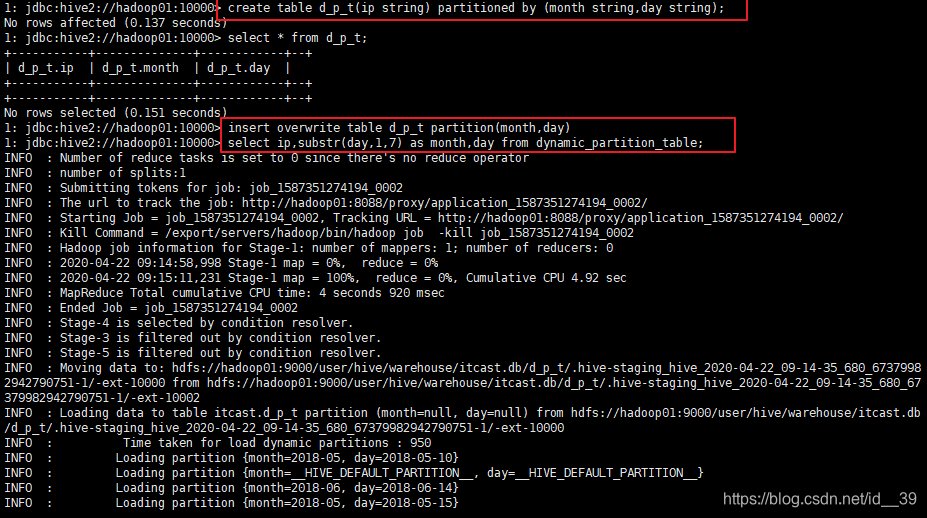
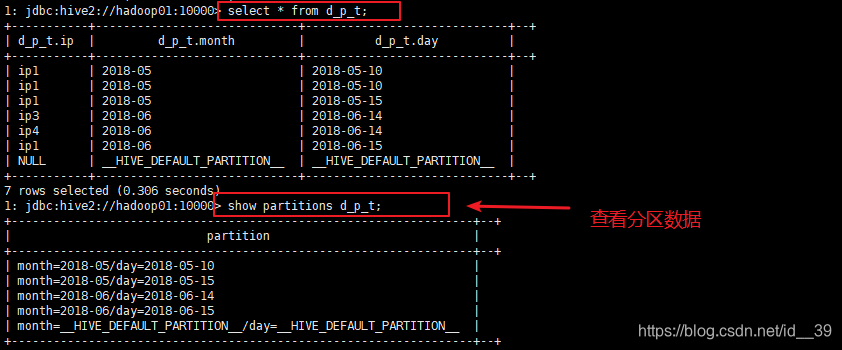
Hive桶表操作
桶表是根据某个属性字段把数据分成几个桶(默认值是-1,可自定义),将表进行更细粒度的范围划分,也就是在文件的层面上把数据分开。
开启分桶功能:

创建桶表

加载数据到桶表中,由于分桶表加载数据时,不能使用Load Data方式导入数据,因为Load Data本质上是对数据文件进行复制或移动到Hive表所对应的地址中。
查看分桶数据类型:

例子:
开启分桶功能;
创建临时表;
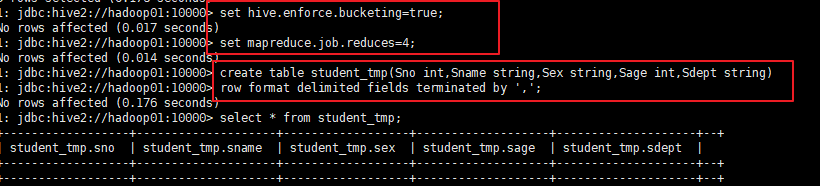
准备数据:
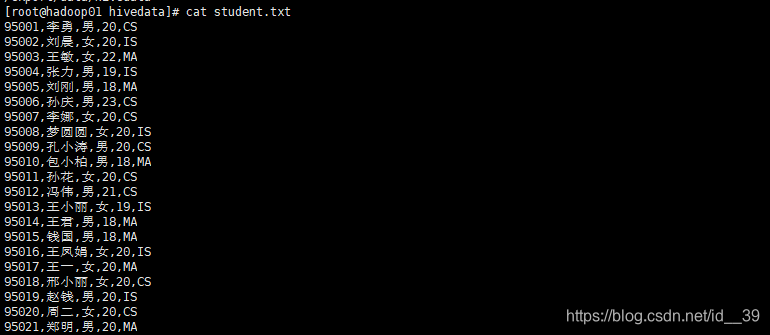
加载数据到临时表:
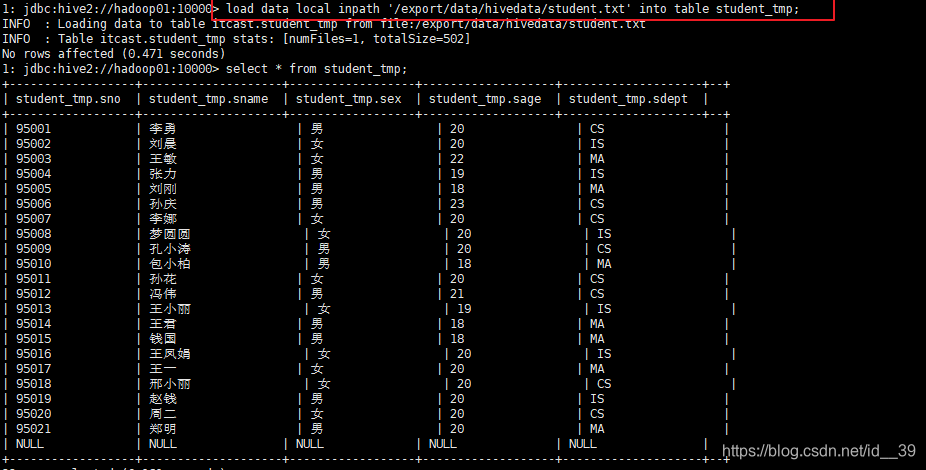
创建桶表:

将临时表中数据导入桶表:

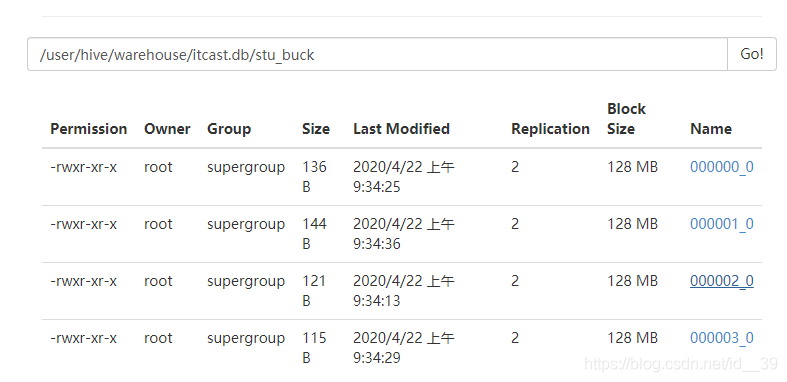
Hive数据操作
Hive数据操作主要包括向数据表加载文件、查询结果等操作。
查询:
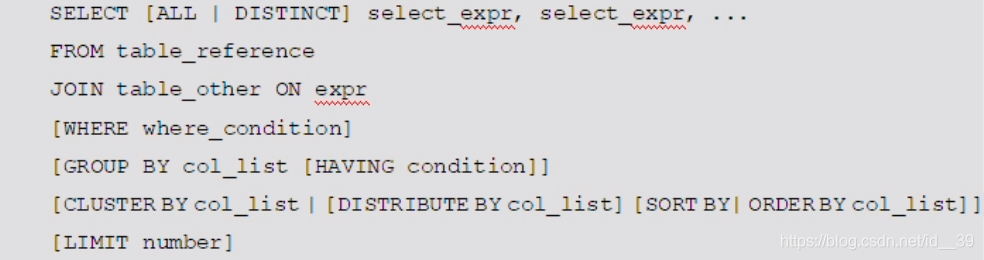
sort by语句:只能保证reduce有序,不能保证全局有序


Distribute by:通常和sortby

join:

满外连接:

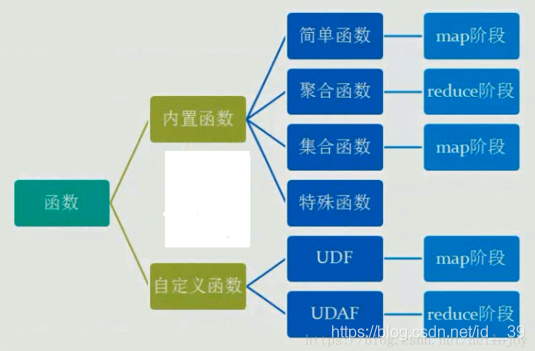
函数:
例子:
准备数据:
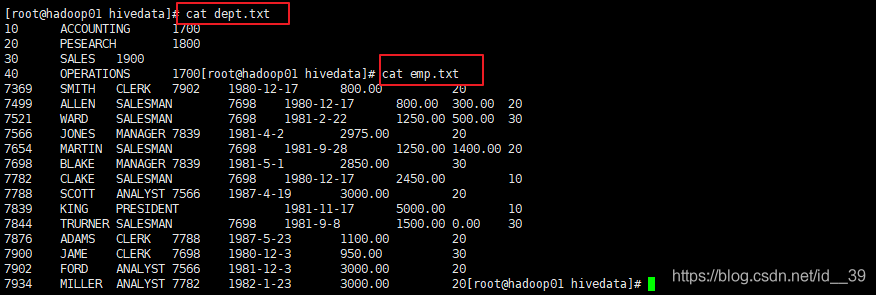
创建表:
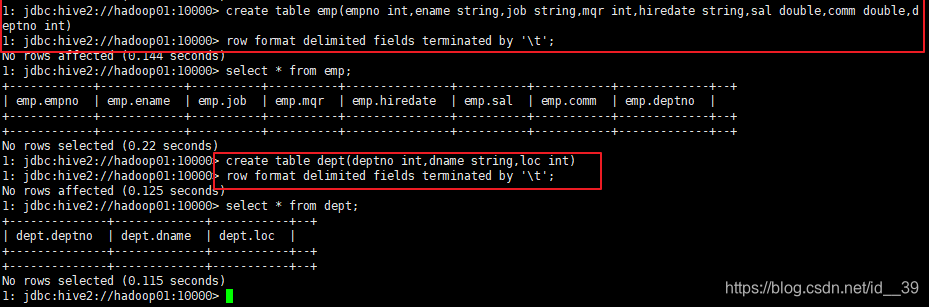
把数据映射到表中

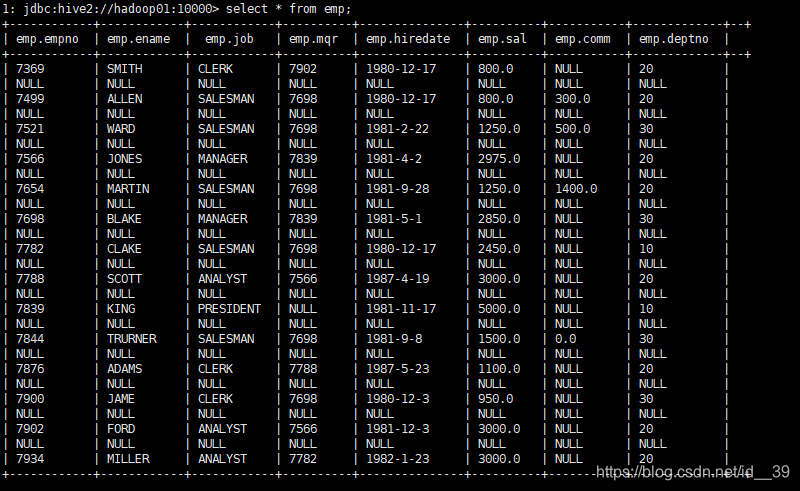
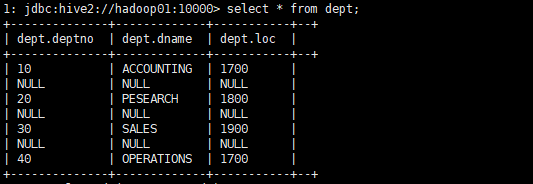
内置函数:
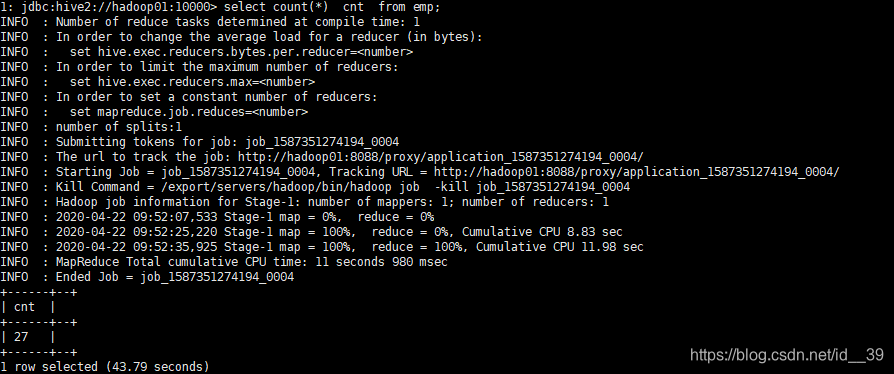
sort by:设置reduce个数:

部门降序查看员工信息:
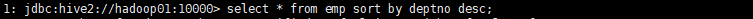
Hive的应用场景
适用场景:
- 海量数据的存储处理
- 数据挖掘
- 海量数据的离线分析
不适用场景:
- 复杂的机器学习算法
- 复杂的科学计算
- 联机交互式实时查询














 2006
2006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









