






 本文详细介绍了在Ubuntu 14.04 32位系统上从源码编译Hadoop 2.5.1的过程及遇到的问题解决方法,并分享了搭建伪分布式环境的具体步骤。
本文详细介绍了在Ubuntu 14.04 32位系统上从源码编译Hadoop 2.5.1的过程及遇到的问题解决方法,并分享了搭建伪分布式环境的具体步骤。
引言
一直用的Ubuntu 32位系统(准备下次用Fedora,Ubuntu越来越不适合学习了),今天准备学习一下Hadoop,结果下载Apache官网上发布的最新的封装好的2.5.1版,配置完了根本启动不起来,查看错误日志发现是native库的版本和系统不一致,使用file命令可以发现封装版的native库文件全是64位的:

原来官网发布的版本开始用64位环境编译了(貌似之前是32位环境编译)。没办法,只好自己下载源码编译了。
毫无意外的,编译时各种错误简直停不下来,强忍着一个个耐心解决了,配置的时候又由于自2.3开始带来的框架的质变,很多配置都不一样,网上教程真是看花了眼。。。不过最后还是强行配置好,终于跑起来了。系统地记下来,避免后来者绕弯路。
主要参考了2篇文章(其实就是2篇文章的整合):
Hadoop(2.5.1)伪分布式环境CentOS(6.5 64位)配置
环境
<a target=_blank href="http://www.ubuntu.com/download/desktop">Ubuntu 14.04 (32 bit)</a>[建议使用64位系统,最好是其他Linux发行版]<a target=_blank href="http://www.oracle.com/technetwork/java/javase/downloads/index.html">JDK 7u71</a>[一定要使用JDK7,不要用最新的JDK8,否则编译会出错,系统自带的OpenJDK也别用,注意配置环境变量,使默认Java环境为JDK7,一定要用“java -version”命令确认一下!]
<a target=_blank href="http://ant.apache.org/bindownload.cgi">Ant 1.9.4</a>[Ubuntu官方源的Ant是1.9.3版,也能用,不想手动配置环境就“apt-get install ant”也行]
<a target=_blank href="http://maven.apache.org/download.cgi">Maven 3.2.3</a>[使用官方最新的3.2.3版就行,不要用2,不要apt-get安装,Ubuntu官方源的当前版本可能太旧,可能导致编译失败]
<a target=_blank href="http://findbugs.sourceforge.net/index.html">FindBugs 3.0.0</a>
[就用最新的3.0.0版,<span style="font-family: Arial, Helvetica, sans-serif;">Ubuntu</span>官方源的当前版是2.0版,太旧,会导致编译失败]
<a target=_blank href="http://download.csdn.net/download/ruijiliang/6991999">Protobuf 2.5</a>[这个要注意:官方最新的是2.6版,但是hadoop 2.5.1就要求Protobuf是2.5版,所以务必使用链接提供的2.5版,否则编译会失败]
<a target=_blank href="http://www.apache.org/dyn/closer.cgi/hadoop/common">Hadoop 2.5.1 src</a>
[32位系统的就老老实实源码编译吧,别下到那个编译完成的版本了]注:以上工具版本最好保持一致,使用其他版本可能导致编译失败,当然可以随便尝试,能编译成功就行,上述工具正确安装配置后一般能保证编译成功。编译环境
先把编译环境配置起来。依次安装并配置JDK 7u71, Ant 1.9.4, Maven 3.2.3, Findbugs 3.0.0 和 Protobuf 2.5就行了:
JDK 7u71:
tar -zxvf jdk-7u71-linux-i586.tar.gz
sudo cp -r jdk1.7.0_71 /usr/lib/jvm/
#配置环境变量:
export JAVA_HOME=/usr/lib/jvm//jdk1.7.0_71
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre//bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH#注意:#1、JAVA路径要在原本的PATH之前,否则java命令默认会软连接到自带的OpenJDK上。最好“java -version”确认一下。#2、/etc/profile , .profile 或者.bashrc(.zshrc) 中配置都行,但必须source之后才能生效。.bashrc 或.zshrc的话source一次就行了,/etc/profile 或 .profile则需要每次启动终端时都source一次才能生效,直到下次开机。不同配置文件的加载机制不同,不多说。#3、下面工具的配置同理。Ant 1.9.4:
tar zxvf apache-ant-1.9.4-bin.tar.gz </span>
sudo cp -r apache-ant-1.9.4 /usr/share/<span style="font-family: 'Microsoft YaHei';">#配置环境变量:export ANT_HOME=/usr/share/apache-ant-1.9.4 export PATH=$PATH:$ANT_HOME/bin</span>
Maven 3.2.3:
tar -zxvf apache-maven-3.2.3-bin.tar.gz
sudo cp -r apache-maven-3.2.3 /usr/share/<span style="font-family: 'Microsoft YaHei';"> export M2_HOME=/usr/share/apache-maven-3.2.3 </span>
export MAVEN_OPTS="-Xms256m -Xmx512m"
export PATH=$PATH:$M2_HOME/binFindBugs 3.0.0:
tar zxvf findbugs-3.0.0.tar.gz
udo cp -r findbugs-3.0.0 /usr/share/#配置环境变量:
export FINDBUGS_HOME=/usr/share/findbugs-3.0.0
export PATH=$PATH:$FINDBUGS_HOME/bin Protobuf 2.5.0:
tar zxvf protobuf-2.5.0.tar.gzcd protobuf-2.5.0
./configure --prefix=/usr/share
make sudo make install我把工具都安装在/usr/share目录下,Ubuntu系统默认会搜寻该目录下的库文件,无需其他配置就行了。但是如果工具被安装在了/usr/local目录下,Ubuntu是不会自动搜索该目录的库文件的,此时需要配置开发库环境变量:
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/lib编译
tar zxvf hadoop-2.5.1-src.tar.gz
cd hadoop-2.5.1-src
mvn package -Pdist,native,docs -DskipTests -Dtar#等待编译完成就行了,完成后得到的编译版Hadoop位于hadoop-2.5.1-src/hadoop-dist/target中,其中的hadoop-2.5.1目录即为编译版。
自编译虽然麻烦,但是成功编译得到的版本比直接下载的打包编译版在本机上表现更稳定,error和warning基本没有了。另外下面这篇文章提供了编译过程中可能产生的常见问题和解决办法:http://blog.csdn.net/amaowolf/article/details/8125351
配置
万事俱备,开始正式搭建。
Hadoop三种运行模式:
1. 单机模式(standalone):单机模式是Hadoop的默认模。当配置文件为空时,Hadoop完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
2. 伪分布模式(Pseudo-Distributed Mode):Hadoop守护进程运行在本地机器上,模拟一个小规模的的集群。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
3. 全分布模式(Fully Distributed Mode):Hadoop守护进程运行在一个集群上。
自己学习还是搭伪分布式比较好(单机模式其实不需要什么配置)。也不单独添加Hadoop用户了,切换麻烦,就用自己常用帐户就行了。
步骤:
1、安装ssh
由于Hadoop用ssh通信,先安装ssh
- ~$ sudo apt-get install openssh-server
ssh安装完成以后,先启动服务:
- ~$ sudo /etc/init.d/ssh start
- ~$ ps -e | grep ssh
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
- ~$ ssh-keygen -t rsa -P ""

因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
- ~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- ~$ ssh localhost
登出:
- ~$ exit
- ~$ ssh localhost
登出:
- ~$ exit
2、安装hadoop 2.5.1
将刚才编译得到的hadoop-2.5.1复制到/opt目录下(大型软件和平台我一般放在这个目录),为方便配置,设置权限为777:
- ~$ sudo cp -r hadoop-2.5.1-src/hadoop-dist/target/hadoop-2.5.1 /opt/
- ~$ sudo chmod -R 777 /opt/hadoop-2.5.1
在/etc/profile 或 .profile 或 .bashrc中配置hadoop环境变量,注意配置完成后一定要source一下。
- export HADOOP_HOME=/opt/hadoop-2.5.1
- export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
- export PATH=$PATH:$HADOOP_HOME/bin
4.设置hadoop-env.sh(Java 安装路径)
打开/opt/hadoop-2.5.1/etc/hadoop目录下的hadoop-env.sh文件,添加以下信息:
- export JAVA_HOME=${JAVA_HOME} #当然如果没有配置JAVA_HOME也可以设置成具体的JDK路径
- export HADOOP_HOME=/opt/hadoop-2.5.1 #以下2行纯粹为了保险,实际上是重复设置了一次步骤3
- export PATH-$PATH:$HADOOP_HOME/bin
并且,让环境变量配置生效source
- ~$ source /opt/hadoop-2.5.1/etc/hadoop/hadoop-env.sh
至此,hadoop的单机模式已经安装成功。

5、伪分布式环境搭建
5.1.设定*-site.xml
这里需要设定4个文件:core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml.都在/opt/hadoop-2.5.1/etc/hadoop/目录下
core-site.xml: Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等。
hdfs-site.xml: Hadoop 守护进程的配置项,包括namenode,辅助namenode和datanode等。
mapred-site.xml: MapReduce 守护进程的配置项,包括jobtracker和tasktracker。
yarn-site.xml: Yarn 框架用于执行MapReduce 处理程序
首先在hadoop目录下新建几个文件夹
- ~$ mkdir tmp
- ~$ mkdir -p hdfs/name
- ~$ mkdir -p hdfs/data
接下来编辑那4个文件(IP地址处我填了我的局域网IP:192.168.1.135,根据需要填写自己主机的IP或者直接用localhost):
core-site.xml:
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.1.135:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/hadoop-2.5.1/tmp</value>
- </property>
- </configuration>
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.name.dir</name>
- <value>/uopt/hadoop-2.5.1/hdfs/name</value>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/opt/hadoop-2.5.1/hdfs/data</value>
- </property>
- </configuration>
上述路径都需要自己手动用mkdir创建(开头就已经创建了),具体位置也可以自己选择,其中dfs.replication的值建议配置为与分布式 cluster 中实际的 DataNode 主机数一致,在这里由于是伪分布式环境所以设置其为1。
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>Yarn</value>
- </property>
- </configuration>
请注意这里安装的2.5.1版本,2.*版本较1.*版本改动很大,主要是用Hadoop MapReduceV2(Yarn) 框架代替了一代的架构,其中JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager, ApplicationMaster 与 NodeManager 三个部分,而具体的配置文件位置与内容也都有了相应变化。所以我们在mapred-site.xml中设置了处理map-reduce的框架Yarn,接下来就需要在yarn-site.xml中配置ResourceManager, ApplicationMaster 与 NodeManager。
yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>Yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>Yarn.resourcemanager.address</name>
<value>192.168.1.135:18040</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>Yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.135:18030</value>
</property>
<property>
<description>The address of the RM web application.</description>
<name>Yarn.resourcemanager.webapp.address</name>
<value>192.168.1.135:18088</value>
</property>
<property>
<description>The address of the resource tracker interface.</description>
<name>Yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.135:8025</value>
</property>
</configuration>
5.2.格式化HDFS
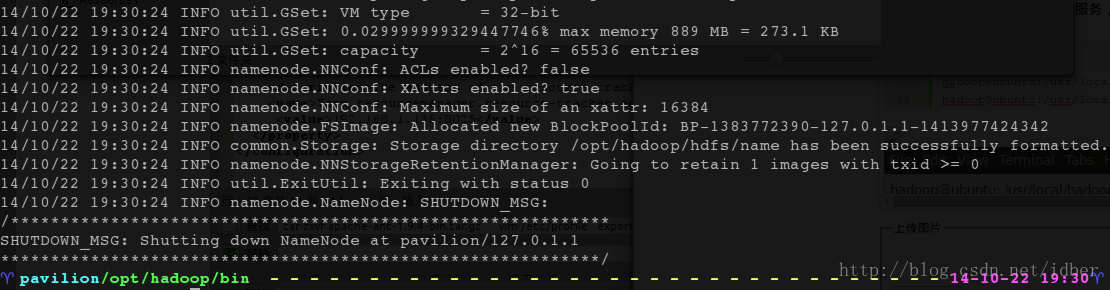
- ~$ /opt/hadoop-2.5.1/bin/hadoop namenode -format
如上图表示格式化成功。
5.3.启动Hadoop
接着执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。
- /opt/hadoop-2.5.1/sbin$ ./start-all.sh #2.5.1版推荐使用start-dfs.sh和start-yarn.sh来启动
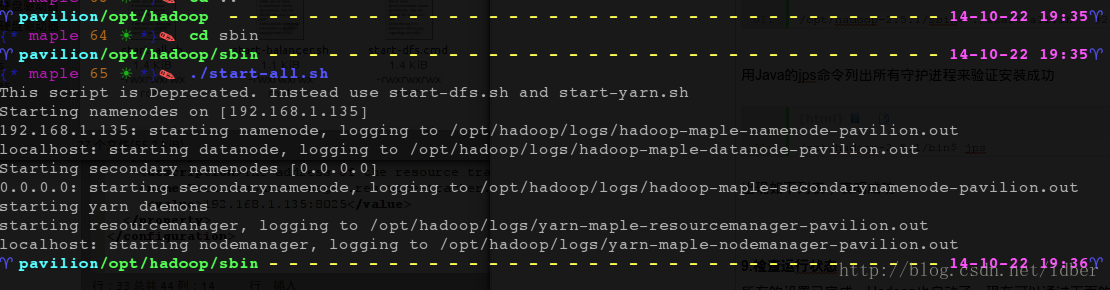
用Java的jps命令列出所有守护进程来验证安装成功
- /opt/hadoop-2.5.1/bin$ jps

5.4.检查运行状态
所有的设置已完成,Hadoop也启动了,现在可以通过下面的操作来查看服务是否正常,在Hadoop中用于监控集群健康状态的Web界面(填写自己的IP):
http://192.168.1.135:50070 #dfs运行状态
http://192.168.1.135:8088 #resource manager运行状态
(完)

















 132万+
132万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









