







0. 前言
- 相关资料:
- 论文基本信息
- 领域:HOI
- 作者单位:FAIR
- 发表时间:CVPR 2018
- 一句话总结:扩展 Fast R-CNN,使用多任务训练实现HOI中 human/verb/object 三元组预测
1. 要解决什么问题
- 之前的主要工作都集中在单个人/物体的识别上,然而在现实世界中,人与物体之间是存在相互关系的。
2. 用了什么方法
- 人物交互可以抽象为形如
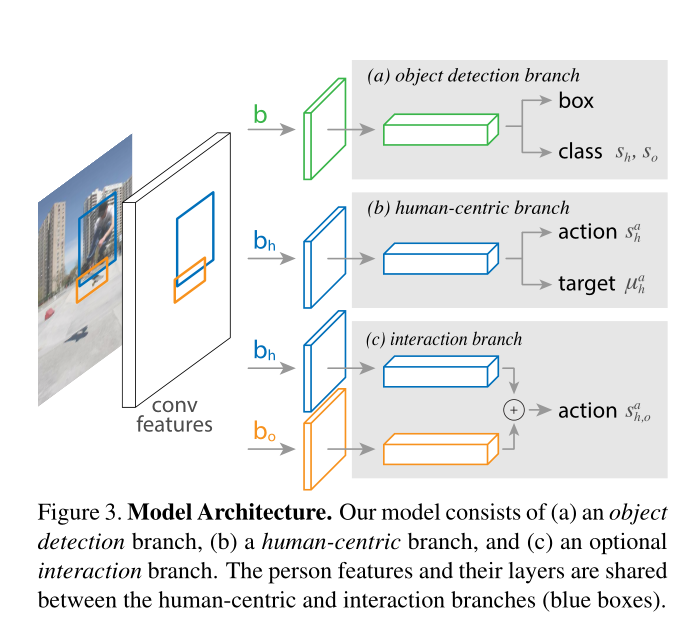
<human, verb, object>的三元组。 - 下图中的 a/b/c 就是本文模型的基本思路
- a图:实现基本的目标检测
- b图:根据前一步目标检测结果(主要就是人),预测可能交互的物体位置,并预测动作(图中没有展示)
- c图:根据a图中物品目标检测结果,以及b图中可能的位置,构建
<human, verb, object>三元组

- 实现了基于 Fast-RCNN 架构的人物交互模型
- 总目标就是预测
<human ,verb, object>三元组 - 第一步,实现目标检测,即 object detection 分支。
- 下图中的 (a),绿色分支。
- 注意,后面几个 b h , b o b_h, b_o bh,bo 其实都是绿色分支的预测结果,分别代表人roi和物体roi。
- 第二步,实现行为以及交互物体位置预测,即 human-centric 分支
- 下图中的 (b)
- 行为预测:这部分没啥好说的,就是一个分类网络(若干FC)。需要注意的是,由于人可能同时存在多个动作(比如坐+喝水),所以这一部分最后使用 sigmoid 并通过目标分类的方法进行训练。
- 目标位置预测(Target Localization):根据任务的外观信息(即ROI Pooling结果),预测交互物体的位置。直接预测准确位置比较困难,所以本模型预测的是
density over possible locations,后面单独介绍。 - 注意,通过 (a) 和 (b) 就已经可以预测 h/v/o 三元组了。
- 交互分支(Interaction branch):可选项。如果没有这个分支,那么actionx信息就是纯靠 human appearance 预测的。但从直觉上看,human-object相互作用才能得到action信息,所以添加了这个分支作为验证。
- 总目标就是预测
- Target Localization
- 本论文的核心,性能提升很大程度上依赖于这一部分。
- 从上图中可以看到,target localization属于 (b) human-centric branch,预测结果是 μ h a \mu_h^a μha,也就是说,对于每个人、每个不同的动作都有不同的预测结果。
- μ h a \mu_h^a μha 是一个思维向量,表示交互物体与当前人的相对位置(相对位置更好计算损失函数,就类似于检测预测的bbox是相对位置而不是绝对像素位置)。
- 通过
μ
h
a
\mu_h^a
μha 获取的位置是一个高斯分布,即
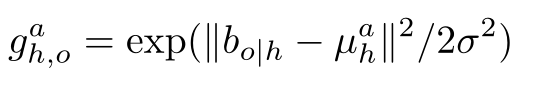
- 其中
b
o
∣
h
b_{o|h}
bo∣h 是物体与人之间的相对位置gt,计算公式就是
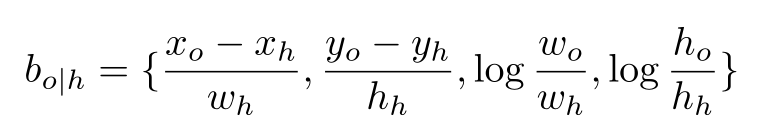
- 目标函数就是 b o ∣ h b_{o|h} bo∣h 与 μ h a \mu_h^a μha 之间的L1 Loss,公式中的 σ \sigma σ 是超参数
- 模型整体目标函数
- 每个
<human, verb, object>三元组的得分就是下图中的 S h , o a S_{h,o}^a Sh,oa - 指的一提的是, S h , o a S_{h,o}^a Sh,oa 这个符号就已经表明,human/object/action 都已经指定了。
- 三元组得分由四部分组成
- s h , s o s_h, s_o sh,so 就是当前人和当前物体的分类得分,即object detection branch的预测结果。
- s h a s_h^a sha 就是当前人的当前行为得分,即human-centric branch中的action部分
- g h , o a g_{h,o}^a gh,oa 就是位置信息
- 每个
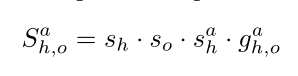
- 训练:就是各个branch的loss叠加
- inference
- 目标:寻找
S
h
,
0
a
S_{h,0}^a
Sh,0a 最大的
<human, verb, object>组合 - 朴素算法:寻找每一对 human/object pair
- 提出 cascade 方法:先获取 human/action pair(时间复杂度 O(n)),再寻找令每一个 human/action pair 的
S
h
,
o
a
S_{h,o}^a
Sh,oa 最大的的 物体。
- 虽然最后一步一般是 O(n^2) 的时间复杂度,但实际使用中一般会节约大量时间。
- 目标:寻找
S
h
,
0
a
S_{h,0}^a
Sh,0a 最大的
3. 效果如何
-
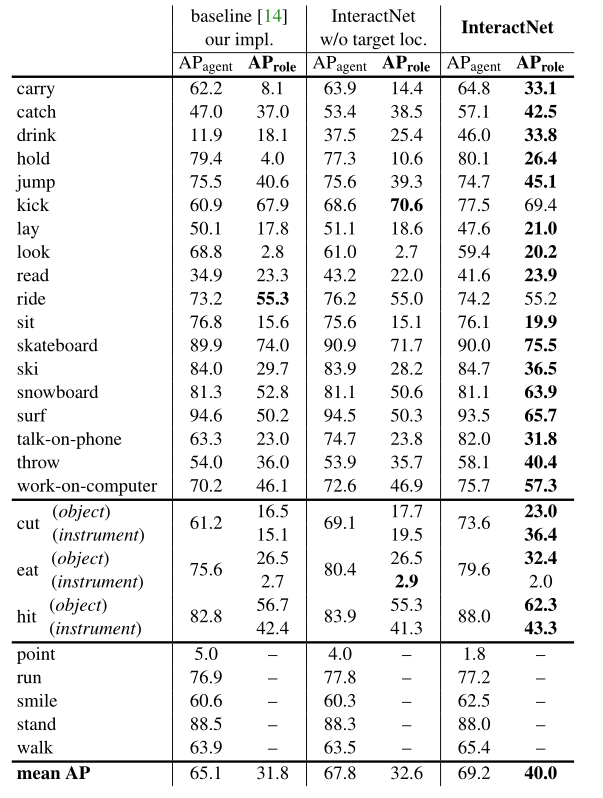
HOI 性能指标解析
- 针对
<human, verb, object>三元组,定义了 A P r o l e AP_{role} AProle - TP 的定义是:
- 人物的预测bbox与gtbbox之间IOU大于0.5
- 物体的预测bbox与gtbbox之间IOU大于0.5
- 相互之间的行为类型匹配
- 针对
-
从预测结果中可以看到,target localization 起到了决定性的作用
4. 还存在什么问题&可借鉴之处
- 没开源,本来想研究下源码。
- 这是 HOI 领域引用最高的几篇之一吧,听说思路在后续论文中经常用到。














 4545
4545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









