







在2017年年1月微软在GitHub的上开源了一个新的升压工具LightGBM(Light Gradient Boosting Machine )。它是一种优秀的机器学习算法框架,与XGBoost算法相比,在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。
目录
性能对比
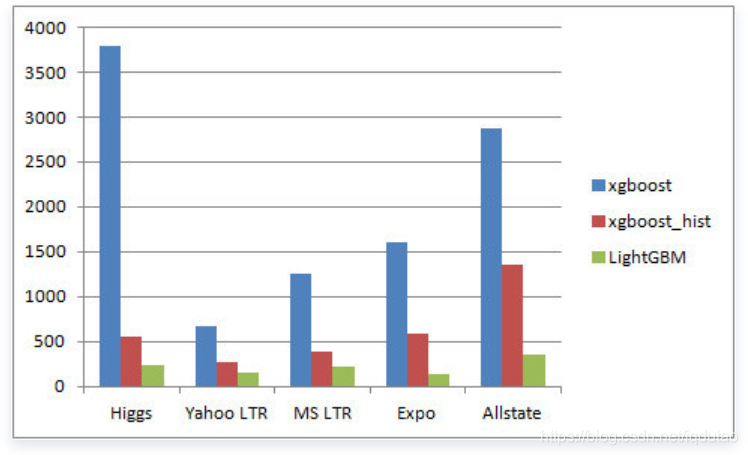
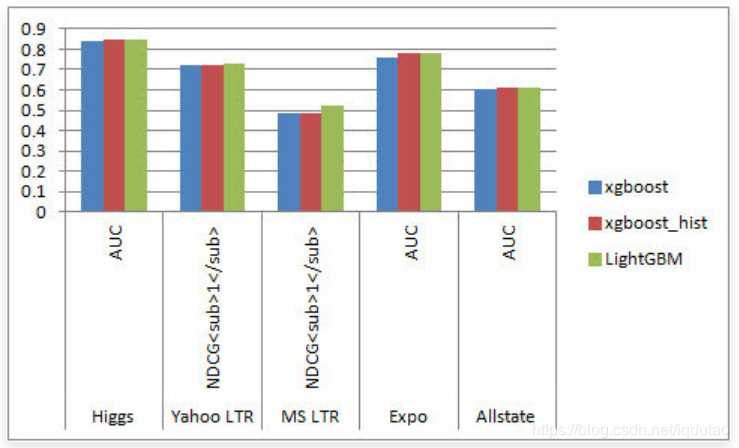
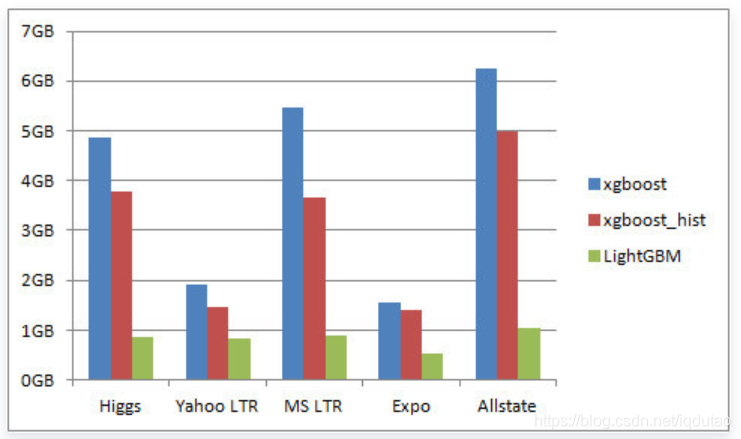
下图是LightGBM在GitHub主页上展示的在五个不同数据集上得到的性能实验数据,比起XGBoost算法,LightGBM算法在准确度一样,但在速度和内存的消耗上有更明显的优势。
耗时比较:
准确率比较:
内存消耗:
GBDT和XGBoost算法的缺点和不足
梯度提升决策树算法的实现原理,它是基于决策树的提升算法,采用前向分布算法,在每次迭代中,通过负梯度拟合残差,从而学习到一颗决策树。在生成决策树的过程中,进行特征选择节点分裂时,需要对特征值进行排序,遍历所有可能的划分点,然后计算信息增益,从而选择出最优的分裂点。每轮迭代都会对整个训练集进行遍历,这样既耗费内存,也非常的耗时。
在这部分比较常用的优化算法有预排序,就是对所有特征值优先排序,计算每个划分点的增益值,并且保存在内存中。在迭代的过程中通过查表的方式进行选择最优分裂点。XGBoost算法已经提供了这种方式的优化,然而它在面对海量数据和特征维度很高的数据集时,算法的效率和扩展性很难让人满意。
如果要对GBDT进行优化,有两个方面:
- 降低训练集的规模,这样可以减少计算量,提高算法的计算效率。
- 降低特征维度,这样的话,可以在选择分裂点的时候减少计算量,提高算法的性能。但是直接减少训练集规模或者降低特征维度,很明显会牺牲模型的精确度。
然而,LightGBM算法正是通过对模型训练时样本点的采样优化和选择分裂点时的特征维度的优化,在不牺牲精度的条件下,提高了训练速度。LightGBM算法是一种改进则是直方图算法,他把连续特征值划分到k个桶中去(连续值分箱),划分点则在这k个点中选取。k<<d,所以在内存消耗和训练速度都更佳。并且在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于决策树本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。LightGBM也是基于直方图的。
LightGBM优化
优化策略:直方图算法(Histogram算法)
LightGBM采用了基于直方图的算法将连续的特征值离散化成了K个整数,构造宽度为K的直方图,遍历训练数据,统计每个离散值在直方图中的累积统计量。在选取特征的分裂点的时候,只需要遍历排序直方图的离散值。使用直方图算法降低了算法的计算代价,XGBoost采用的预排序需要遍历每一个特征值,计算分裂增益,而直方图算法只需要计算K次,提高了寻找分裂点的效率;降低了算法的内存消耗,不需要存储预排序结果,只需要保存特征离散化后的值。
但是特征值被离散化后,找到的并不是精确的分割点,会不会对学习的精度上造成影响呢?在实际的数据集上表明,离散化的分裂点对最终学习的精度影响并不大,甚至会更好一些。因为这里的决策树本身就是弱学习器,采用直方图离散化特征值反而会起到正则化的效果,提高算法的泛化能力。
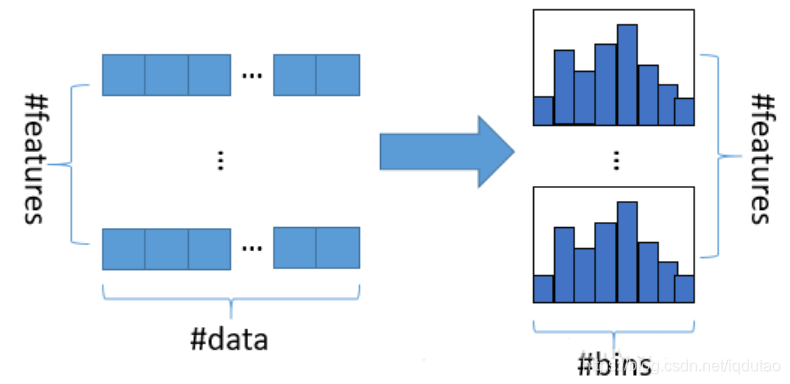
XGBoost预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data * #feature) 优化到O(k* #features)。
LightGBM的直方图做差加速
一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









