






首先实际的工作流程:
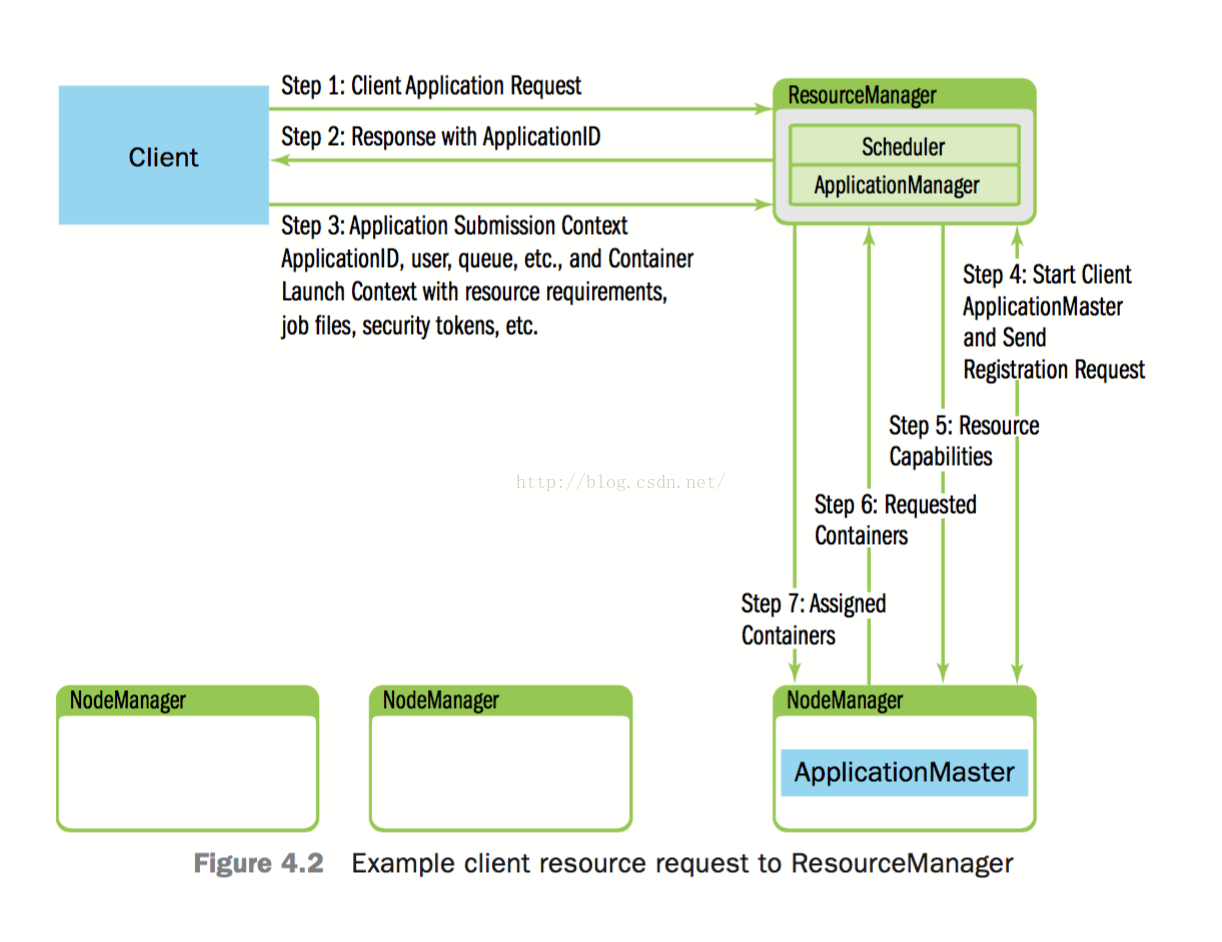
用户提交任务到完成步骤 :
u Step 1: client首先通知RM自己希望提交app
u Step 2: 随后RM会响应一个ApplicationID及关于当前系统资源容量的信息(供client发起资源请求时作为参考)
u Step 3: client回应“Applicatin Submission Context” 及 “Container LaunchContext (CLC)”。app submission context 包含Application ID,user, queue, 以及启动AM所需的其他信息;CLC中包含了resource requirements, job files, security tokens,以及在一个node上启动AM所需的其他信息
u Step 4: 当RM收到app submission context后,将会试图为AM调度分配一个可用的container(该container被称为“container 0”,它就是AM,并且它后续将继续请求更多的containers)。如果没有可用的conainer,该请求将会等待。如果有可用的container,RM会选择并联系一个node,然后在该node上启动AM。并且,用于监控app状态的AM RPC port与tracking URL将被建立起来
u Step 5: RM向AM回送关于集群中maximum and minimum capabilities的信息。此时,AM必须决定怎样来使用这些可用资源。从这里可以看出,YARN允许app适应当前的集群环境
u Step 6: 基于RM在step 5中回送的关于当前集群可用资源的信息,AM将请求若干containers
u Step 7: 随后,RM将根据调度策略对此请求进行回应,并将containers分配给AM
当作业开始运行后,AM将向RM发送心跳/进度信息。在这些心跳信息中,AM可以请求更多的containers,也可以释放containers。当作业运行完毕后,AM向RM发送Finish消息后退出。
注释:Job 统一为作业。Task为任务。
RM
由两大组建构成:
1. Scheduler
2. Applications Manger Service
Scheduler:根据应用的资源请求(有约束)为应用分配资源。而且是负责资源的分配。以resource container的形式分配资源。(container是硬件资源的抽象,详情可见上一篇blog)
ApplicationManger Service: 负责接受作业,为执行应用的特定AM(一种应用一种AM)申请container0.(就是AM所在的!)。而且会在AM container失败的时候重启它。
Resource model
简单说:
Theresource model is completely based on memory (RAM) and every node is made updiscreet chunks of memory.
节点上的资源被考虑成,最小以(512MB 或1GB)存储大小的container组成。(在yarnv1中的方式)(这样就不区分map和reduce的资源了)。AM可以请求跨多个块的不同类型的的container,实际上AM只会请求特定的container.(看自己的特殊需要)。
Resource Negotiation
AM负责为应用计算所需资源的大小,并将它们转译成Scheduler可以明白的形式。<priority, (host, rack, *), memory, #containers>。(从inputsplit,输入文件划分到现在的形式)如果一些原因AM未能被分配到合适的资源,AM是可以reject资源的。
上述方式的优点在于,简化了Hapdoop系统的复杂度。原来的复杂度可以理解为O(集群大小)现在可以理解成O(task数量)。
缺点是上述的转译是单向的,不可逆转的。而且会丢失一些信息就是RM不知道资源请求之间的联系。(这个有什么用呢?得想想)
解决办法:
在AM之中添加一个scheduler组件,使得转译过程和任务分配(我是这么理解的,原文是AM只考虑task/split)分开,而且这个组件是可删除的。
Scheduling
算法表述:
1. 在系统中找到最该开始的队列。
2. 找到队列之中优先级最高的任务
3. 为任务的资源请求分配资源
Resource Monitoring
由Scheduler接受来自NM的资源使用信息。
Application Submission
任务提交的流程:
1. 用户把Job提交给Application Manager Service.
a) 客户端首先取得一个新的Application ID
b) 将应用的信息上传到HDFS,内容--${user}/.staging/${application _id}
c) 将应用提交给Application Manager Service
2. Application Manager Service接受任务的提交
3. Application Manager Service向RM为AM申请“槽位”,并启动AM
4. Application Manager Service也会为了用户可以监测到作业的进程,为客户端提供AM的细节信息(这个是什么信息呢?)
Lifecycle of the Application Master
ApplicationManager Service就是负责AM的整个生命周期。就如前面提到的Application Manager Service负责启动AM。AM 会周期的将自己的信息以心跳的方式传递给Application Manager Service,以便于Application Manager Service可确保AM的活性,在失败时重启AM。
Application Manager - components
考虑一下Application Manager Service的组成:
1. 调度协调—负责为AM,向Scheduler申请container0。(AM本身也是处于一个container之中,一般container0就是指的AM)
2. AMContainer Manager—根据与相应NM的通信,启动或者停止AM的container。(上面不是说是NM与Scheduler通信,这怎么也管理container)
3. AMMonitor—监控AM的活性在必要的时候重启AM
可用性:RM由zookeeper管理!(互相学啊)
Node Manager
NM一般会在Scheduler为应用分配containers。NM还负责分配出去的containers不会超出给他们的分配的资源块。
NM负责为task的container配置环境;NM还负责管理本地的节点。应用可以再即使没有分配节点给他们的节点上暂存一些数据。(比如MR会在节点上存储一些map的输出以便reduce使用)。
Application Master
负责管理单个应用,为单个应用申请资源,在合适的container之中执行程序并且负责将空程序的运行状况。如果container失败了,则重新向Scheduler申请资源。
负责为应用计算所需的资源,以便于申请合适的container。
负责从应用的失败中恢复,AM的失败由Application Manager Service恢复。一般希望AM可以从一个状态中恢复,当然也可以从一个开始状态恢复。
在YARN上跑一个MR应用
MR AM向RM申请合适的资源(多个container),并分配task到container。AM负责监视任务的执行和MR作业的周期直到任务结束。还有就是保存作业的运行状态,以便在AM失败的时候迅速恢复自己。
方法:基于事件的有限状态机来描述MR AM的状态。(画的估计自己都难懂图,不好~~)
这个作业的生命周期:(之前的知识看了这么多这点英文就好理解了)
1. Hadoop MR JobClient submits the job to the yarn ResourceManager (ApplicationsManager) rather than tothe Hadoop Map-Reduce JobTracker.
2. The YARN ASM negotiates the container for the MR AM with the Scheduler and then launches the MR AM for the job.
3. The MR AM starts up and registers with the ASM.
4. The Hadoop Map-Reduce JobClient polls the ASM to obtain information about the MR AM and then directly talks to the AM for status, counters etc.
5. The MR AM computes input-splits and constructs resource requests for all maps to the YARN Scheduler.
6. The MR AM runs the requisite job setup APIs of the Hadoop MR OutputCommitter for the job.
7. The MR AM submits the resource requests for the map/reduce tasks to the YARN Scheduler, gets containers from the RM and schedules appropriate tasks on the obtained containers by working with theNodeManager for each container.
8. The MR AM monitors the individual tasks to completion, requests alternate resource if any of the tasks fail or stop responding.
9. The MR AM also runs appropriate task cleanup code of completed tasks of the Hadoop MR OutputCommitter.
10. Once the entire once map and reduce tasks are complete, the MR AM runs the requisite job commit or abort APIs of the Hadoop MR OutputCommitter for the job.
11. The MR AM then exits since the job is complete.
MR作业的AM的构成:
Event Dispatcher(事件分发员):AM的核心组件,为其他组件调度事件。
Container Allocator: 为RM转译资源需求。
Client Service: 负责像用户反馈Hadoop作业的运行情况,作业状态,计数器等。
Task Listener: 获取map/reduce task中的信息(心跳)
//Task Umbilical(脐带~):接受信息(心跳),更新状态。
Container Launcher: 在合适的NM上分发container。
Job History Event Handler: 向HDFS内写入作业的历史信息
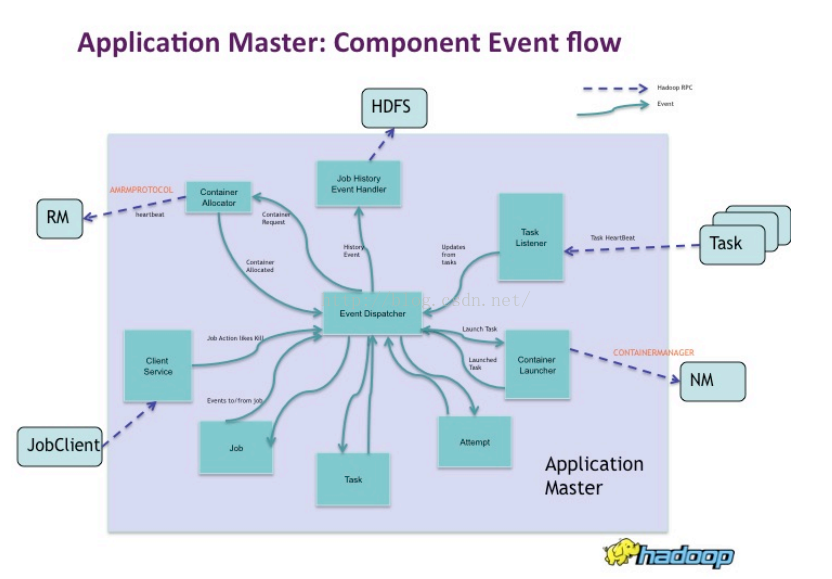
真是不清楚啊~~~
参考文章:
https://issues.apache.org/jira/secure/attachment/12486023/MapReduce_NextGen_Architecture.pdf
http://www.cnblogs.com/LeftNotEasy/archive/2012/02/18/why-yarn.html
Apache Hadoop YARN: Yet Another Resource Negotiator
https://www.zybuluo.com/xtccc/note/248181















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









