






Abstract:
众所周知,Google和Baidu作为最广为人知的搜索引擎,在人们的日常工作生活中,已经变成了不可或缺的一部分,不管我们查找一份专业的技术资料,寻求一次买车建议,抑或是了解某道川菜的做法,我们或多或少都会使用到搜索引擎。很多时候,当我们对一件事情没有答案,或者是没有主意的时候,可能首先想到的就是Google一下,或是咨询度娘,总之搜索引擎已经深入到了我们的工作生活当中,并且扮演着越来越重要的作用。基于此,各大互联网公司都对搜索这块大饼感兴趣。从Google到Baidu,从微软Ping到sougou, 从360到中国搜索。这些形形色色的产品无一不告诉我们,搜索是一个重要的市场,搜索是一块美味的蛋糕。 于过去来说,或许搜索引擎只掌握在这些大公司的手上,中小企业由于数据量较小,对于搜索的需求并不是那么迫切。可是随着互联网,移动互联网的发展,数据有了井喷式的暴涨,各大公司对于搜索的需求逐渐的上升,为了提高用户的体验,让海量的数据产生价值,不管是公司还是技术社区都为了有更好的搜索工具而发力,在此背景下产生了一批优良的闭、开源搜索引擎。
近年来,产生的比较有名的开源搜索引擎就有十几款,下面对这些搜索引擎做一个简单的介绍。
1. Lucence
Lucence是用Java写的,也是Java家族最出名的搜索引擎之一,它提供了查询引擎和索引引擎,没有中文分词引擎,它不支持实时搜索。
2. Sphinx
Sphinx 是一个用C++语言写的开源的搜索引擎,Sphinx在索引上采取的是用空间换取事件的策略,其建立索引要比Lucence快, 支持实时搜索。
3. Nutch
Nutch是一个用Java实现的开源web搜索引擎,包括爬虫、索引引擎、查询引擎、其中Nutch是基于Lucence的,Lucence为Nutch提供文本索引和搜索的API。
4. solr
Solr是一个用java开发的独立的企业级搜索应用服务器,它提供了类似于Web-service的API接口,它是基于Lucece的全文搜索服务器,也算是Lucence的一个变种,很多一线互联网公司都在用Solr,是比较成熟的解决方案。
5. Elasticsearch
Elascticsearch是一个采用java语言开发的,基于Lucence构造的开源、分布式的搜索引擎,设计用于云计算中,能够达到实时搜索,稳定性可靠,数据模型是json。
在以上提高的几种搜索引擎中,目前最出名的,被广泛使用的要数solr跟elasticsearch,而本文的主角就是其中之一的Elasticsearch,本文将从elasticsearch安装入门开始,让大家逐渐熟悉elasticsearch,熟悉其特性、使用场景,以及一些高级用法。
Elasticsearch 是一个现代化的、高速的、分布式的、可扩展的、 实时搜索与数据的开源分析引擎。它能够从项目已开始就赋予你的数据以搜索、分析和探索的能力,这是通常没有预料到的。它的存在还是因为原始数据如果只是躺在磁盘里面就根本毫无用处。
无论你是需要全文搜索,还是结构化数据的实时统计,Elasticsearch都能过满足你,当然Elasticsearch不仅仅只是全文搜索,它还包括结构化搜索、数据分析、复杂语言处理、地理位置和对象间关联关系等, 此外我们也可利用数据建模来充分利用Elasticsearch的水平伸缩性。
前面提到,Elasticsearch是一个开源的搜索引擎,建立在一个全文搜索引擎库Apache Lucene基础之上,Lucene可以说是当先最先进、高性能、全功能的搜索引擎库--无论是开源还是私有。但是Lucene仅仅是一个库,为了更充分发挥其功能,你需要使用Java并将Lucene直接继承到应用程序中。更糟糕的是,其非常复杂,很难理解其工作原理。Elasticsearch也是用java编写,它的内部使用lucene做索引与搜索,但是它的目的是使全文检索变得简单,通过隐藏Lucene的复杂行,取而代之的提供一套简单一致的restful api。然而elasticsearch不仅仅是Lucene,并且也不仅仅只是一个全文搜索引擎。
- 1. 一个分布式的实时文档存储,每个字段都可以被索引与搜索
- 2. 一个分布式实时分析搜索引擎
- 3. 能够胜任上百个服务节点的拓展,并支持PB级别的结构化和非结构化数据。
Elasticsearch将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的restful api进行通信。鉴于我们紧紧是要了解ElasticSearch的特性,我们并没有特别大的数据量,所以在这里我们采用更加简单的方式,利用docker来练习使用elasticsearch。
一、 安装
编写如下的docker-compose.yaml文件
docker-compose.yaml
-------------------------
version: "2"
services:
elasticsearch:
image: elasticsearch
ports:
- "9200:9200"
启动 : dicker-compose up -d
中文分词安装
进入docker
docker exec -it elasticsearch_1 bash 执行如下命令。
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.6.3/elasticsearch-analysis-ik-5.6.3.zip
配置完成之后重启
docker-compose restart OK 截止目前,我们安装算是已经完成了,接下来,由于Elasticsearch是基于restfulAPI的访问,所以我们可以做两手准备,这里推荐使用Sense这个chrome插,通过此链接下载并加入到chrome拓展工具即可使用。 打开浏览器,显示如下。
Sense-chrome插件
Eleasticsearch的几个基本概念以及与传统关系数据库的对比:
- Elasticsearch是一种面向文档的数据库,所以跟传统的关系型数据库,如mysql相比有以下的不同。在elasticsearch 中文档归属于一种类型(type) 而这些类型存在于索引(index)中:
ReleationalDB -> Database ->Table -> Row -> Col
Elasticsearch -> Indices -> Types -> Document -> Field首先让我们考虑以下一个简单的业务需求:
在magicloud这个公司,总共有三个员工。其名字分别为:陈发强,陈真强,斯文。在员工信息统计中我们需要将此三人的以下几个信息记录在员工信息库里面。分别为: 姓名(name), 年龄(age), 自我介绍(about), 兴趣(insterests)所以我们需要一个叫magicloud的Index (库)employee的Type(表) document id为1 字段分别为name、age、about、interests。因此我们需要写入以下几行数据。
PUT /magicloud/employee/1
{
"name": "陈发强",
"age": 24,
"about": "我爱打游戏",
"interests": ["打游戏", "写代码", "吹逼"]
}
PUT /magicloud/employee/2
{
"name": "陈真强",
"age": "25",
"about": "我爱修仙",
"interests": ["修仙", "练武", "挑战"]
}
PUT /magicloud/employee/3
{
"name": "斯文",
"age": 32,
"about": "我爱健身",
"interests": ["跑步", "拳击", "训练"]
}正如我们前面介绍过的一样,我们将此三行数据通过chrome-sense的插件在浏览器里面写入到我们的elasticsearch当中。
如图所示:
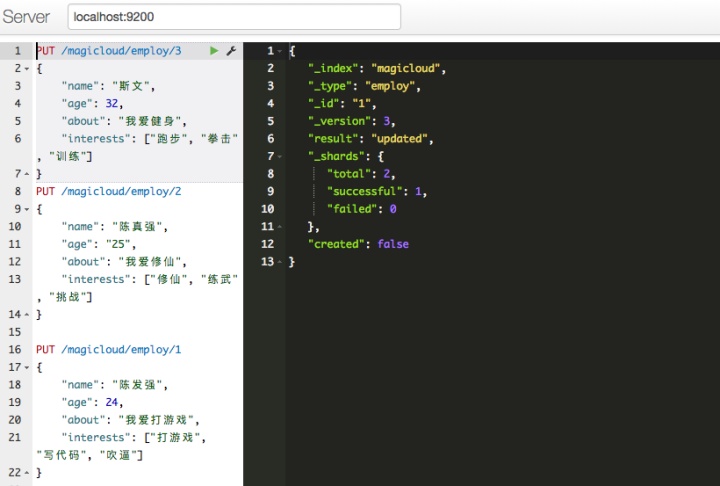
Ok,有了以上三条数据,我们就可以对其进行查询操作。首先我们精确查询第一条记录, 查询语句以及结果如下。
GET /magicloud/employ/1
结果:
{
"_index": "magicloud",
"_type": "employ",
"_id": "1",
"_version": 3,
"found": true,
"_source": {
"name": "陈发强",
"age": 24,
"about": "我爱打游戏",
"interests": [
"打游戏",
"写代码",
"吹逼"
]
}
}接下来我们介绍DSL查询(结构体查询) 在elasticsearch中,如果我们想用更丰富的手机号码购买查询方式,推荐使用的查询方式是DSL查询,在使用DSL查询的时候,我们都是基于restfullAPI的形式,在这里使用GET或者POST都可以达到一样的目地。
接下来我们再创建一个Type 名字叫department, 并插入一条记录。
PUT /magicloud/department/1
{
"name": "技术部",
"about": "公司的技术部门,负责整个公司技术相关工作",
"counts": 3,
"members": ["陈发强", "斯文", "陈真强"]
}
{
"_index": "magicloud",
"_type": "department",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed":
},
"created": false
}查询所有的employ与department的数据:
使用DSL查询我们所有的文档:
GET /magicloud/department,employ/_search
{
"query": {
"match_all": {}
}
}
结果:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": ,
"failed":
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "magicloud",
"_type": "employ",
"_id": "2",
"_score": 1,
"_source": {
"name": "陈真强",
"age": "25",
"about": "我爱修仙",
"interests": [
"修仙",
"练武",
"挑战"
]
}
},
{
"_index": "magicloud",
"_type": "employ",
"_id": "1",
"_score": 1,
"_source": {
"name": "陈发强",
"age": 24,
"about": "我爱打游戏",
"interests": [
"打游戏",
"写代码",
"吹逼"
]
}
},
{
"_index": "magicloud",
"_type": "department",
"_id": "1",
"_score": 1,
"_source": {
"name": "技术部",
"about": "公司的技术部门,负责整个公司技术相关工作",
"counts": 3,
"members": [
"陈发强",
"斯文",
"陈真强"
]
}
},
{
"_index": "magicloud",
"_type": "employ",
"_id": "3",
"_score": 1,
"_source": {
"name": "斯文",
"age": 32,
"about": "我爱健身",
"interests": [
"跑步",
"拳击",
"训练"
]
}
}
]
}
}
可以看到,我们跨Type(表)查询到了所有的信息,当然在这里还可以进行跨库的查询。 接下来我们介绍一下较为高级的过滤查询。
过滤查询:
GET /magicloud/employ/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"from": 24,
"to": 25
}
}
},
"must": [
{"match": {
"about": "我"
}}
]
}
}
}
查询结果
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": ,
"failed":
},
"hits": {
"total": 2,
"max_score": 0.8367443,
"hits": [
{
"_index": "magicloud",
"_type": "employ",
"_id": "1",
"_score": 0.8367443,
"_source": {
"name": "陈发强",
"age": 24,
"about": "我爱打游戏",
"interests": [
"打游戏",
"写代码",
"吹逼"
]
}
},
{
"_index": "magicloud",
"_type": "employ",
"_id": "2",
"_score": 0.2876821,
"_source": {
"name": "陈真强",
"age": "25",
"about": "我爱修仙",
"interests": [
"修仙",
"练武",
"挑战"
]
}
}
]
}
}在此查询中,我们先根据年龄跟name过滤了年龄为24-25 about匹配"修仙"的记录。
elasticsearch默认按照相关性得分(_score)排序,即每个文档跟查询的匹配程度, 这跟传统的数据库有所区别,传统数据库中要么匹配,要么不匹配。
聚合:
elasticsearch有一个功能叫聚合(aggregations), 允许我们基于数据生成一些精细的分析结果。聚合与SQL中的Group By类似,但更强大。
在聚合之前我们首先要指定fielddata
PUT /magicloud/_mapping/employ
{
"properties": {
"interests": {
"type": "text",
"fielddata": true
}
}
}根据兴趣进行聚合,然后对聚合后的数据求兴趣相同的人的年龄平均值。
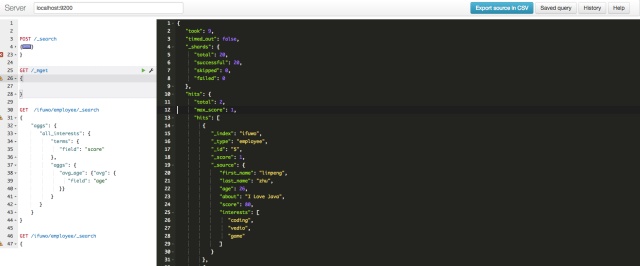
GET /magicloud/employ/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}到此,elasticsearch常用功能基本就告一段落了。后面还有很多高级的特性。
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作。
- 分配到不同的容器或者分片中,文档可以储存在一个或多个节点中。
- 按照集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡。
- 复制每个分片以支持数据的冗余,从而防止硬件故障导致的数据丢失。
- 将集群中任一节点的请求路由到存有相关数据的节点。
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复。
Elasticsearch有着合理的默认设置,在无需干预的情况下通常能够工作的很好。当追求毫秒级的性能提升时,一些高级的用法就显得比较重要。















 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









