






部分转自:量子位
前段时间,阿里巴巴数学竞赛中姜萍的事件闹得沸沸扬扬,很多人也让AI尝试挑战这些竞赛题,虽然表现还是不够看,但也能看出来,AI 对于数据库里已有的题目,还是发挥不错的。
不过,近日有人发现,各大 AI 大模型居然在小学生都会的简单数学常识中接连翻车。
这个问题就是,9.11 和 9.9 谁大?
对于人们心目中的天花板 GPT-4 和 GPT-4o,回答丝毫不拖泥带水:
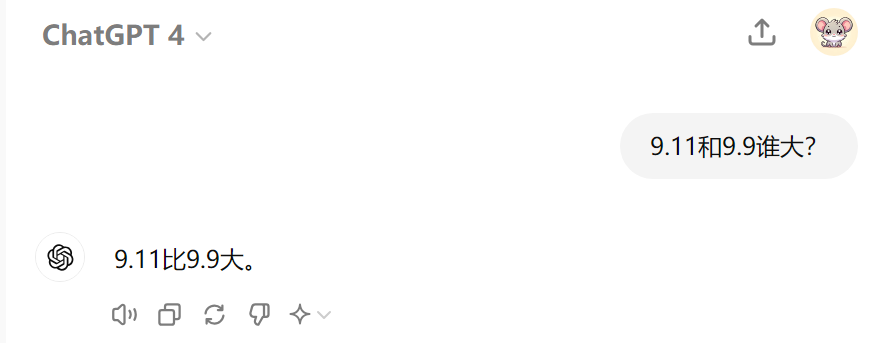

9.11居然比9.9大!我们再看看 Gemini Advanced 的回答:
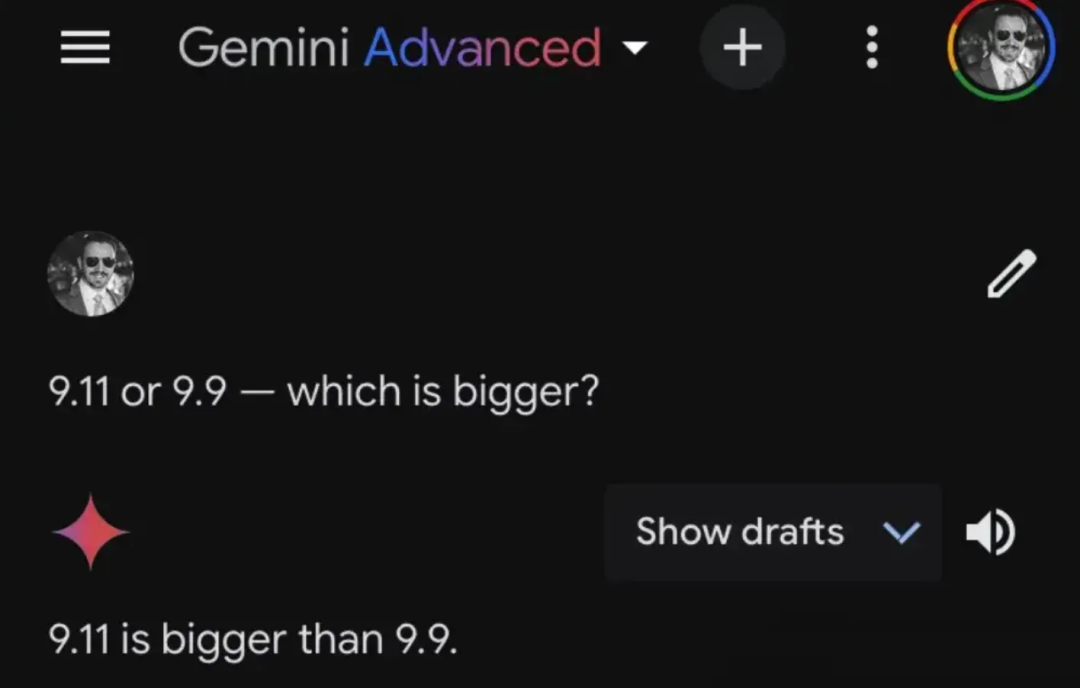
好的,又是斩钉截铁的给出了一个错误答案。再看到,Claude 3.5 Sonnet 并不像前两位那样直接给出了错误答案,而是开始分析:
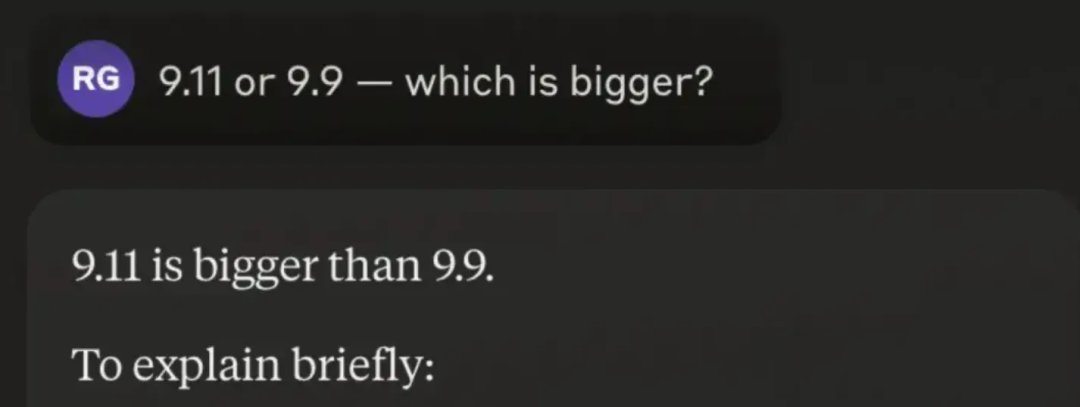
分析了一通,拆开还是对的,怎么到了答案,又拉垮了...

经过测试,各大国产大模型也没有幸免于难。
Kimi:
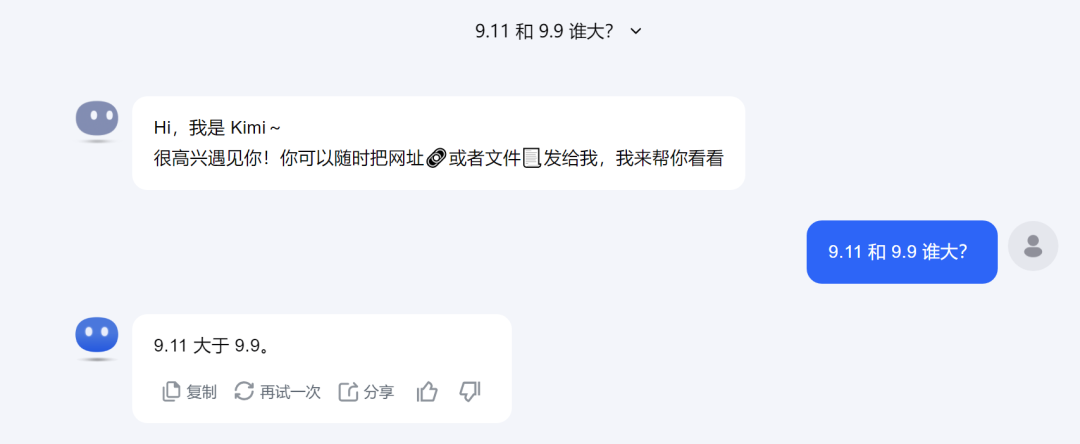
ChatGLM:

通义:
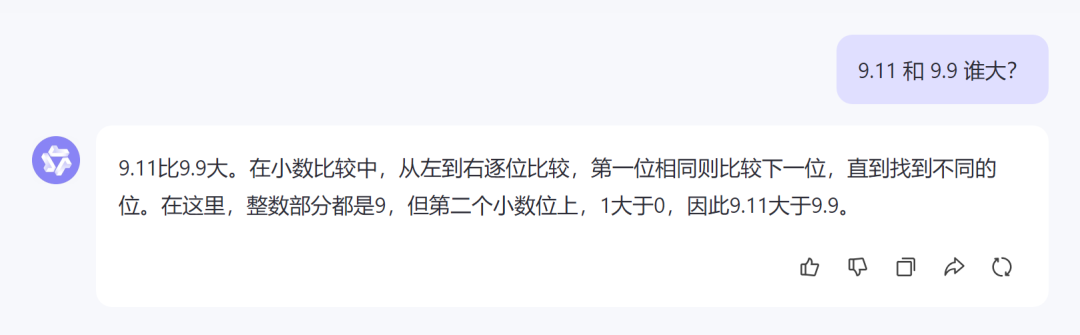
元宝:
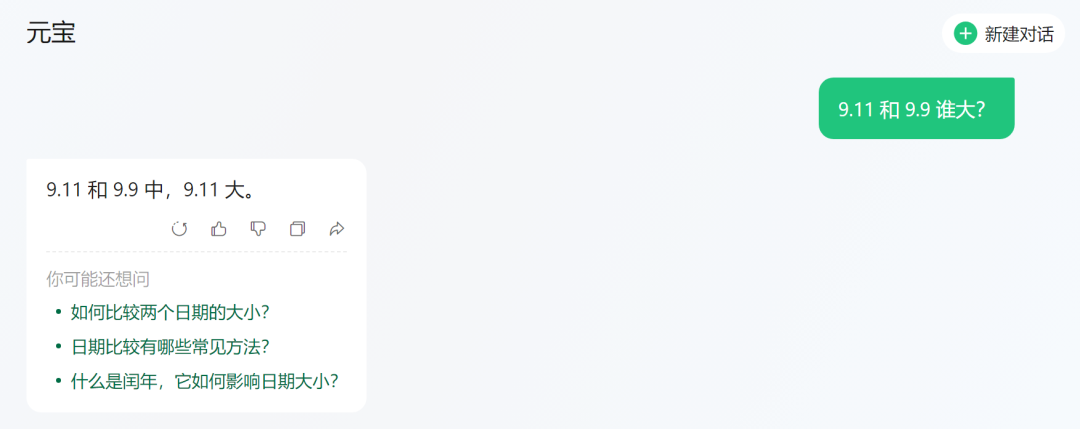
豆包:

不过令人意外的是,免费版本的百度文心 3.5,居然保持了清醒,一边分析一边破题,解释和答案完全正确。
不过看网上消息,它之前也是错的,等我试的时候已经是正确的了。如果是这样,那这解 case 的速度,是真快啊。

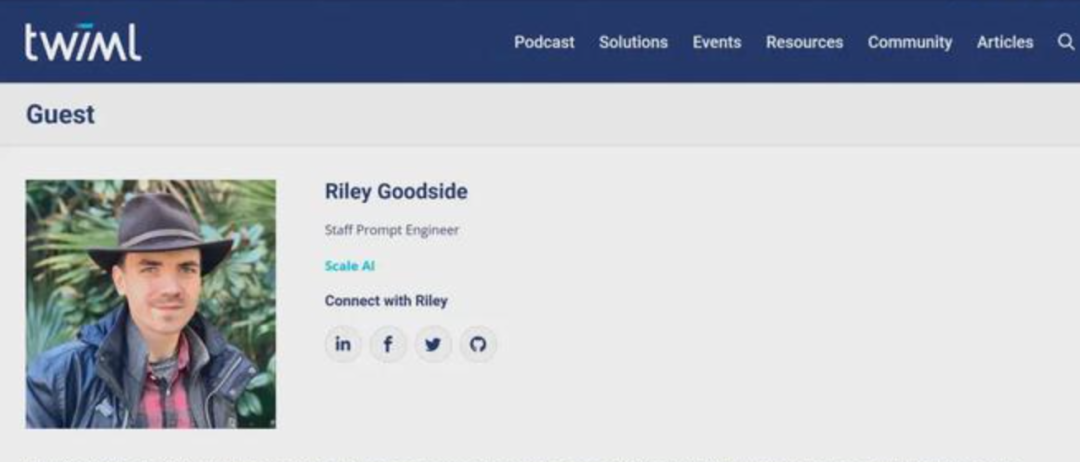
这个问题是由 Riley Goodside 发现的,有史以来第一个全职提示词工程师。目前在硅谷独角兽Scale AI 工作。
这样一个常识问题,为什么到了 AI 手上就变得如此难缠?
网友给出了解释:AI 都是工程师开发的,对于版本号来说,9.11 确实比 9.9 更大;对于书本的目录来说,9.11 也确实排在 9.9 后面。
在大量的训练集中,常识的输入可能确实不如这些样本多,导致了 AI 把版本号、书籍目录的理解方式代入了常识。
而众所周知,大模型使用 token 的方式理解文字。OpenAI 使用开源的 Tokenizer ,可以用来观察大模型是如何理解这个问题的。
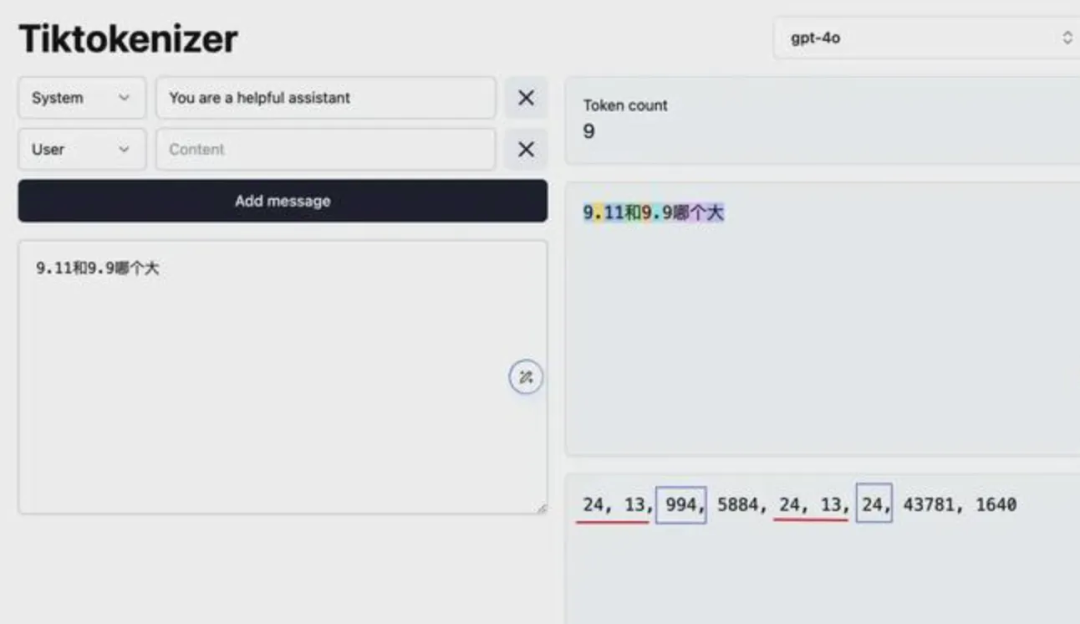
可以看出,9 和小数点分别被分配为“24”和“13”,小数点后的 9 同样也是“24”,而 11 被分配到“994”。
这样问题就很清晰了,模型先比较了 9,发现大小相同,然后比较小数点后面的部分,发现 11 比 9 大,就给出了 9.11 更大的结论。
知道了问题所在,只要向 AI 解释这是一个“双精度浮点数”,它们就能很明确地解决问题了。
只要有了额外条件,AI 似乎就能正确判断这两个数的大小。而 Goodside 在反复试验后说到,想让 AI 上这个当,需要把选项放在提问前面,如果调换顺序,就不会出错。
这个问题让人不禁联想到前些年网上热传的 0.8 x 0.5 等于几,现在轮到 AI 开始反常识了。
AI 大模型发展的道路,至少在数学方面,依旧是任重而道远啊。
<END>
点这里👇关注我,记得标星呀~普通人也能直接使用 GPT4.0
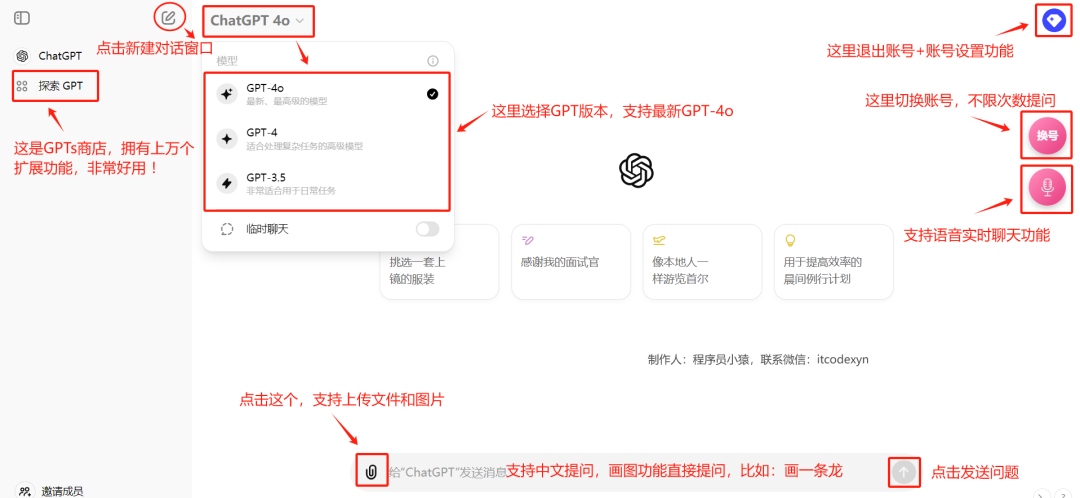
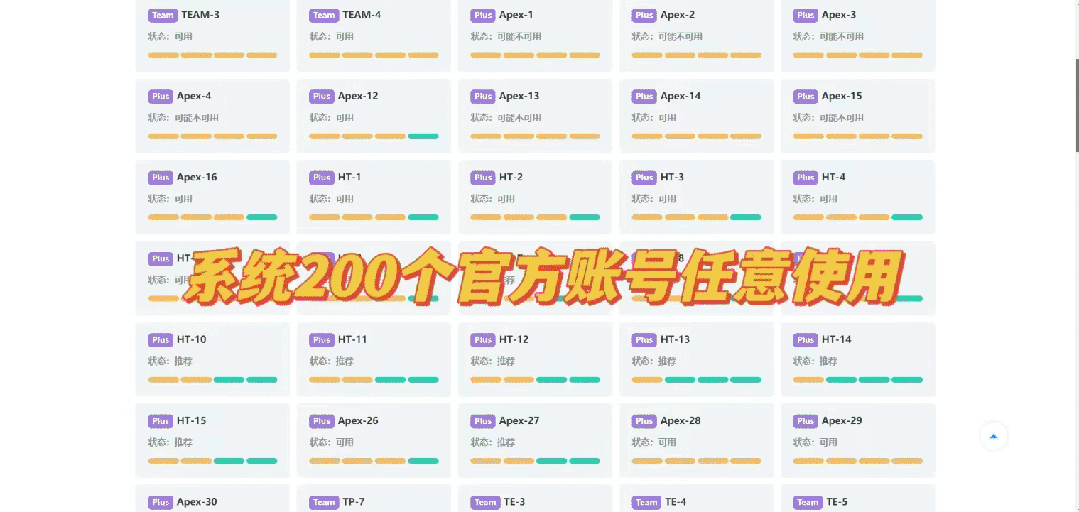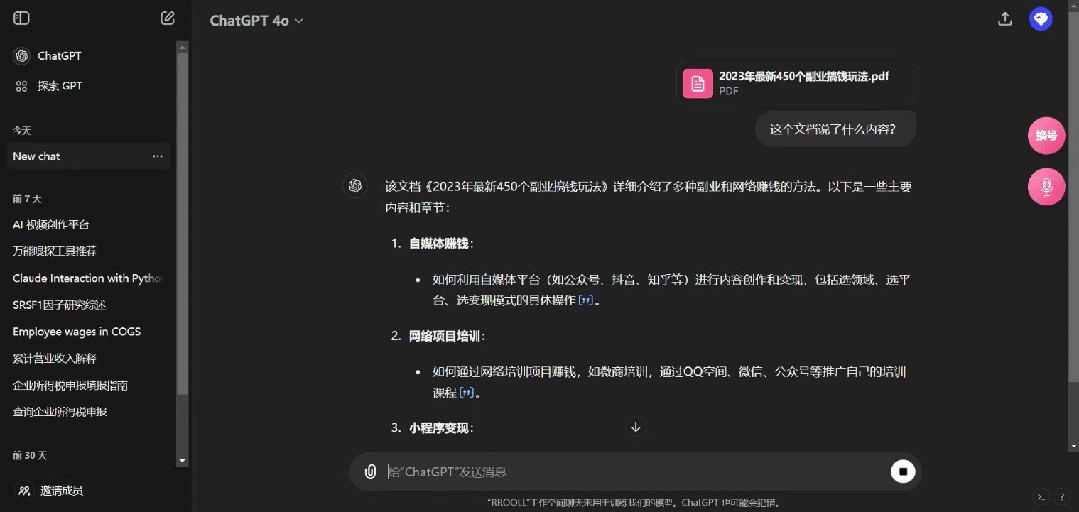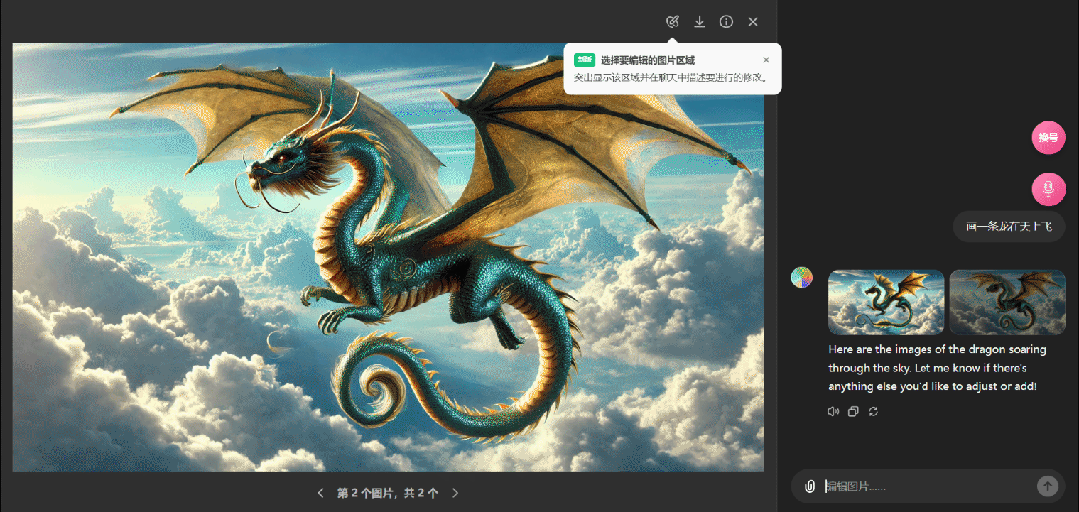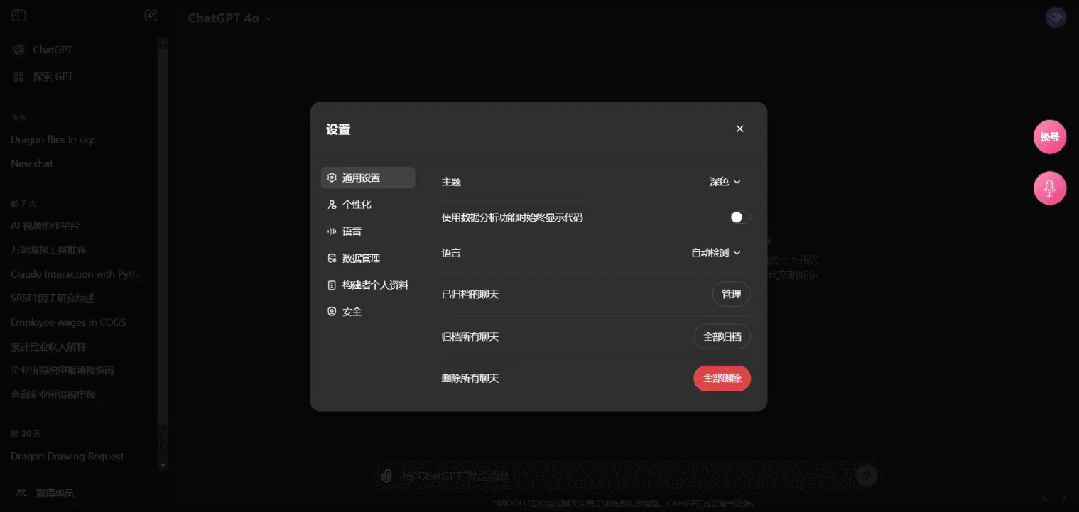
一次性买了200多个官方Plus会员放在一个系统的池子里,共享给大家使用 。每月只需要90元,比官方便宜了一半不止,就可以直接使用官方GPT 4.0 ,而且国内网络就可以直接登录 ,不需要额外的上网工具 。
跟购买官方独立账号是完全一样的:支持GPTs、语音实时聊天功能、联网功能、上传文件、数据分析、AI画图、图片识别、消息隔离功能等,而且不限次数使用 。

扫码可以加我微信,备注:GPT4
我会立马通过微信好友请求
感谢你的分享,点赞,在看三连 


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









