






1. mget和size
es默认每次查询结果是返回十条数据,也可以通过size的方式设置更多条
{
"query": {
"bool": {
"must": [
{
"match": {
"entname": "华为技术华为技术有限公司"
}
}
]
}
},
"size":20
}当size设置大于10000时查询会返回异常:
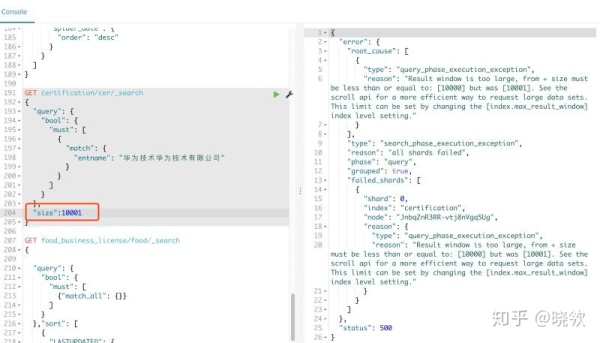
错误提示:"reason": "Result window is too large, from + size must be less than or equal to: [10000] 不过这个也可以在es配置里修改的,但是不建议修改该选项。
mget一般在多个查询条件对应多个或单个查询结果时可以选择用它,如: 查询id为1和2的数据
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 2
}
]
}java里使用MultiGetRequest来设置查询参数, 顺道说一句,es查询也是可以指定集合范围查询的如:java里 QueryBuilders.termsQuery("showtemp", "1","2","3"...))的构造方法. 对应的查询语句:
{
"query": {
"bool": {
"must": [
{
"terms": {
"showTemp": [
"1",
"2"
]
}
}
]
}
}
}bulk API
java里使用BulkRequestBuilder构造,使用方式一看就会了,这是针对构造多个查询条件的。当然也可以做批量插入操作。
scrollId
上面说的bulk和mget只是针对查询条件的批量,size是针对单次返回结果的扩大,如果想要真正的把所有买二手结果查 询出来,那么可以选择scollid游标查询。 java示例:
/**
* 按时间范围批量游标查询
*
* @param index
* @param type
* @param dateKey es存储更新时间字段名
* @param startDate 起始时间
* @param endDate 结束时间
* @return
*/
public List<Map<String, Object>> searchByDate(String index, String type, String dateKey, String startDate, String endDate) throws IOException {
List<Map<String, Object>> list = new ArrayList<>();
RestHighLevelClient client = EsService.getClient();
final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.scroll(scroll);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(2000);
searchSourceBuilder.query(QueryBuilders.rangeQuery(dateKey).gte(startDate).lt(endDate));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
String scrollId = searchResponse.getScrollId();
SearchHit[] searchHits = searchResponse.getHits().getHits();
while (searchHits != null && searchHits.length > 0) {
for (int i = 0; i < searchHits.length; i++) {
list.add(searchHits[i].getSourceAsMap());
}
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = client.searchScroll(scrollRequest);
scrollId = searchResponse.getScrollId();
searchHits = searchResponse.getHits().getHits();
}
//一旦滚动完成,清除滚动上下文
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest);
boolean succeeded = clearScrollResponse.isSucceeded();
return list;
}快照
假如是需要对es数据做备份,那么可选择的方式有快照,如果是对某些index设置自动快照的话就需要重启es才能生效。
reindex
同样reindex也可以用来做es数据备份和迁移,不过这是es到es之间的迁移,如果需要备份到文件的话可以选择以下的方案。
esdump
安装
npm install elasticdump安装方式有很多种,甚至支持docker安装运行,具体想用哪种方案可以根据自己情况来选择,使用方式如下:
'#拷贝analyzer分词
elasticdump \
--input=http://ip1:9200/my_index \
--output=http://ip2:9200/my_index \
--type=analyzer
'#拷贝映射
elasticdump \
--input=http://ip1.com:9200/my_index \
--output=http://ip2:9200/my_index \
--type=mapping
'#拷贝数据
elasticdump \
--input=http://ip1:9200/my_index \
--output=http://ip2:9200/my_index \
--type=data
上面是es到es,--out同样可以指向文件。
logstash
知道ELK的人自然也知道logstash是用来干什么的了,一般用来把日志文件输出到es,方便统计查看,反过来行不行呢,当然也是没问题的,同样可以把es的数据导出到文件,甚至其他数据库。
logstash安装比较简单就不说了,下面举一个使用logstash把es数据导出到hdfs的例子:
input {
elasticsearch {
hosts => "es:9200"
index => "food_business_license"
size => 10000
query => '
{
"query": {
"bool": {
"must": [
{
"term": {
"PROVINCE": {
"value": "西藏"
}
}
}
]
}
}
}
'
scroll => "5m"
docinfo => true
}
}
filter {
if![hh]{
mutate {
add_field => {
"hh" => "哈哈"
}
}
}
}
output {
webhdfs {
host => "ip"
port => "端口"
user => spark
flush_size => 5000
idle_flush_time => 10
path => "/tmp/%{+YYYY}-%{+MM}-%{+dd}/food-%{+YYYY}%{+MM}%{+dd}.csv"
codec => line {
format => "%{LEGAL_PERSON}\u0001%{TAXPAYER_NAME}\u0001%{hh}\u0001%{LEGAL_PERSON}"
}
}
}input里是输入的数据,从es读取,所以写的连接es,filter中是处理一些数据格式,字段转换的问题,output里配置的是输出位置,以及输出格式。
esdump和logstash批量导出原理也是基于scroll查询的,我测试了一下感觉还是使用logstash更快一些。















 5257
5257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









