









【IT168 技术文档】
发现问题
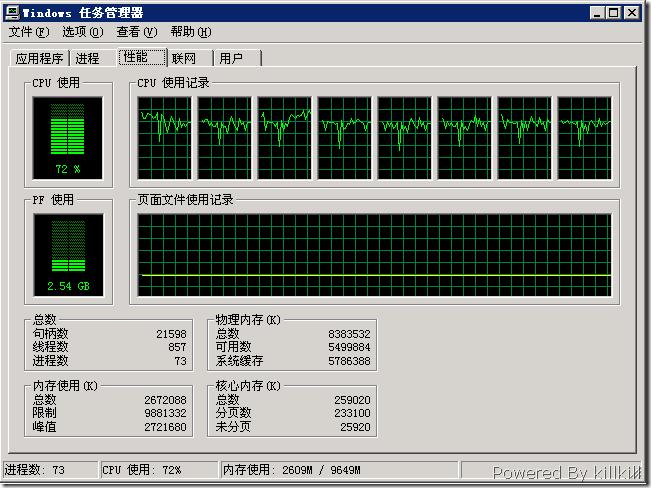
今天服务器检查的时候发现SQL Server 2005服务器的CPU负载很高,而且一直居高不下,这是我当时在现场的截图:
服务器是一台4路服务器有4颗XEON 3GHz的CPU,8G的内容,SQL Server 2005是32位,打了SP2。
该服务器上跑了很多个业务系统的数据其中属于JT的数据库就有好几个,业务量还是挺大的。
排除是其他进程搞的鬼,确定是SQL Server 进程把服务器搞得这么忙。
定位问题
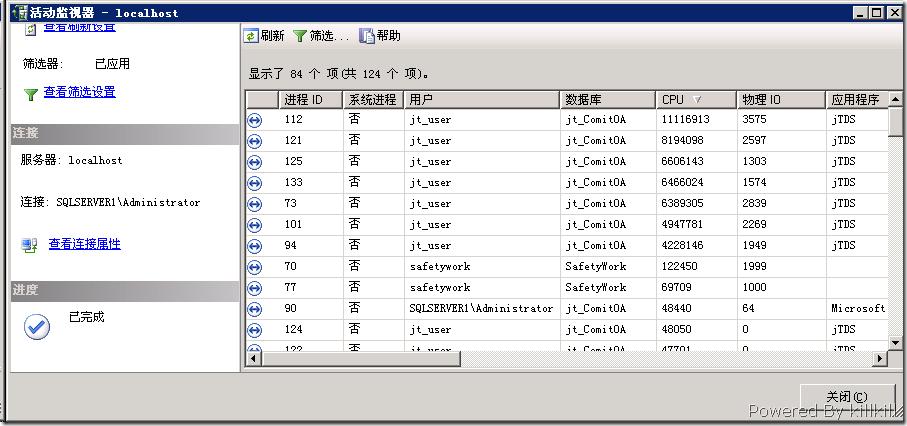
打开活动监视器按照CPU排序,得到如下信息,可见jt_user在jt_ComitOA上面的连接所作所为都是大动作啊。
接下来换一个工具,SQL Server Profiler 出场,调整跟踪的属性,调整为只是监视“SQL:Batch Completed”,而且将“DatabaseName”这个列选上,再调整一下列筛选器,如图:
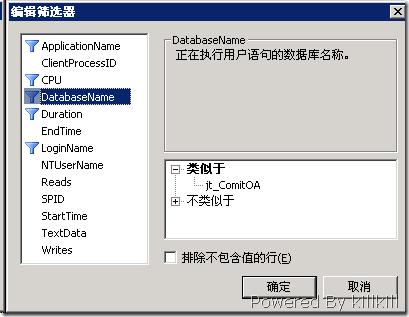
这个列筛选器有个小Bug,输入完条件后最好按一下回车,否则有可能输入无效,OK开始我们的跟踪之旅。我这里简单地设置了一下DatabaseName,LoginName,CPU和Duration ,以便过滤掉一些无关紧要的值。
经过半个小时的收集,我得到了如下的跟踪信息:
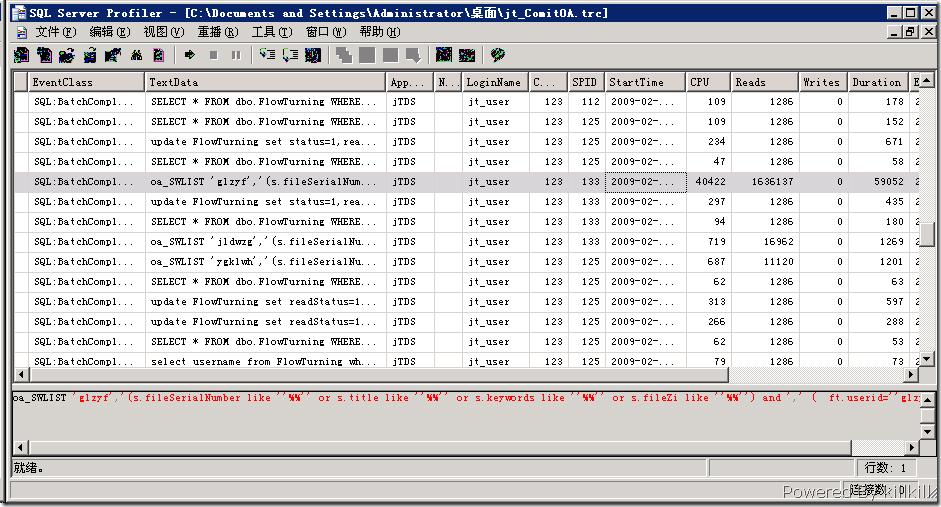
我将部分语句Copy出来,顺便整理了一下格式。
' glzyf ' ,
' (s.fileSerialNumber like '' %% '' or s.title like '' %% '' or s.keywords like '' %% '' or s.fileZi like '' %% '' ) and ' ,
' ( ft.userid= '' glzyf '' )
' exec oa_DBSX ' cwkfss ' , '
' exec oa_FlowTurning ' jgstyb '
update FlowTurning set readStatus = 1 where type = ' sw ' and pkid = ' 21712 ' and userid = ' cwkfss '
其中第一条语句的的占用率最严重,比其他的语句足足多了一个数量级。
分析问题
将数据库备份到一台测试的服务器上,查看一下数据库的数据文件和日志文件情况,发现日志文件比较大,貌似这也是一个SQL Server 存在的问题,具体原因不清楚,但是解决方法已经非常成熟,该问题暂时不影响使用,先不管它。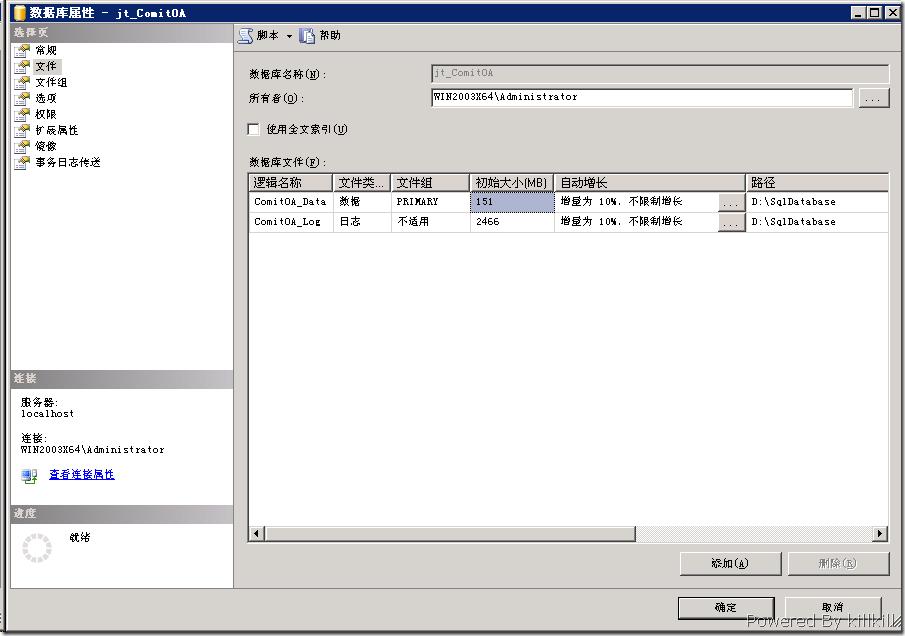
定位出了问题,找出了多条Top SQL,其中这条最过分。
' glzyf ' ,
' (s.fileSerialNumber like '' %% '' or s.title like '' %% '' or s.keywords like '' %% '' or s.fileZi like '' %% '' ) and ' ,
' ( ft.userid= '' glzyf '' ) '
分析一下这个存储过程,我习惯是先看看SQL语句的结构,而不是马上看执行计划,或者直接跑语句获得统计信息。
@userID varchar ( 20 ),
@sql varchar ( 1000 ),
@userIDs varchar ( 1000 )
AS
DECLARE @SQL1 nchar ( 4000 ) ;
DECLARE @SQL2 nchar ( 4000 ) ;
create table #employees(
[ id ] [ int ] IDENTITY ( 1 , 1 ) NOT NULL ,parentId int ,pkId int ,status int ,title nvarchar ( 1500 ),comeOrg nvarchar ( 100 ),
fileDate DateTime ,fileName nvarchar ( 4000 ),filePath nvarchar ( 4000 ),readStatus nvarchar ( 10 ),optionStatus nvarchar ( 10 ),
depId nvarchar ( 20 ),urgencyLevel nvarchar ( 10 ));
set @SQL1 = ' insert into #employees (parentId,pkId,status,title,comeOrg,fileDate,fileName,filePath,readStatus,optionStatus,depId,urgencyLevel)
select distinct s.parentId,s.pkId,0,s.title,s.comeOrg,s.fileDate,
s.fileName,s.filePath,ft.readStatus,0,s.remark3,
case
when urgencyLevel= '' 普通 '' then 0
when urgencyLevel= '' 急件 '' then 1
when urgencyLevel= '' 特办 '' then 2
when urgencyLevel= '' 特急件 '' then 3
when urgencyLevel= '' 限时 '' then 4
else 0
end as urgencyLevel
from ShouWen as s ,
FlowTurning as ft where ' + @sql + ' ft.status=0 and ft.type= '' sw ''
and s.pkid=ft.pkid and s.status<> '' 4 '' and ' + @userIDs + ' order by urgencyLevel desc,s.filedate desc '
set @SQL2 = ' insert into #employees (parentId,pkId,status,title,comeOrg,fileDate,
fileName,filePath,readStatus,optionStatus,depId,urgencyLevel)
select distinct s.parentId,s.pkId,1,s.title,s.comeOrg,s.fileDate,
s.fileName,s.filePath,1,l.optionstatus,s.remark3,urgencyLevel
from shouwen as s, log as l where ' + @sql + ' s.status<> '' 4 '' and s.pkid in
(
select distinct(mid) from log where uid= ''' + @userID + ''' and typeid= '' shouwen ''
)and l.mid=s.pkid and uid= ''' + @userID + ''' and typeid= '' shouwen ''
order by s.fileDate desc '
print ( @SQL1 );
exec ( @SQL1 )
print ( ' +++++++++++++++++++++++++++++++++++ ' );
print ( @SQL2 );
exec ( @SQL2 )
select * from #employees
delete from #employees从结果来看该存储过程其实就是执行了两条动态SQL,分别存在@SQL1和SQL2。我稍微修改了一下存储过程,加入了一些调试信息,打开统计器。
SET STATISTICS TIME on; 执行存储过程,这里由于信息量比较大,我就不贴了,上一张图吧。
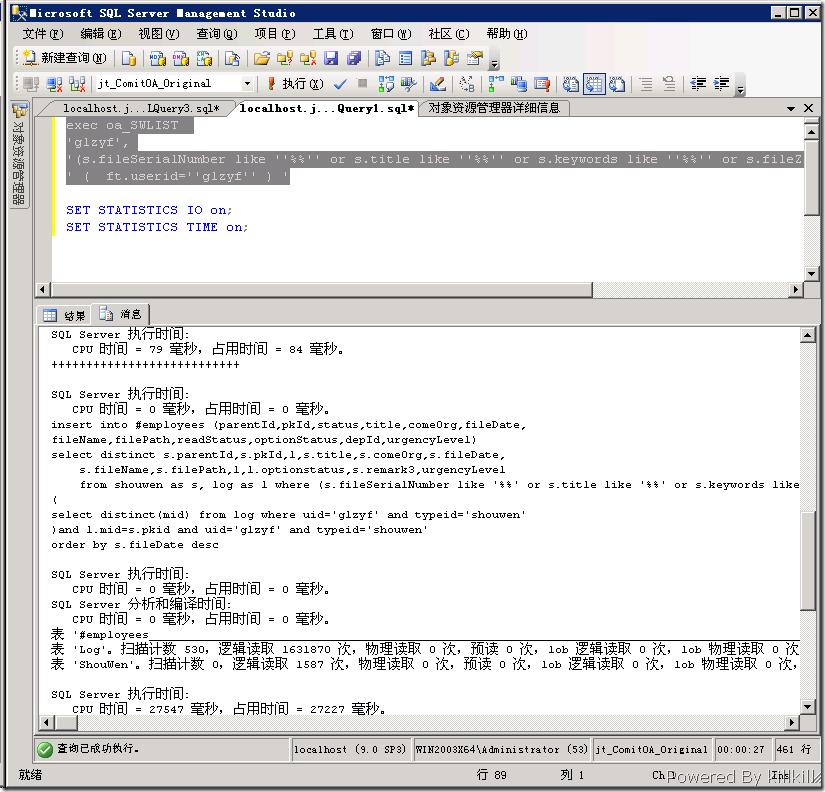
可见@SQL1的语句耗时并不多,@SQL2资源占用是非常厉害的。其中 Log 表扫描530次,这个表的数据量有257417条,说大不大,说小也不小了,而且还得扫描530次,唉,啥也不说了,而shouwen这张表就小很多也有25000+条记录。
我将@SQL2的语句整理出来,去掉那个讨厌的 insert into #employees。
s.fileName,s.filePath, 1 ,l.optionstatus,s.remark3,urgencyLevel
from shouwen as s,
log as l
where
(s.fileSerialNumber like ' %% ' or s.title like ' %% '
or s.keywords like ' %% ' or s.fileZi like ' %% ' )
and s.status <> ' 4 '
and s.pkid in
( select distinct (mid) from log where uid = ' glzyf ' and typeid = ' shouwen ' )
and l.mid = s.pkid and uid = ' glzyf ' and typeid = ' shouwen '
order by s.fileDate desc 看看这个select 语句的执行计划啦。
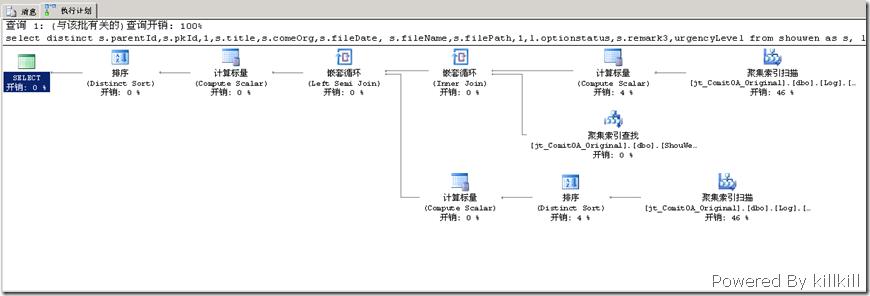
以下才是重点,两个在Log表上面的“聚集索引扫描”:
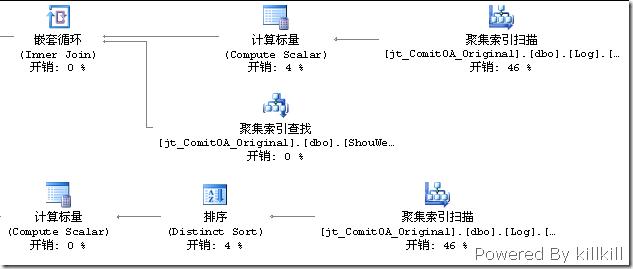
无论哪个RDBMS的语句调优,绝大部分的情况下都是将执行计划中的“扫描”转变为“查找”。下一篇讲解如何将“扫描”变为“查找”。
提出方案
以下是找出来的TOP SQL 。
s.fileName,s.filePath, 1 ,l.optionstatus,s.remark3,urgencyLevel
from shouwen as s,
jt_ComitOA.dbo. log as l
where
(s.fileSerialNumber like ' %% ' or s.title like ' %% '
or s.keywords like ' %% ' or s.fileZi like ' %% ' )
and s.status <> ' 4 '
and s.pkid in
( select distinct (mid) from log where uid = ' glzyf ' and typeid = ' shouwen ' )
and l.mid = s.pkid and uid = ' glzyf ' and typeid = ' shouwen '
order by s.fileDate desc
从执行计划中可以看到两个比较大操作,两个对Log表“聚集索引扫描”,观察语句不难以下发现就是导致两个“聚集索引扫描”的原因。
(select distinct(mid) from log where uid='glzyf' and typeid='shouwen')and l.mid=s.pkid and uid='glzyf' and typeid='shouwen'这次运气比较好,mid、uid和typeid都在这两个语句里面,于是我计划在Log表的mid、uid和typeid上面建索引
(
[ uid ] ASC ,
[ typeID ] ASC ,
[ mid ] ASC
);
看一下执行计划新的执行计划:
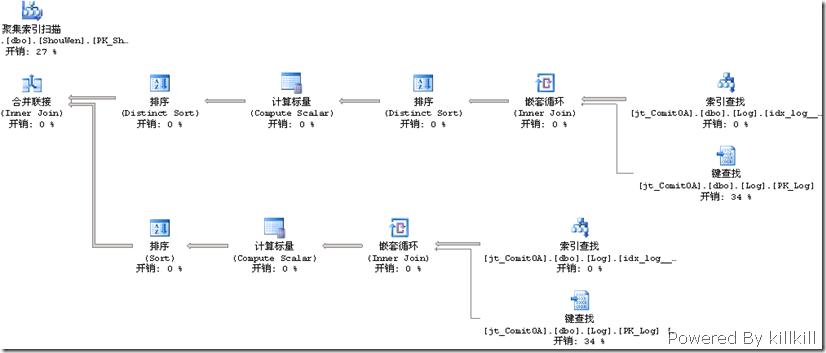
留意左上角对ShouWen这个表的聚集索引扫描,由原先的相对比例0%(其实是接近0%),上升到27%,可见整体的资源消耗已经大大降低了。
表 'Log'。扫描计数 2,逻辑读取 3272 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ShouWen'。扫描计数 1,逻辑读取 1436 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 62 毫秒,占用时间 = 293 毫秒。对Log表的访问量大大减少,这可是有25万条数据的表啊,总的执行时间更是大大减少,疗效相当的不错啊。
至此,可以认为该调优已经达到很好的效果了,从26秒的执行时间缩减到0.3秒,非常不错的成绩了。
审视方案
在新的执行计划中有两个键查找,键查找用来检索筛选索引没有涵盖的剩余列,说白了,就有一些输出列不在这个索引的覆盖范围中。看一下select的输出,的确有一个Log表的optionstatus字段,于是将索引的创建语句调整为:
(
[ uid ] ASC ,
[ typeID ] ASC ,
[ mid ] ASC
)
INCLUDE ( [ optionstatus ] )
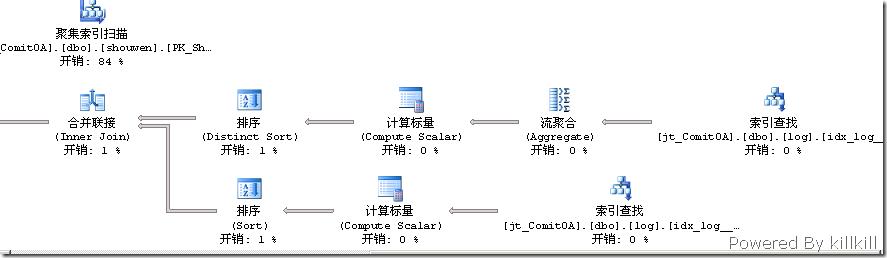
同样以左上角的ShouWen表的“聚集索引扫描”为参照点,就执行计划来看,的确资源占用率再次大大降低了,看看执行的统计信息。
表 'Log'。扫描计数 2,逻辑读取 16 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'ShouWen'。扫描计数 1,逻辑读取 1436 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 78 毫秒,占用时间 = 282 毫秒。Log表的逻辑读取数大大减少,执行时间并没有太大变化。这是由于这次缩减的是逻辑读,即在缓存中读取,通常缓存是在内存中的,内存可是比磁盘快多了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









