





Author:文初
Email:wenchu.cenwc@alibaba-inc.com
Blog:http://blog.csdn.net/cenwenchu79
什么是Dynamo? Dynamo是Amazon的高效Key-Value存储基础组件(类似于现在被广泛应用的Memcached Cache),当前被用于Amazon很多系统中作为状态管理组件。在2007年年底Amazon的CTO就写了一篇介绍Dynamo设计的文章,今年年底又在日志中提出了对于那篇文章的一个补充:“Eventual consistency”。这也让我再次仔细的去回顾了一下Dynamo的设计思想,其中很多设计技巧是当前分布式系统设计也可以借鉴的。
在说几个设计技巧以前先说几个分布式设计的需求和概念。
1.Eventual consistency。这个概念在阿里系中支付宝架构设计贯彻的最彻底,记得看鲁肃的关于支付宝事务处理中提出的软事务的概念其实就是Eventual consistency的一种表现。对于系统设计来说,系统中的事件往往都会相互关联,孤立的事件在当前的互联网行业中变得微乎其微。事件与事件之间存在着一系列的约束和因果关联,就需要靠事务来保证。事务的特质就是ACID,而ACID在当前分布式系统设计的模式下常常会和可用性以及高效性产生冲突。ACID中其他三者都很好理解,而C“一致性”往往是初学者比较难以理解的一个特质。用银行存款操作的比喻就较为容易理解,银行帐户在操作前有100元,存入了50元以后,就有了150元,操作前和操作后保持了银行帐户的一致性,存入50元以后帐户仅仅增加了50元,总额没有超过150或者少于150,在常规看来是在正常不过的了,但是试想,如果有两个操作在一个瞬间作操作,一个需要给账户增加50元,一个要给账户增加30元,前一个操作是基于100元的基础增加,后一个也是基于100元增加,然后后一个操作晚于前一个操作提交,那么最后帐号里面就只有130,这就是可以认为银行帐号在两次操作以后出现了状态不一致性。一致性就好比自然界平衡,降水、蒸发维持生态平常。Eventual consistency其实是对一致性的一种延展,过程中允许部分不一致,但是在事务处理结束或者有限的时间内保持事务的一致性。一句话简单概括就是:“过程松,结果紧,最终结果必须保持一致性”。
2.可用性,容错性,高效性。这三个非功能性需求在当前架构设计中已经成为最基本的设计要求,但三者常常在设计中又存在矛盾。容错性要高就需要作更多额外的工作,而更多的额外工作必将降低高效的特点,同时额外工作也会间接增加系统复杂度进而影响可用性。在设计中协调者三者的关系,没有什么准则可以遵循,只有根据实际的系统状况来判断如何达到最好的效果,在后面的Dynamo的三个参数配置设计就可以看到通过配置如何平衡三者关系并且将组件应用到上层系统中。
3.分布式设计中两类一致性问题:单点数据读写一致性问题和分布式数据读写一致性问题。前者通常通过数据存储的服务端控制即可(类似于DB的控制),后者通常通过消息传播的方式来实现(类似于JGroup在多播通道传播同步消息)。
4.冲突解决。这个我想大部分开发者每天都会接触到,代码控制(SVN)就是版本控制发现冲突的具体体现。冲突检测通常最简单采用last write的方式,也就好比数据库的解决方式,谁最后修改就以谁的为准。其他冲突检测和版本合并就十分复杂,有些不得不靠人工干预。这点也是在数据一致性通过多版本方式来解决的时候遇到的问题。
Dynamo设计中的学习点
1.Consistent hashing算法支持分布式多节点
简单hash算法:N为node数量。处理主键为key的节点为:key.hashValue() mod N。
Consistent hashing算法:环状结构。虚拟节点来替换实体节点被分配到环状某一位置上(根据处理能力不同可以将一个实体节点映射到多个虚拟节点上)。主键为key的节点position = hash(key),在环上按照顺时针查找value大于position的第一个虚拟节点,由它对应的实体节点处理。下图中k就优先由虚拟节点B来处理。
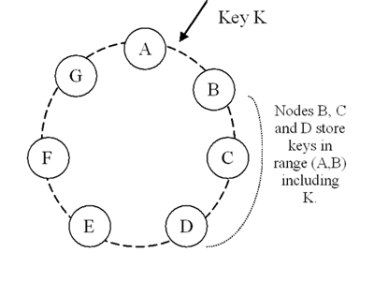
Consistent hashing的优点:(其实主要作用是在虚拟节点以及环状负责制上)
a.支持不同能力节点的权重设置。由于采用了虚拟节点,通过虚拟节点和实体节点多对一的配置可以实现处理能力权重配置。
b.新增或者删除节点动态配置成为可能,比较上一种简单算法,由于实体节点的数目直接影响到了hash算法,因此导致新增或者删除节点影响全局数据的重新映射。而Consistent hashing算法不受节点数目影响,它的区间负责以及多节点冗余处理降低动态增减节点的内容失效影响。在一些情况下需要不重新启动而动态的增加或者减少处理节点,因此采用了Consistent hashing的区间负责制,就好比上图key k的内容落在了A和B的区间内,根据规则由B优先来处理,当B失效的时候也可以由C,D来处理,根据环状最近可用节点来选择。如果在B节点和A节点新增一个节点或者删除B节点,影响的数据处理映射也仅仅是是A和B区间内数据。
c.同时对于压力分摊也有帮助。这个优势还是沿用B来说,新增、删除或者失效一个实体节点,它可能对应的是多个虚拟节点,此时数据压力会分摊到环状其他的多个节点,新增也是同样,这样可以降低压力分摊的风险。
Consistent hashing算法其实也可以采用Tree方式来实现,Memcached的客户端版本中就有支持采用Tree的。
2.Vector clock管理数据多版本
为什么会存在数据多版本,其实这个在高并发分布式处理中经常会遇到,同时也是容错性和高可用性的一种解决方式。两方面来看,首先在高并发分布式处理过程中,对于单个资源的操作要么采用阻塞方式要么采用多版本方式,前者效率相对较低但是处理简单,后者效率高但是处理复杂。对于容错性和高可用性要求高的情况下,多版本也是一种解决手段,就好比Amazon的购物车就要求任何时候都要支持修改,如果某一些处理节点当前不可用,那么就需要支持多个节点的处理以及数据多点的存储,这样就出现了不同节点数据的不同版本问题。
Vector clock根据操作者的不同为一个对象创建了多个版本计数器,并且通过多个版本计数器来判断这些版本是否属于并行分支还是串行分支,由此来确定是否需要解决冲突。
解决冲突分成两种方式,一种是客户端选择如何解决冲突,一种是服务端解决冲突。前者适用于较为复杂的冲突解决,后者适用于简单的版本冲突解决。不过不论哪一种方式,在Dynamo的处理中,客户端和服务端之间对于对象的操作交互过程都会带有版本历史信息。
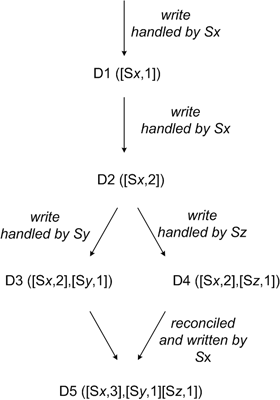
上图是描述一个对象D的Vector clock历史状况。首先D被Sx节点处理,那么处理以后产生了第一个版本D1([Sx,1]),然后又被Sx处理了,产生了第二个版本D1([Sx,2]),因此需要判断是否需要版本冲突解决。判断版本冲突主要是检查Vector clock中的多个版本与上一个历史Vector clock的关系,如果历史的和当前的Vector clock中所有的节点版本都是大于等于的关系,那么就认为两个版本不冲突,可以忽略前一个版本。就拿D2和D1来看,里面只有一个Sx的版本记录,对比2大于1,因此就认为可以忽略前一个版本。D3和D4分别是基于D2版本,两个不同节点处理后的结果,根据上面的冲突检测可以认为D3和D4版本无法忽略任何一个版本,因此此时对于D对象来说存在两个版本D3和D4,当Sx从服务端获取到数据以后做处理,此时就产生了三个版本。至于这三个版本由客户端Sx来解决还是服务端后期自动通过后台完成这个就需要根据应用来决定了。
Vector clock只是提供了一种手段来解决多版本的问题,至于客户端解决冲突还是服务端解决冲突这个需要根据具体情况来选择。
3.load balance的几种模式。
a.客户端实施load balance。采用客户端包来实现分发算法,同时配置分发节点情况。Memcached Cache客户端使用的一种基本方式。
b.服务端硬件实现load balance。
c.客户端改进模式。配制节点以及算法都可以采用集中的Master来管理和维护,包括心跳检测等手段由Master来实现。当然支持Master失效的容错性策略实施。
d.服务端模式改进。采用preference list来分离接受和处理任务的节点。
首先采用A模式可以防止B模式在单点的情况下出现的不可用风险,也可以减轻高并发下单点的压力,提高效率(这点淘宝的同学有和我提到过,他们采用的“软负载”方式)。但是A模式会增加对于客户端包的依赖性,对于扩展和升级都会有一定的限制。
其次B模式是最省心的方式,扩展性也比较好,但是就是在上面提到的单点问题会有所限制。
C方式是对于A方式的一种改进,我以前的一篇文章中提到过,这样可以提高A的可扩展性以及可维护性,减小对于客户端包的依赖,但是增加了系统复杂度,同时Master也是会有单点的问题,不过问题不大(失效的情况下就是退化到了A模式)。
D方式是解决服务端简单的分发而导致处理的不均衡性,其实这种模式也可以改进客户端的算法。因为通过Hash算法未必能够将压力分摊均匀,就好比一些处理需要耗时比较久一些处理耗时比较少,系统对于key的映射不均衡等等问题,不过在Dynamo中描述的并不很明确,其中的算法还是要根据实际情况来做的。
4.三个参数平衡可用性和容错性。
在Dynamo系统中通过三个参数(N,R,W)来实现可用性和容错性的平衡。对于数据存储系统来说,Dynamo的节点采用冗余存储是保证容错性的必要手段,N就代表一份数据将会在系统多少个节点存储。R表示在读取某一存储的数据时,最少参与节点数,也就是最少需要有多少个节点返回存储的信息才算是成功读取了该数据内容。W表示在存储某一个数据时,最少参与节点数,也就是最少要有多少个节点表示存储成功才算是成功存储了该数据,通常情况下对于N的复制可以阻塞等待也可以后台异步处理,因此W可以和N不一致。这里的R,W的配置仅仅表示参与数量的配置,但是当环状节点其中一个失效的时候,会递推到下一个节点来处理。
很明显的R,W的数字越大直接会影响系统的性能和可用性,但是R,W越大却能够保证容错性的增强。因此如何配置N,R,W成为平衡容错性和可用性的一种重要方式。对于一个系统结构中,节点本身稳定性较高的情况下,将R,W配置的较小,提升系统的可用性。对于节点稳定性不可靠的情况下,适当增大R,W配置,提升系统的容错性,同时也对可用性有一定帮助。
另一方面,从读写能力和业务操作读写比例修改R,W的配置来优化系统的性能。对于读操作十分密集写相对来说较少的情况来说,配置R=1,W=N,则可以实现高读引擎,系统只要还有一个节点可以读取数据就可以读到数据。对于写比较频繁的情况来说,那么可以配置R=N,W=1实现高写引擎,系统只要还有一个节点可以写入,就可以保证业务写入的正常,不过读取数据进行冲突解决会比较复杂一些。
除了配置这三个参数以外,通过读写配置本地缓存的方式可以提高系统整体性能以及容错性。
5.异步处理容错数据复制
当一个数据存储节点出现问题以后,数据存储交由给下一个节点处理,此时除了在下一个节点存储数据内容以外,还会记录下原本数据所应该存储的节点以及当前存储的节点和数据内容,可以放在后台的数据库或者存储中,后台定时处理这些记录,将数据迁移并且删除复制任务。
这部分在我优化Memcache客户端的时候采用的是客户端集群配置lazy复制的方式,当发现配置成集群的节点中优先处理节点没有数据就考虑从其他节点获取,如果存在就异步复制,不过这种方式对于有timestamp的数据就会有问题。
6.采用merkle tree来交验节点存储数据一致性。每一个节点所处理的key range将会被保存在本地节点中,通过tree的方式在组织存储,通过对比节点之间的tree可以快速高效的判断出是否有数据不同步需要异步复制和同步。
Merkle tree的具体算法和使用方式可以参看BT交验改进的文章来学习一下,这片文章写得很通俗易懂,推荐一下:http://www.cnblogs.com/neoragex2002/archive/2006/04/26/385077.html
大家都知道,目前BT应用的发展具有一个非常显著的趋势,那就是用来交换电影、游戏、ISO等大尺寸的数据文件。然而我们也能够观察到另一个事实,那就是:下载文件所对应的索引文件(.torrent)也越来越大,越来越难以下载;这是因为在索引文件中保存了被下载文件中所有数据块的20字节SHA1校验值,而文件越大,数据块越多,则.torrent文件越长(块数=文件长度/数据块长,Bit Torrent标准协议建议块长一般不超过512KB)。
索引文件长度的膨胀将直接加重索引服务器的下载负担,因为所有BT用户均必须从服务器上下载同一份.torrent文件,而这一下载行为本身是集中式的,因而导致系统的扩展性受到较大限制,尤其是用于交换热门资源时;另一方面,为避免索引文件过大,人们在发布种子、制作索引文件时不得不采用增加其基本数据块长度(比如2MB)的方式来减少数据块总数,这将有可能对端对端数据交换性能造成一系列负面影响:因为块长越小,越能帮助我们及时地发现传输错误,试想在2MB块长的情况下,用户直到下载完整个数据块时才通过校验发现传输有误,然后不得不再次重传整个2MB块,这显然较块长为512KB时更加浪费带宽和时间。归根到底,导致上述麻烦的根本原因在于这么一个事实:“.torrent中包含了所有数据块的SHA1校验信息”。
有什么办法让我们既能获得较小的块长而又能减少索引文件长度?Merkle哈希树校验方式为我们提供了一个很好的思路,它试图从校验信息获取及实际校验过程两个方面来改善上述问题。先说说什么是哈希树,以最简单的二叉方式为例,如下图所示,设某文件共13个数据块,我们可以将其padding到16(2的整数次方)个块(注意,padding的空白块仅用于辅助校验,而无需当作数据进行实际传输),每个块均对应一个SHA1校验值,然后再对它们进行反复的两两哈希,直到得出一个唯一的根哈希值为止(root hash, H0),这一计算过程便构成了一棵二元的Merkle哈希树,树中最底层的叶子节点(H15~H30)对应着数据块的实际哈希值,而那些内部节点(H1~H14)我们则可以将其称为“路径哈希值”,它们构成了实际块哈希值与根哈希值H0之间的“校验路径”,比如,数据块8所对应的实际哈希值为H23,则有:SHA1(((SHA1(SHA1(H23,H24),H12),H6),H1)应该等于H0。当然,我们也可以进一步采用n元哈希树来进行上述校验过程,其过程是类似的。
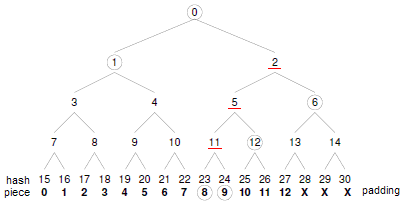
采用Merkle哈希树校验方式能够极大地减小.torrent文件的尺寸,这是因为,一旦采用这种方式来校验数据块,那么便没有必要在.torrent文件中保存所有数据块的校验值了,其中仅需保存一个20字节的SHA1哈希值即可,即整个下载文件的根哈希值H0。想象一下一个3、4GB的文件,其对应.torrent文件却只有100-200字节的样子?heh
下面,让我们来看看其数据块交换及校验的详细过程:
- 以下载某大文件F为例,为启动BT交换,每一个client均必须从索引服务器中下载F所相应的.torrent文件,从而得到文件长度、数据块长及根哈希值H0等必要信息;
- 任一client均可通过轮询Tracking服务器或者是DHT方式来定位其他参与交换F数据的peer,进而与之建立TCP连接进行P2P文件交换,其定位peer的方式基本上没有什么改变。
- 当client从某一peer下载一个数据块时,它将事先向peer发出相应的校验查询请求,要求对方提供校验当前下载块所需的路径哈希值,这一过程可以很方便地通过扩展标准的Peer Wire Protocol实现。以上图为例,当client下载的是数据块8时,在下载开始之前,它将要求peer提供校验块8所需的全部路径哈希值:H24、H12、H6和H1;
- 当client下载完某数据块之后,它将对其进行哈希树校验;仍以校验块8为例,client将首先计算出块8的哈希值H23',然后再根据peer所提供的信息依次计算各层路径哈希值,直至求得一个唯一的根校验值H0',如果H0'等于.torrent文件中的H0,则数据块下载无误,校验通过;反之则校验失败。
- 一旦某数据块校验通过,与其哈希树校验过程相关的所有路径哈希值均可以作为cache缓存下来,而不管其究竟是从peer查询所得的,还是由client自身计算所得的;但值得注意的是,如果该数据块的校验未通过,则其所有相关的路径哈希值均不能被cache,而只能被废弃,因为此时我们无法保证peer所提供的路径哈希值的正确性(不能排除peer故意提供错误路径哈希值和哈希值传输出错的可能)。例如,所有与块8校验相关的路径哈希包括:H24、H12、H6、H1、H11、H5、H2,其中前面4个经查询peer所得,而后面3个则由client自己计算所得。块8验证的结果将决定这7个路径哈希是否可信及是否能被cache。
- 当一定数量的路径哈希值被缓存之后,后继数据块的校验过程将被极大简化。此时我们可以直接利用校验路径上层次最低的已知路径哈希值来对数据块进行部分校验,而无需每次都校验至根哈希值H0,这主要是因为:某一路径哈希值被cache这一事实本身便能够证明其是可信的;例如,在块8校验完成之后,client无需进行额外的peer查询便可以直接对块9进行校验,因此它已经知道了H24的值,并且通过块8的校验过程验证了H24的正确性;而当client需要对块10进行校验时,它仅需向peer查询H26一个校验值即可,由于我们已经知道了H12值,因此对块10的校验仅需2次SHA1哈希即可:一次是计算块哈希H25,一次是计算SHA1(H25,H26),并比较其等不等于H12。同理,当需要验证块12时,由于已知H6,client仅需查询2个路径哈希(H28和H14)和3次SHA1计算(H27、SHA1(H27,H28)和SHA1(H13,H14))即可。缓存的路径哈希值越多,则后继数据块校验越容易,速度也越快。
- 为了进一步提高校验效率,可以考虑在.torrent文件上再做做文章:令其保存整个哈希树中最上面的若干层路径哈希值,而不仅仅只是一个根哈希值H0,底层的路径哈希值则仍然依靠询问peer或client自身计算所得,从而实现.torrent文件尺寸与校验效率的有效折衷。
最后再来看看上述算法的时空效率如何。假设某文件的总块数为M,将其padding至N个块(N=2^p),块长为K,不难看出:
- 为了校验整个文件,共需缓存Sum(2^i):i=0 to p,即2N-1个20字节的SHA1哈希值(包括根哈希值、所有路径哈希值和块哈希值)。以512KB为块长的一个4GB的文件为例,M=8000,则N=8192,p=13,所需存储空间为(2*8192-1)*20=327660 Bytes=319KB,其缓冲区较普通校验方式翻倍,但即便如此,校验所需的数据量仍完全可以接受,即使在最糟糕的情况下:完全不用cache、全部依赖peer查询来获得这些校验值,也无非总共增加了1个基本块不到的流量而已,而且这些流量还是通过P2P方式得到的。
- 在无校验失败的理想情况下,校验整个文件共需M次块长为K的SHA1计算,和N-1次长度为20字节的SHA1运算。即,以哈希树方式校验块长512KB的4GB文件,共需进行8000次长度为512KB的SHA1计算,同时外加8191次长为2*20字节的路径哈希计算,与普通校验方式相比,后者是哈希树额外引入的开销,但由于每次路径哈希的计算量非常小,其影响几可忽略。
综上所述,通过采用哈希树校验方式,我们可以将诸多校验所需哈希值的获取工作分散在P2P数据交换时捎带进行,而不是从.torrent文件中集中获取,从而有利于缓解索引服务器集中下载瓶颈,优化Peer to Peer数据传输性能;在实现上述目的的同时,哈希树校验机制仍能保证以P2P方式获取的校验信息的可靠性,在小块长的情况下,恶意peer几乎无法通过故意提供错误路径哈希值的方式来实现有效的服务拒绝攻击。采用这种方式,我们所需付出的额外代价主要包括几近1倍的校验缓存空间及其SHA1计算量的增长,但是经过简要分析不难看出其实际影响不甚明显,这对于换取较小的块长、提高大文件P2P交换效率而言是值得的。Merkle哈希树校验方式与分布式哈希表技术势必能够帮助BitTorrent协议进一步克服自身的非结构化缺陷,取得更大的应用发展。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









