







某些爬虫程序需要运行很长时间才能将数据爬完,爬取太快呢又会被网站给封禁。你又不想一直开着电脑连续开几天,太麻烦。。。
其实有个好方法,你可以把爬虫放在阿里云服务器运行,这样你就不需要管了,但是你如果在Ubuntu或阿里云上直接:
scrapy crawl spider_name 或python run.py的话
当你关闭链接阿里云的xshell时,程序会直接停掉不会继续运行。
今天给大家分享一个在阿里云服务器后台运行你的scrapy爬虫代码的命令,可以使你的爬虫在服务器后台一直运行,关闭连接也没事。
nohup python -u run.py > spider_house.log 2>&1 &
run.py为你自己写的scrapy爬虫的运行文件:
from scrapy.cmdline import execute
execute(['scrapy','crawl','house'])
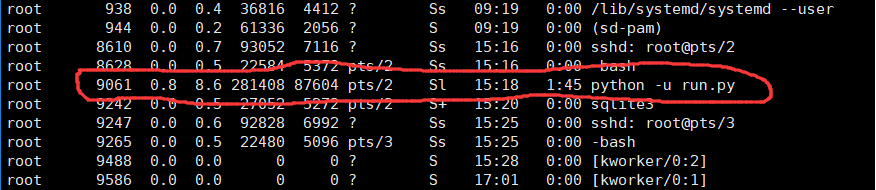
执行完命令后会返回给你一个进程ID,此时你的爬虫就已经在该进程中运行了,你可以用下边命令查看后台该进程:
ps -aux #a:显示所有程序 u:以用户为主的格式来显示 x:显示所有程序,不以终端机来区分
只要找到返回给你的进程pid,说明你的爬虫正在运行。
如下是我的运行进程:














 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









