







Memcache简介
- 分布式的内存对象缓存系统,被称为a demand-filled look-aside cache.
- 通常作为数据库的前端使用,减小数据库的负载,提高性能
- 在Facebook中,read request约占99.8%,而write request只占了约0.2%,使用Memcache正是为了解决这一问题。
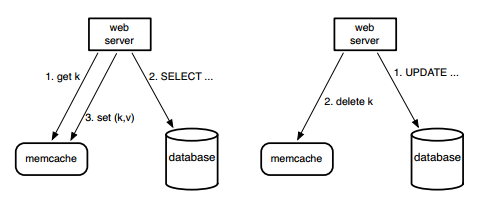
- Memcache的基本操作分为两种:
- Query Cache:先从Memcache中读取,如果出现read miss,则从MySQL数据库中读取,并且把内容写入cache。
- Update Cache:先update MySQL数据库,然后在cache中删除(采用delete操作,是因为delete是幂等操作,可以防止并发写带来的数据不一致性)
文章分析
- In a Cluster
- 需要解决的两个问题:Latency and Load
- Latency
- 开源的Memcache系统是web server与Memcache服务器直接通信的,这样的话,当client发起大量读请求的时候,这些无序的请求如果同时到达,势必会对机架和集群交换机的带宽带来过载的压力,从而造成Incast congestion问题,于是Facebook在web server层设计了一个类似于代理的客户端,称为Mcrouter,负责序列化、压缩等操作,同时根据configuration system更新下游通信的cache server。
- 同时为了能够尽量提高并行性,在web层更加数据之间的依赖关系,构建DAG,根据DAG来最大化可以并行请求的数据数(这里不是很理解,到底是根据怎么样的依赖关系来构造DAG图,可惜文章中没提到)。
- 针对不同的场景,Mcrouter会选择不同通信方式,由于Facebook中主要的请求是读请求,因此对于读请求,使用UDP(如果发送失败,大不了多发几次呗),而对于写请求,由于必须保证数据的可靠性,那么使用TCP,引入Mcrouter的好处就是减少了原来client每个线程需要维护TCP连接所带来的网络带宽、内存和CPU的消耗。
- 通过设计类似于滑动窗口的机制,来保证对于每次到来的大量请求可以通过控制窗口大小从而来减缓网络带宽的压力。
- Load
- 采用租约机制(lease)来防止stale sets 和 thundering herds:
- stale sets是指在Query cache和Update cache并发执行的时候,可能会导致的Query cache在read miss的情况下,往cache中写入老数据。
- thundering heads是指一些特殊的key写操作频繁,同时又有大量并发的读请求,当大量读请求出现cache miss时会导致后端数据库压力增大。
- 通过加入lease机制,可以很好避免这两个问题,lease是64-bit的taken,与客户端请求的key绑定,对于第一个问题,在写入时验证lease,可以解决这个问题;对于第二个问题,每个key 10s分配一次,当client在没有获取到lease时,可以稍微等一下再访问cache,这时往往cache中已有数据。
- Memcache pools:
- 针对不同的key类型设计不同的Memcache缓存池,在Facebook中,可能有些key更新频繁,但出现read miss时对数据库的负载又比较小,而有些key更新不怎么频繁,但出现miss时对数据库的负载比较大,如果放在一起,由于Memcache是根据LRU算法来替换缓存中的数据的,那么那些更新不频繁的key可能就会被替换掉,从而在read miss时对数据库造成的负载就比较大,于是我们可以针对这些key的特点,把不同的key分发到不同大小的缓存池,符合第一种情况的key,可以缓存到小一点的pool中(反正更新也很频繁),符合第二种情况的key就放到大一点缓存池,这样做在一点程度上也能减小后端数据库的负载。
- 采用租约机制(lease)来防止stale sets 和 thundering herds:
- In a Region
- 主要考虑的是一个region中多个cluster数据备份的问题
- Regional Invalidations
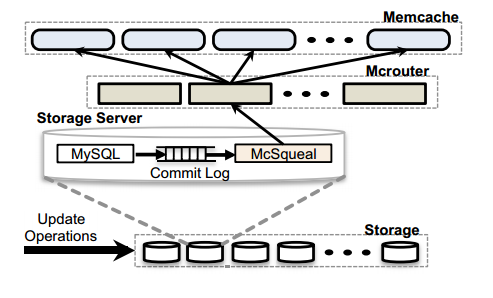
- 在一个region内部会让storage cluster负责cache数据失效的功能,在每个MySQL数据库中部署一个Mcsqueal(守护进程)用于负责cache数据失效,通过从commit log提取sql删除语句,批量广播到前端集群,Mcsqueal并不是直接把删除操作广播到所有的Memcache server中,而是通过先转发某些特定机器的Mcrouter中,由Mcrouter根据key转发到相应的cache server中;可以看出这中间存在一些时间差,对于用户而言,还是有极大可能从cache中读到脏数据的。
- Cold Cluster Warm Up
- 对于新加入的cache集群来说,由于一开始cache命中率比较低,为了避免cache miss对后端数据库造成过大的负载,可以允许从cache命中率正常的cache集群(Warm Cluster)读取数据。这期间可能会读到脏数据,因为delete操作没有及时同步到Warm Cluster,会出现从Warm Cluster中读到脏数据然后再写入到Cold Cluster中。
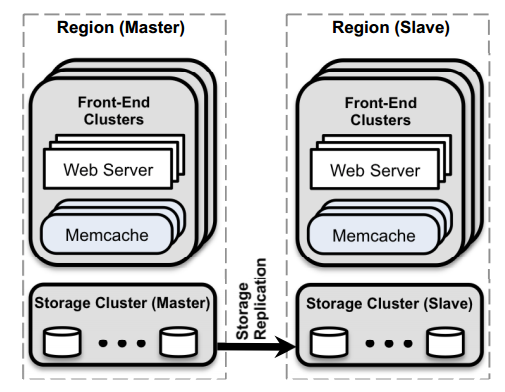
- Across Regions
- 主要考虑consistency问题,划分为Master Region和Slave Region,Master和Slave通过MySQL的复制机制来保持异步同步,主从同步主要的问题是Master数据库中已经写成功了,但是由于Slave数据库还没及时更新,那么在Slave region中发生read miss时,可能从数据库中读到的是脏数据。
- Write from a Master region:通过之前说的Mcqueal来保证数据的一致性。
- Write from a non-Master Region:
- 根据key在本地cache中写入远程标记rk,向Master数据库中写,并且在sql语句中嵌入应该失效的key以及远程标记rk,当slave region中发生 read miss时,检查cache中是否存在rk,如果存在就定位到Master数据库中,否则就定位到本地数据库。
- 主要考虑consistency问题,划分为Master Region和Slave Region,Master和Slave通过MySQL的复制机制来保持异步同步,主从同步主要的问题是Master数据库中已经写成功了,但是由于Slave数据库还没及时更新,那么在Slave region中发生read miss时,可能从数据库中读到的是脏数据。















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









