










 利用百度飞桨结合第三代英特尔至强可扩展处理器,实现了发票识别的自动化处理,不仅提高了准确率,还增强了安全性,为企业报销流程带来了革命性的变化。
利用百度飞桨结合第三代英特尔至强可扩展处理器,实现了发票识别的自动化处理,不仅提高了准确率,还增强了安全性,为企业报销流程带来了革命性的变化。
“搬砖了那么多年,最怕的除了每个季度的KPI,就是财务看我贴错发票时的嫌弃眼神。”
身为职场人,每到报销日就开始发愁,各种发票单子铺天盖地堆满桌子,一眼望去全都是钱,但依旧学不会正确的报销姿势。手工录入发票费时费力,而且容易出错,每次财务说重新填,跟小学二年级被老师罚抄作业一个感觉。万一不小心搞丢了一张,更是欲哭无泪。

此情此景,又是深度学习的用武之地了。应用 AI 深度学习技术,百度文字识别(OCR)服务的准确率可以达到 99%[1],财税报销、文档电子化、远程身份认证,诸如此类都不在话下。

如果深度学习应用可以部署在手机上,可想而知应用场景就会更加丰富。然而,想把深度学习应用部署在移动设备上并不容易,毕竟它对数据存储空间和运行性能有要求。此外,深度学习的安全性也是关注焦点,诸如金融领域的应用,机密性是重中之重。
针对上述挑战,百度开源深度学习平台百度飞桨结合第三代英特尔® 至强® 可扩展处理器给出的解决方案,免除了开发者的后顾之忧,让深度学习技术的落地运行更快、更安全。

一、提升性能:先瘦身,再加速
百度飞桨作为中国首个开源开放、技术先进、功能完备的产业级深度学习平台,立足于百度多年的深度学习研究和应用,包含深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件。
想要跑得快,瘦身减负是第一步,要想提升深度学习的性能,也是如此。最新推出的飞桨 2.0,提供了模型量化瘦身和加速的整体方案,由两个环节构成:
1.产出瘦身的量化模型
以 PaddleSlim 深度学习模型压缩工具库,帮助模型瘦身、量化,也就是以低比特数值替换 FP32 数值进行存储和计算,从而实现减小存储空间、加快预测速度、降低能耗。
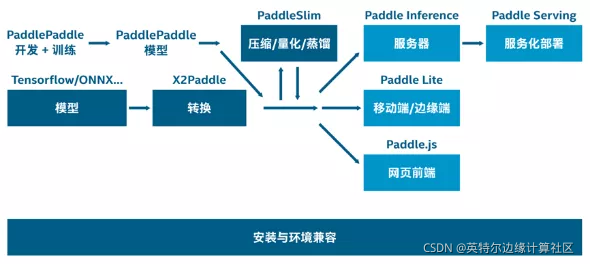
2.部署和加速量化模型
部署和加速百度飞桨量化模型时,关键步骤是结合第三代英特尔® 至强® 可扩展处理器的内置 AI 加速技术——VNNI 可扩展指令集、以及英特尔® oneAPI 工具包。VNNI 可将算力增加 4 倍,将内存要求降至四分之一,从而加快了低数值精度运算的速度,最终加速 AI 和深度学习推理,适合图像分类、语音识别、语音翻译、对象检测等众多情境。而英特尔 oneAPI 工具包作为统一的、简化的编程模型,让开发者无需担心平台兼容性问题。
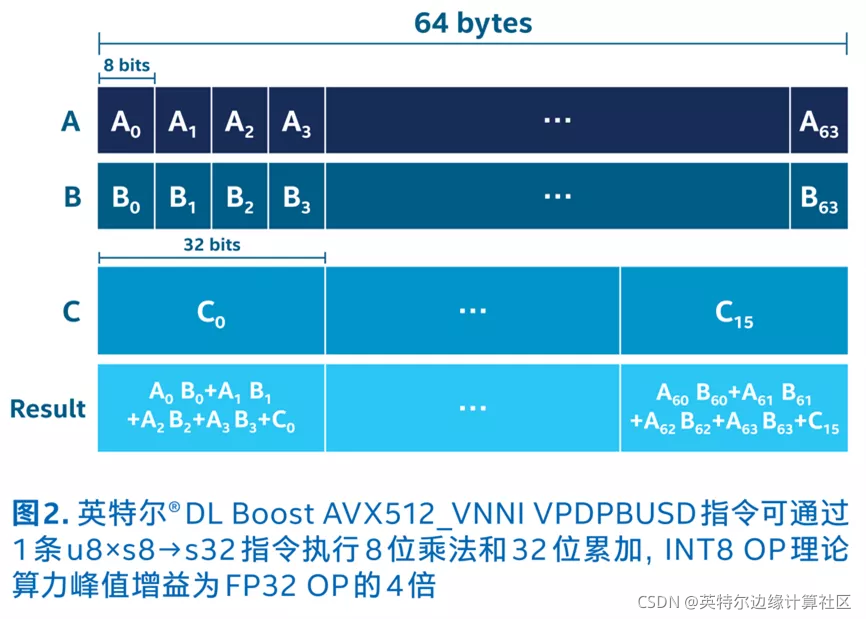
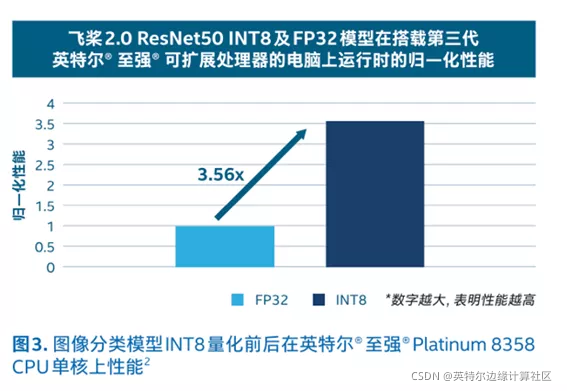
经过第三代英特尔® 至强® 可扩展处理器的量化和加速后,飞桨 2.0 模型的性能提升了 3.56 倍。
二、数据敏感,安全优先
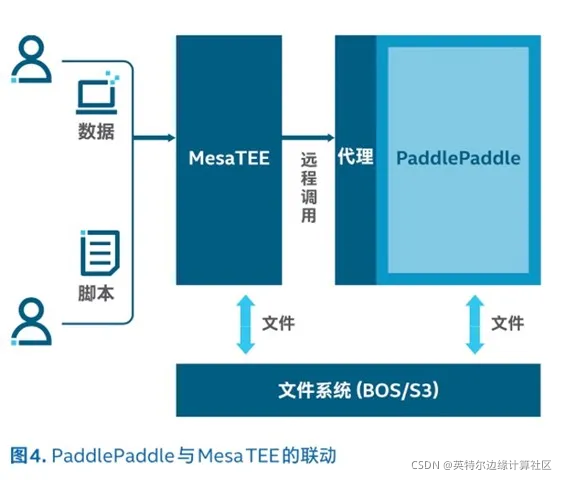
深度学习应用中,常常要汇聚诸多来源的数据,这免不了让企业担心,尤其是敏感的数据更是如此。因此,百度飞桨对接了百度安全计算平台 MesaTEE,即内存安全可信计算环境(Memory-safe Trusted Execution Environments)。
它的安全性来自两大技术:内存安全的 Rust 语言及英特尔® 软件防护扩展(英特尔® Software Guard Extensions,简称英特尔® SGX)。英特尔® SGX 是基于硬件的安全解决方案,它可以绕过操作系统和虚拟机软件层,将敏感的程序代码和数据加载到受 CPU 保护的内存分区 “飞地” ,防止被泄露或更改。借助英特尔® SGX,MesaTEE 得以提供完善的机密深度计算能力,从而保护敏感数据。
与百度飞桨的对接,MesaTEE 起到了任务执行环境的角色。在不改变使用方式的前提下,TEE 中访问的所有数据均为密文。在 TEE 外,无论从磁盘、内存或网络通信上都无法窥探计算内容,从而可以抵抗恶意攻击,确保整体安全性。
三、AI 赋能,无限可能
百度飞桨将深度学习平台与机密计算能力有机结合,将会在众多领域找到立足之地。比如金融行业等众多用户数据将会更安全地汇总在一起,产生多维用户画像,带来更多业务价值。
未来,英特尔也将继续携手百度构建起涵盖产品技术、行业解决方案、产业生态在内的深度合作模式。以技术创新为合作基石,双方不断探索新应用、新突破,进一步提升用户深度学习应用的工作效能,携手企业拥抱多样性计算新时代。



















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









