





在前面我们已经介绍了题目中几个类分别实现了哪个接口。HashSet和TreeSet都直接或者间接的继承了Set接口,所以它存储的元素中不允许出现重复元素。
我们先来介绍一下HashSet。HashSet称为哈希表又称散列表。散列表算法的基本思想是:以结点的关键字为自变量,通过一定的函数关系(散列函数)计算出对应的函数值,以这个值作为该结点存储在散列表中的地址。当散列表中的元素存放太满,就必须进行再散列,将产生一个新的散列表,所有元素存放到新的散列表中,原先的散列表将被删除。在Java语言中,通过负载因子(load factor)来决定何时对散列表进行再散列。例如:如果负载因子是0.75,当散列表中已经有75%的位置已经放满,那么将进行再散列。负载因子越高(越接近1.0),内存的使用效率越高,元素的寻找时间越长。负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多。HashSet类的缺省负载因子是0.75。
对于HashSet我们还应该知道HashSet实质是通过HashMap来实现的。还应该记住我们应该为定义到HashSet中的对象定义hashCode和equals方法。在HashSet中并没有get方法,我们只能通过迭代器去访问其中的元素。下面我们给出一个例子:
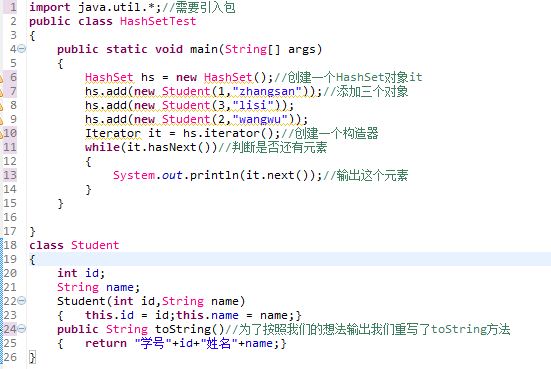
//学号3姓名lisi
学号1姓名zhangsan
学号2姓名wangwu
上面的程序输出的结果跟我们预料的一样,但是这个并不是正确的。我们在第7行的地方在加上一句代码:hs.add(new Stuent(1,”zhangsan”);输出的结果如下:
//学号1姓名zhangsan
学号3姓名lisi
学号2姓名wangwu
学号1姓名zhangsan
HashSet里面不可以存储相同的元素,但是我们还是输入进去了,这个并不是我们想要的。这个是因为HashSet在判断是否是相同元素的时候是根据散列值判断的,虽然他们看上去一样但是其散列值是不同的。为了实现我们想要的结果我们必须重写hashCode和equals方法。下面我们修改一下上面的程序:
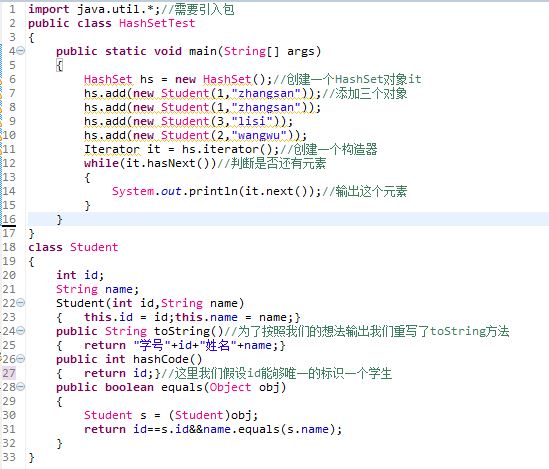
//学号1姓名zhangsan
学号2姓名wangwu
学号3姓名lisi
上面我输出了我们想要的结果,下面我们说一下TreeSet。TreeSet和HashSet不同的地方就是前者存入的时候会按照一定的顺序存入。TreeSet是一个有序集合,TreeSet中元素将按照升序排列,缺省是按照自然顺序进行排列,意味着TreeSet中元素要实现Comparable接口。我们可以在构造TreeSet对象时,传递实现了Comparator接口的比较器对象。我们可以为我们需要存入的对象实现CompareTo方法。我们也可以实现一个比较器,在我们创建TreeSet的时候作为参数传入。其他的跟HashSet都基本相同,读者可以自己去试验。
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
对于HashMap、TreeMap和HashSet、TreeSet基本的方法都差不多。它们两个存储的时候需要一个键值和一个对象作为参数。对于这两个类大家可以参照Java的帮助文档学习一下。我们这里就不过多的讲解了。
希望本次文章对你有帮助,如有错误请指出。















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









