





继前篇mahout 中Twenty Newsgroups Classification运行实例,本篇主要分析该算法的各个任务,首先是第一个任务,即seqdirectory,在提示信息里面的内容如下:
+ ./bin/mahout seqdirectory -i /home/mahout/mahout-work-mahout/20news-all -o /home/mahout/mahout-work-mahout/20news-seq
Warning: $HADOOP_HOME is deprecated.
Running on hadoop, using /home/mahout/hadoop-1.0.4/bin/hadoop and HADOOP_CONF_DIR=
MAHOUT-JOB: /home/mahout/mahout-d-0.7/mahout-examples-0.7-job.jar
13/08/26 23:38:49 INFO common.AbstractJob: Command line arguments: {--charset=[UTF-8], --chunkSize=[64], --endPhase=[2147483647], --fileFilterClass=[org.apache.mahout.text.PrefixAdditionFilter], --input=[/home/mahout/mahout-work-mahout/20news-all], --keyPrefix=[], --output=[/home/mahout/mahout-work-mahout/20news-seq], --startPhase=[0], --tempDir=[temp]}
13/08/26 23:42:57 INFO driver.MahoutDriver: Program took 248530 ms (Minutes: 4.142166666666666)package mahout.fansy.test.bayes;
import org.apache.mahout.text.SequenceFilesFromDirectory;
public class TestSeqdirectory {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//SequenceFilesFromDirectory sf=new SequenceFilesFromDirectory();
String[] arg={"-fs","ubuntu:9000","-jt","ubuntu:9001",
"-i", "/home/mahout/mahout-work-mahout/20news-all",
"-o" ,"/home/mahout/mahout-work-mahout0/20news-seq"};
SequenceFilesFromDirectory.main(arg);
}
}
1. SequenceFilesFromDirectory.main()-->run(SequenceFilesFromDirectory类中60行),源代码如下:
public int run(String[] args) throws Exception {
addOptions();
if (parseArguments(args) == null) {
return -1;
}
Map<String, String> options = parseOptions();
Path input = getInputPath();
Path output = getOutputPath();
if (hasOption(DefaultOptionCreator.OVERWRITE_OPTION)) {
Configuration conf = new Configuration();
HadoopUtil.delete(conf, output);
}
String keyPrefix = getOption(KEY_PREFIX_OPTION[0]);
Charset charset = Charset.forName(getOption(CHARSET_OPTION[0]));
Configuration conf = getConf();
FileSystem fs = FileSystem.get(input.toUri(), conf);
ChunkedWriter writer = new ChunkedWriter(conf, Integer.parseInt(options.get(CHUNK_SIZE_OPTION[0])), output);
try {
SequenceFilesFromDirectoryFilter pathFilter;
String fileFilterClassName = options.get(FILE_FILTER_CLASS_OPTION[0]);
if (PrefixAdditionFilter.class.getName().equals(fileFilterClassName)) {
pathFilter = new PrefixAdditionFilter(conf, keyPrefix, options, writer, charset, fs);
} else {
Class<? extends SequenceFilesFromDirectoryFilter> pathFilterClass =
Class.forName(fileFilterClassName).asSubclass(SequenceFilesFromDirectoryFilter.class);
Constructor<? extends SequenceFilesFromDirectoryFilter> constructor =
pathFilterClass.getConstructor(Configuration.class,
String.class,
Map.class,
ChunkedWriter.class,
Charset.class,
FileSystem.class);
pathFilter = constructor.newInstance(conf, keyPrefix, options, writer, fs);
}
fs.listStatus(input, pathFilter);
} finally {
Closeables.closeQuietly(writer);
}
return 0;
}Status(input,pathFilter);
2. fs.listStatus()-->listStatus(FileSystem 865行),具体如下:
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException {
ArrayList<FileStatus> results = new ArrayList<FileStatus>();
listStatus(results, f, filter);
return results.toArray(new FileStatus[results.size()]);
}private void listStatus(ArrayList<FileStatus> results, Path f,
PathFilter filter) throws IOException {
FileStatus listing[] = listStatus(f);
if (listing != null) {
for (int i = 0; i < listing.length; i++) {
if (filter.accept(listing[i].getPath())) {
results.add(listing[i]);
}
}
}
}public final boolean accept(Path current) {
log.debug("CURRENT: {}", current.getName());
try {
for (FileStatus fst : fs.listStatus(current)) {
log.debug("CHILD: {}", fst.getPath().getName());
process(fst, current);
}
} catch (IOException ioe) {
throw new IllegalStateException(ioe);
}
return false;
}protected void process(FileStatus fst, Path current) throws IOException {
FileSystem fs = getFs();
ChunkedWriter writer = getWriter();
if (fst.isDir()) {
String dirPath = getPrefix() + Path.SEPARATOR + current.getName() + Path.SEPARATOR + fst.getPath().getName();
fs.listStatus(fst.getPath(),
new PrefixAdditionFilter(getConf(), dirPath, getOptions(), writer, getCharset(), fs));
} else {
InputStream in = null;
try {
in = fs.open(fst.getPath());
StringBuilder file = new StringBuilder();
for (String aFit : new FileLineIterable(in, getCharset(), false)) {
file.append(aFit).append('\n');
}
String name = current.getName().equals(fst.getPath().getName())
? current.getName()
: current.getName() + Path.SEPARATOR + fst.getPath().getName();
writer.write(getPrefix() + Path.SEPARATOR + name, file.toString());
} finally {
Closeables.closeQuietly(in);
}
}
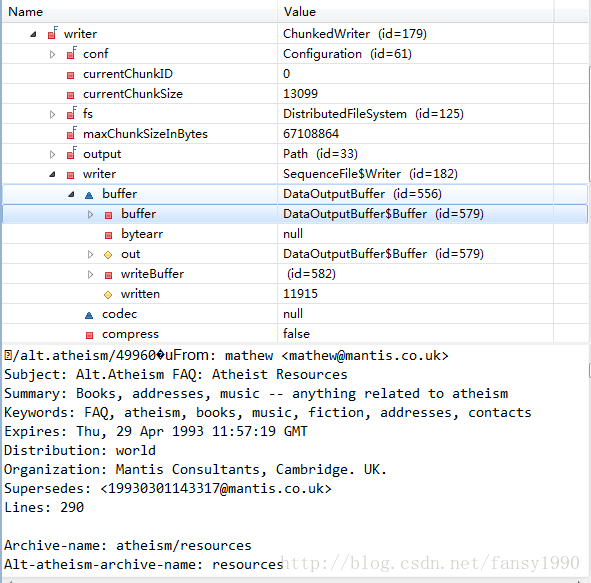
}比如针对20news文件,第一次调用这个方法的时候对应的fst的路径是hdfs://ubuntu:9000/home/mahout/mahout-work-mahout/20news-all/alt.atheism/49960,这个是一个文件,而非文件夹,所以进入if的else里面;然后打开了这个文件 in=fs.open(); 设置了一个临时变量 StringBuffer file用来存储整个文件;下面的for循环就是按行读取文件,然后把相应的字符串放入file变量中;最后使用writer.write()方法把file变量写入到输出writer变量中,在变量中可以查看到,如下图:
这里并没有写入到文件中,而是在最后全部文件都读取到writer变量中后才把writer变量的buffer写入到输出文件的。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990














 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









