







Mysql中的order by是高频操作,并且对性能影响非常大,所以如果想要对排序有比较深的认知,并且对关键耗时排序进行优化,那么首先需要Mysql内部对于排序操作的实现原理。 在此之前需要对排序算法有比较深入的理解,排序算法种类非常多,但是项目工程中常用的是时间复杂度为O(N*logN)的快速排序和归并排序,Mysql中也使用到了这两种排序方式,项目详解。可以参考:排序算法 - 时间复杂度O(N*logN)的归并、快速排序算法。如果想要对排序有个整体的认识,自己将排序算法按照时间复杂度和场景分类,可以参考:排序算法。
只要有Sql中出现了order by字样,Mysql就一定要执行排序操作吗?答案是不一定的。怎么判断有没有真正的执行排序,查看执行计划,如果Extra 字段显示 Using filesort表示执行了真正的排序动作,并不表示这里就真的使用了文件排序【filesort字样我也是误会了好几年】。如下图:

下面先分析需要排序的情况,整体流程图如下:
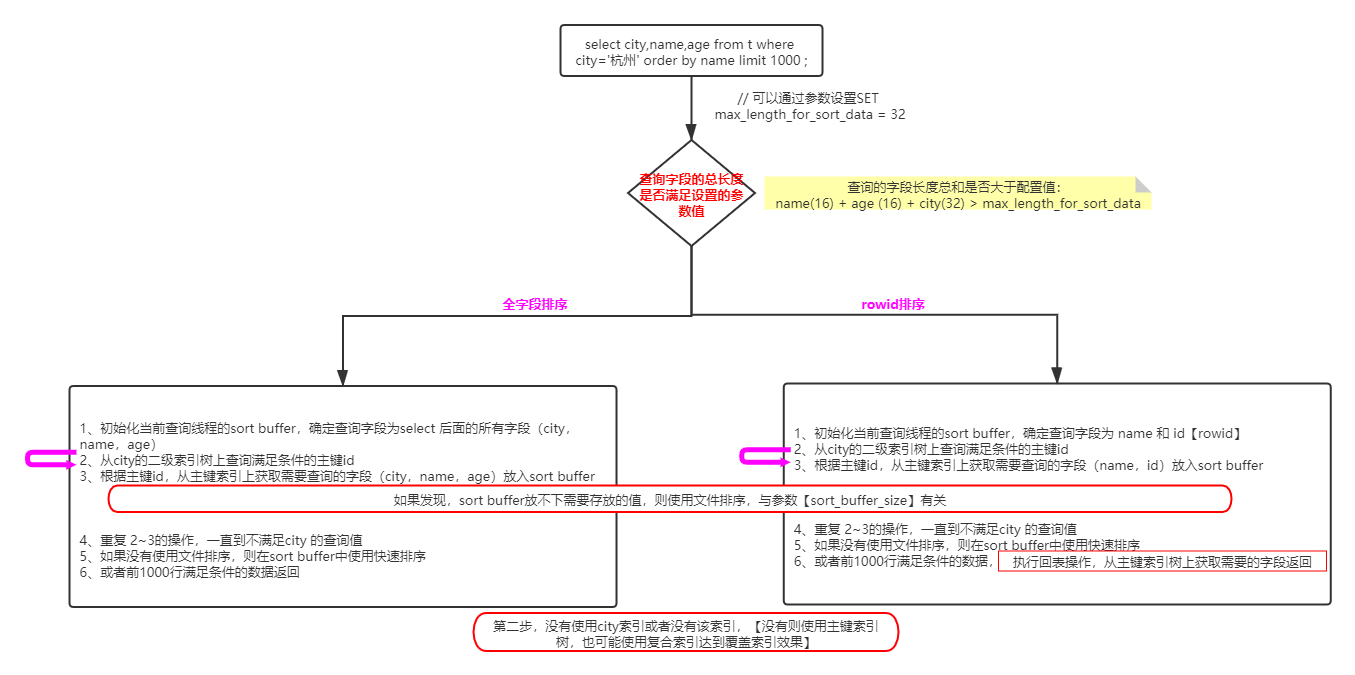
上面的流程图是Mysql内部的排序逻辑,整体上大致可以分为两条主线(具体细化步骤见上图):
1、按照 查询字段字段的总长度是否大于 max_length_for_sort_data(默认值为1024,可以设置最小值:4,最大值:8388608),小于该值就带着所有字段排序并且直接返回想要查询的字段;否则只有排序字段和rowid排序,排完序(如果有过滤条件再过滤完)后面再执行回表操作获取想要字段返回。对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
2、查询时如果排序的数据量小于 sort_buffer_size大小,就可以直接在内存中使用快速排序进行排序。而排序的数据量取决于上面的分类情况,是查询的全字段带进sort buffer还是只带必要的字段再回表操作。 如果sort buffer不能完成排序,则需要使用文件排序。需要分批次在sort buffer中完成排序成一个一个的有序小文件,使用归并排序将多个排序好的有序小文件合并成一个有序大文件。
怎么判断是否真的执行了文件排序,上面说了filesort字样只能表示真正的执行了排序操作,即上图中的流程。通过设置 optimizer_trace查看具体的统计信息,number_of_tmp_files的值如果是0表示没有使用文件排序,全部在 sort_buffer中完成排序操作;否则表示使用了文件排序的小文件个数。
/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
select @b-@a;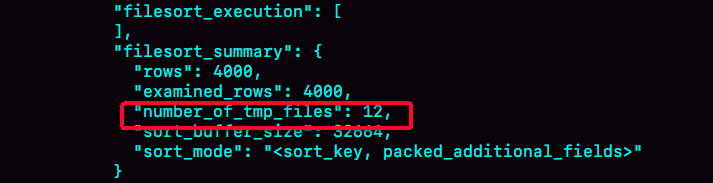
上面分析执行计划中带有Extra字段中带有 Using filesort字样,表示走了排序操作。我们可以利用B+树索引支持有序的特点,将order by优化为不真正执行排序,但是按照是否带有where 语句进行分析:
不带where的情况:如 select ... from t order by key1 limit n
此时需要创建一个key1的索引即可, 但是如果执行 order by key1,key2,则需要建立一个 key1、key2的复合索引。
带【等值】where的情况:select ... from t where key = 'XX' order by key2
此时需要现在执行where操作过滤条件,在按照 key2字段进行排序。此时只有 key2字段建立索引,也是需要执行排序操作的,正确的做法是需要建立 where 字段 + order by字段的复合索引,此处需要建立一个 key、key2的复合索引。
当执行计划中,Extra 字段中不是 Using filesort,而是Using index condition,则表示没有真正的执行排序,而是完全利用了B+树有序的特点,如下:

不论上面的那种情况,如果select 的字段也在复合索引的字段中,即走覆盖索引,就不用执行回表操作,性能会更高。只是此时需要权衡业务需要显示的字段,已经维护字段比较多的复合索引的代价。执行计划中,Extra 的字样为:【Using where】 Using index,如下图:















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









