







目录
(5) 数据访问权限的核对(data dict cache)
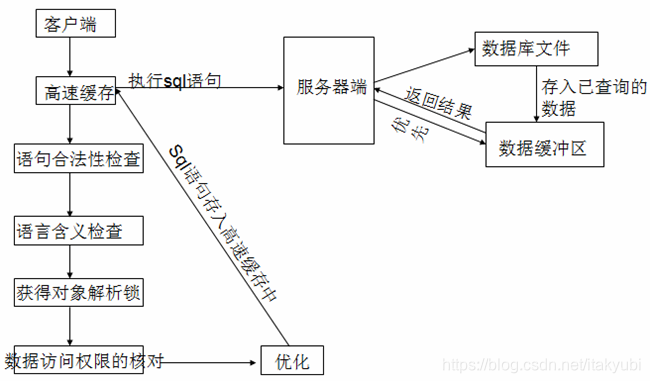
1、客户端把语句发给服务器执行
当我们在客户端执行 select 语句时,客户端会把这条 SQL 语句发送给服务器端,让服务器端的进程来处理这语句。也就是说,Oracle 客户端是不会做任何的操作,他的主要任务就是把客户端产生的一些 SQL 语句发送给服务器端。虽然在客户端也有一个数据库进程,但是这个进程的作用跟服务器上的进程作用是不相同的。服务器上的数据库进程才会对SQL 语句进行相关的处理。
不过,有个问题需要说明,就是客户端的进程跟服务器的进程是一一对应的。也就是说,在客户端连接上服务器后,在客户端与服务器端都会形成一个进程,客户端上的我们叫做客户端进程;而服务器上的我们叫做服务器进程。
2、语句解析
当客户端把 SQL 语句传送到服务器后,服务器进程会对该语句进行解析。同理,这个解析的工作,也是在服务器端所进行的。虽然这只是一个解析的动作,但是其会做很多“小动作”。
(1) 查询高速缓存(library cache)
服务器进程在接到客户端传送过来的 SQL 语句时,不会直接去数据库查询。而是会先在数据库的高速缓存中去查找,是否存在相同语句的执行计划。如果在数据高速缓存中,则服务器进程就会直接执行这个 SQL 语句,省去后续的工作。所以采用高速数据缓存的话,可以提高 SQL 语句的查询效率。一方面是从内存中读取数据要比从硬盘中的数据文件中读取数据效率要高,另一方面也是因为这个语句解析的原因。
不过这里要注意一点,这个数据缓存跟有些客户端软件的数据缓存是两码事。有些客户端软件为了提高查询效率,会在应用软件的客户端设置数据缓存。由于这些数据缓存的存在,可以提高客户端应用软件的查询效率。但是若其他人在服务器进行了相关的修改,由于应用软件数据缓存的存在,导致修改的数据不能及时反映到客户端上。从这也可以看出,应用软件的数据缓存跟数据库服务器的高速数据缓存不是一码事。
(2) 语句合法性检查(data dict cache)
当在高速缓存中找不到对应的 SQL 语句时,则服务器进程就会开始检查这条语句的合法性。这里主要是对 SQL 语句的语法进行检查,看看其是否合乎语法规则。如果服务器进程认为这条 SQL 语句不符合语法规则的时候,就会把这个错误信息,反馈给客户端。在这个语法检查的过程中,不会对 SQL 语句中所包含的表名、列名等等进行 SQL 他只是语法上的检查。
(3) 语言含义检查(data dict cache)
若 SQL 语句符合语法上的定义的话,则服务器进程接下去会对语句中的字段、表等内容进行检查。看看这些字段、表是否在数据库中。如果表名与列名不准确的话,则数据库会就会反馈错误信息给客户端。所以有时候我们写 select 语句的时候,若语法与表名或者列名同时写错的话,则系统是先提示说语法错误,等到语法完全正确后,再提示说列名或表名错误。
(4) 获得对象解析锁(control structer)
当语法、语义都正确后,系统就会对我们需要查询的对象加锁。这主要是为了保障数据的一致性,防止我们在查询的过程中,其他用户对这个对象的结构发生改变。
(5) 数据访问权限的核对(data dict cache)
当语法、语义通过检查之后,客户端还不一定能够取得数据。服务器进程还会检查,你所连接的用户是否有这个数据访问的权限。若你连接上服务器的用户不具有数据访问权限的话,则客户端就不能够取得这些数据。有时候我们查询数据的时候,辛辛苦苦地把 SQL 语句写好、编译通过,但是最后系统返回个 “没有权限访问数据”的错误信息,让我们气半死。这在前端应用软件开发调试的过程中,可能会碰到。所以要注意这个问题,数据库服务器进程先检查语法与语义,然后才会检查访问权限。
(6) 确定最佳执行计划
当语句与语法都没有问题,权限也匹配的话,服务器进程还是不会直接对数据库文件进行查询。服务器进程会根据一定的规则,对这条语句进行优化。不过要注意,这个优化是有限的。一般在应用软件开发的过程中,需要对数据库的 sql 语言进行优化,这个优化的作用要大大地大于服务器进程的自我优化。所以一般在应用软件开发的时候,数据库的优化是少不了的。当服务器进程的优化器确定这条查询语句的最佳执行计划后,就会将这条 SQL 语句与执行计划保存到数据高速缓存(library cache)。如此的话,等以后还有这个查询时,就会省略以上的语法、语义与权限检查的步骤,而直接执行 SQL 语句,提高 SQL 语句处理效率。
3、语句执行
语句解析只是对 SQL 语句的语法进行解析,以确保服务器能够知道这条语句到底表达的是什么意思。等到语句解析完成之后,数据库服务器进程才会真正的执行这条 SQL 语句。这个语句执行也分两种情况。
若被选择行所在的数据块已经被读取到数据缓冲区的话,则服务器进程会直接把这个数据传递给客户端,而不是从数据库文件中去查询数据。
若数据不在缓冲区中,则服务器进程将从数据库文件中查询相关数据,并把这些数据放入到数据缓冲区中(buffer cache)。
4、提取数据
当语句执行完成之后,查询到的数据还是在服务器进程中,还没有被传送到客户端的用户进程。所以在服务器端的进程中,有一个专门负责数据提取的一段代码。他的作用就是把查询到的数据结果返回给用户端进程,从而完成整个查询动作。从这整个查询处理过程中,我们在数据库开发或者应用软件开发过程中,需要注意以下几点:
一是要了解数据库缓存跟应用软件缓存是两码事情。数据库缓存只有在数据库服务器端才存在,在客户端是不存在的。只有如此,才能够保证数据库缓存中的内容跟数据库文件的内容一致。才能够根据相关的规则,防止数据脏读、错读的发生。而应用软件所涉及的数据缓存,由于跟数据库缓存不是一码事情,所以应用软件的数据缓存虽然可以提高数据的查询效率,但是却打破了数据一致性的要求,有时候会发生脏读、错读等情况的发生。所以有时候在应用软件上有专门一个功能,用来在必要的时候清除数据缓存。不过,这个数据缓存的清除,也只是清除本机上的数据缓存,或者说只是清除这个应用程序的数据缓存,而不会清除数据库的数据缓存。
二是数据库是把数据查询权限的审查放在语法语义的后面进行检查的。所以有时会若光用数据库的权限控制原则,可能还不能满足应用软件权限控制的需要。此时,就需要应用软件的前台设置,实现权限管理的要求。而且有时应用数据库的权限管理,也有点显得繁琐,会增加服务器处理的工作量。因此,对于记录、字段等的查询权限控制,大部分程序涉及人员喜欢在应用程序中实现,而不是在数据库上实现。














 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









