






Fisherface是由Ronald Fisher发明的,想必这就是Fisherface名字由来。Fisherface所基于的LDA(Linear Discriminant Analysis,线性判别分析)理论和特征脸里用到的PCA有相似之处,都是对原有数据进行整体降维映射到低维空间的方法,LDA和PCA都是从数据整体入手而不同于LBP提取局部纹理特征。如果阅读本文有难度,可以考虑自学斯坦福公开课机器学习或者补充线代等数学知识。
同时作者要感谢cnblogs上的大牛JerryLead,本篇博文基本摘自他的线性判别分析(Linear Discriminant Analysis)[1]。
1、数据集是二类情况
通常情况下,待匹配人脸要和人脸库内的多张人脸匹配,所以这是一个多分类的情况。出于简单考虑,可以先介绍二类的情况然后拓展到多类。假设有二维平面上的两个点集x(x是包含横纵坐标的二维向量),它们的分布如下图(1)(分别以蓝点和红点表示数据):
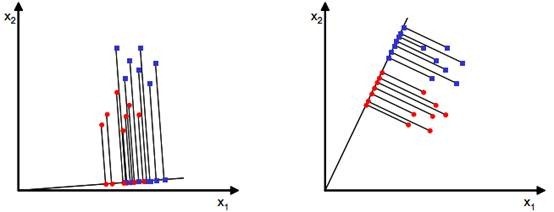
原有数据是散布在平面上的二维数据,如果想用一维的量(比如到圆点的距离)来合理的表示而且区分开这些数据,该怎么办呢?一种有效的方法是找到一个合适的向量w(和数据相同维数),将数据投影到w上(会得到一个标量,直观的理解就是投影点到坐标原点的距离),根据投影点来表示和区分原有数据。以数学公式给出投影点到到原点的距离:y=wTx。图(1)给出了两种w方案,w以从原点出发的直线来表示,直线上的点是原数据的投影点。直观判断右侧的w更好些,其上的投影点能够合理的区分原有的两个数据集。但是计算机不知道这些,所以必须要有确定的方法来计算这个w。
首先计算每类数据的均值(中心点):
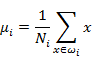
这里的i是数据的分类个数,Ni代表某个分类下的数据点数,比如u1代表红点的中心,u2代表蓝点的中心。
数据点投影到w上的中心为:
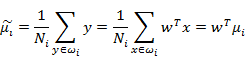
如何判断向量w最佳呢,可以从两方面考虑:1、不同的分类得到的投影点要尽量分开;2、同一个分类投影后得到的点要尽量聚合。从这两方面考虑,可以定义如下公式:
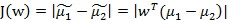
J(w)代表不同分类投影中心的距离,它的值越大越好。
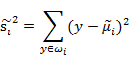
上式称之为散列值(scatter matrixs),代表同一个分类投影后的散列值ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









