多时候,如果不对数据进行归一化,会导致梯度下降复杂或是xgboost中的损失函数只能选择线性,导致模型效果不佳。下面我结合各类我看到的资料总结一下几种方式的归一化,并有python的实现。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
如下有个形象的图解:
如果不归一化,各维特征的跨度差距很大,目标函数就会是“扁”的:
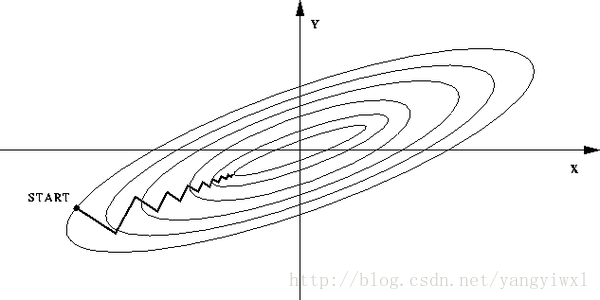
(图中椭圆表示目标函数的等高线,两个坐标轴代表两个特征)
这样,在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路。
如果归一化了,那么目标函数就“圆”了:
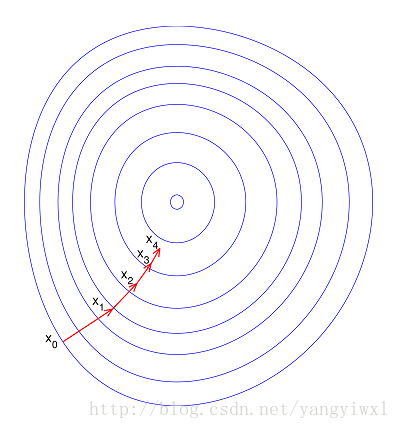
在知乎里,有人这么回答:
主要看模型是否具有伸缩不变性。有些模型在各个维度进行不均匀伸缩后,最优解与原来不等价,例如SVM。对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据dominate。有些模型在各个维度进行不均匀伸缩后,最优解与原来等价,例如logistic regression。对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
作者:王赟 Maigo
链接:https://www.zhihu.com/question/30038463/answer/50491149
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
max-min(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
tips : 适用于本来就分布在有限范围内的数据。
x∗=x−xminxmax−xmin
x_min表示样本数据的最小值,x_max表示样本数据的最大值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
x=[1,2,1,4,3,2,5,6,2,7]
b=Normalization(x)
output:
[0.0, 0.16666666666666666, 0.0, 0.5, 0.3333333333333333, 0.16666666666666666, 0.6666666666666666, 0.8333333333333334, 0.16666666666666666, 1.0]
如果想要将数据映射到[-1,1],则将公式换成:
x∗=x−xmeanxmax−xmin
import numpy as np
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
x=[1,2,1,4,3,2,5,6,2,7]
b=Normalization2(x)
output:
[-0.3833333333333333, -0.21666666666666665, -0.3833333333333333, 0.1166666666666667, -0.049999999999999968, -0.21666666666666665, 0.28333333333333338, 0.45000000000000001, -0.21666666666666665, 0.6166666666666667]
适用场景
这种归一化方法比较适用在数值比较集中的情况。但是,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定,实际使用中可以用经验常量值来替代max和min。而且当有新数据加入时,可能导致max和min的变化,需要重新定义。
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
z-score 标准化方法
tips : 适用于分布没有明显边界的情况,受outlier影响也较小。
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
x∗=x−μσ
其中,μ表示所有样本数据的均值,σ表示所有样本的标准差。
import numpy as np
def z_score(x):
x_mean=np.mean(x)
s2=sum([(i-np.mean(x))*(i-np.mean(x)) for i in x])/len(x)
return [(i-x_mean)/s2 for i in x]#这里感觉是缺少了开根号
x=[1,2,1,4,3,2,5,6,2,7]
print z_score(x)
output:
[-0.57356608478802995, -0.32418952618453861, -0.57356608478802995, 0.17456359102244395, -0.074812967581047343, -0.32418952618453861, 0.42394014962593524, 0.67331670822942646, -0.32418952618453861, 0.92269326683291775]
总结
上面有两种方法,那么到底什么情况使用哪一个呢?
- 在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
- 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
为什么在距离度量计算相似性、PCA中使用第二种方法(Z-score standardization)会更好呢?我们进行了以下的推导分析:
使用第二种方法进行计算,我们先不做方差归一化,只做0均值化,变换后数据为
x′=x−x¯y′=y−y¯
新数据的协方差为:
σ′xy=1n∑i=1n(x′i−x′¯¯¯)(y′i−y′¯¯¯)
由于
x′¯¯¯=0y′¯¯¯=0
因此
σ′xy=1n∑i=1n(x′i)(y′i)
而原始数据的协方差为:
σ′xy=1n∑i=1n(xi−x¯)(yi−y¯) =σ′xy=1n∑i=1n(x′i)(y′i)
因此
σ′xy=σxy
以上说明了将数据变换成都减去均值后,
σ
不变
接着做方差归一化:
x′′=x−x¯σxy′′=y−y¯σy
结果如下:
σ′′xy=1n∑i=1n(x′′i−x′′¯¯¯¯)(y′′i−y′′¯¯¯) =1n∑i=1n(xi−x¯σx)(yi−y¯σy) =1nσxσy∑i=1n(xi−x¯)(yi−y¯)= σxyσxσy
使用第一种方式计算,为了方便分析,我们对x维进行线性函数变换:
x′=cx⋅xy′=cy⋅y
计算协方差
σ′xy=1n∑i=1n(cxxi−cxx¯)(cyyi−cyy¯)=cxcyσxy
可以看到,使用第一种方法(线性变换后),其协方差产生了倍数值的缩放,因此这种方式无法消除量纲对方差、协方差的影响,对PCA分析影响巨大;同时,由于量纲的存在,使用不同的量纲、距离的计算结果会不同。
而在第二种归一化方式中,新的数据由于对方差进行了归一化,这时候每个维度的量纲其实已经等价了,每个维度都服从均值为0、方差1的正态分布,在计算距离的时候,每个维度都是去量纲化的,避免了不同量纲的选取对距离计算产生的巨大影响。
总结来说,在算法、后续计算中涉及距离度量(聚类分析)或者协方差分析(PCA、LDA等)的,同时数据分布可以近似为正态分布,应当使用0均值的归一化方法。其他应用中更具需要选用合适的归一化方法。
























 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









