




提示词、知识库、微调、蒸馏技术介绍
在大模型项目实际落地过程中,经常会遇到预算和配置模型之间的博弈。不仅如此,单单靠大模型本身也不能真正实现行业垂直领域的有效应用。面对大模型各种技术,该如何选取,以及如何在不同场景下做出最佳选择成了每个产品经理头疼的问题。今天就用最接地气的方式来介绍大模型的四张“王牌”技术。一招教你实现行业应用高效落地。
一、大模型的四张王牌技术
如果把大模型的应用比作一场考试。那可能会面对四种截然不同的考场挑战:
在一场普通考试中,你根据考题提干信息,努力回忆自己所学的知识,把核心知识点填到对应问答卡上。
如果这场考试是开卷考,那你就可以带着丰富的课程教材,快速翻阅,完成考试。
再进一步,你为了选修双学位,为了第二学位的专业课考试,精心准备了好几个月,最终在专业课考上如鱼得水。
最后在学术研究课上,你遇到了一些自己无法解决的研究模型,你去请教了教授的经验,把教授的研究方法,转化为自己的学习方法,解决了问题。
四个场景这正好对应了我们大型语言模型实际应用中,增强输出结果准确度的四张“王牌”技术:
提示词工程(prompt):
通过给大模型增加各种约束条件的上下文描述,实现模型精准输出。
知识库技术(RAG):
通过提供本地知识库和互联网知识库,获取最新最专业的答案。
大模型微调(Fine-tuning):
通过提供垂直领域知识库,在应用前进行模型参数调参训练,构建更专业的垂直领域大模型。
模型蒸馏(Model Distillation):
通过教师模型的输出(如概率分布、中间层特征)指导学生模型的学习,从而提升大模型本身的泛化能力。

二、提示词工程
基本原理
提示词工程核心思想是通过结构化文本输入,控制大模型的输出逻辑。通过将提示词作为"上下文",预测最匹配的文本序列。就类似人类对话中的"提问技巧",你想从哪个领域了解关于哪方面的内容,最后以什么样的信息形式传递给你。
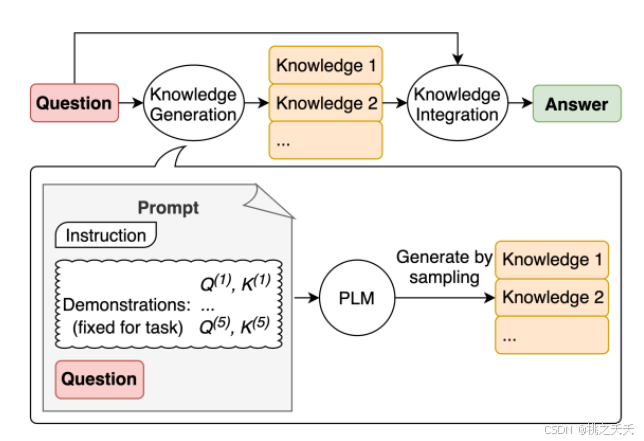
提示词的设计常用技巧:
从简单开始:
设计提示是一个迭代过程,可从简单提示词入手,逐渐添加元素和上下文,也可将大任务分解为简单子任务,避免初始过于复杂。
设置指令:
用命令指示模型执行任务,需大量实验以确定最有效方式,指令可置于提示开头或用分隔符隔开上下文具体且相关效果更好。
具体性:
提示应具体描述任务,提供示例有助于获得期望输出,但要注意长度,避免不必要细节,需通过实验优化。
避免不明确:
提示应具体直接,避免过于复杂或不明确的描述,说“要做什么”比“不要做什么”更有效。
优缺点
| 优点 | 缺点 |
|---|---|
| ✅无需训练模型,零样本学习 | ❌对表述敏感,依赖提问者本身的能力 |
| ✅快速验证想法,低成本迭代 | ❌复杂任务需反复调试提示词,微小描述差别都会导致结果偏差 |
| ✅ |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









