





它的定义:
根据索引的值指示表中行的有序程度、通知 CBO 关于表的行和索引的同步情况
● 该值与块数相近、表示相同的数据存放得比较集中
● 该值与行数相近、表示表中行的顺序与索引的顺序不同
它的作用:
● 表相对于索引的有序程度
● 通过索引读取整个表时对表执行的逻辑I/O次数
根据索引的值指示表中行的有序程度、通知 CBO 关于表的行和索引的同步情况
● 该值与块数相近、表示相同的数据存放得比较集中
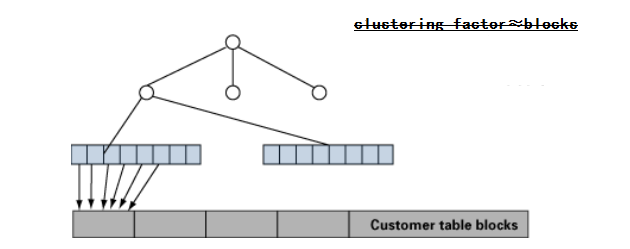
● 该值与行数相近、表示表中行的顺序与索引的顺序不同
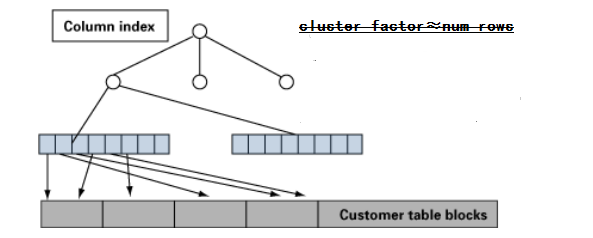
它的作用:
● 表相对于索引的有序程度
● 通过索引读取整个表时对表执行的逻辑I/O次数
它的查询:
hr@ORCL> ed
Wrote file afiedt.buf
1 select a.index_name,b.num_rows,
2 b.blocks,a.clustering_factor
3 from user_indexes a,user_tables b
4 where index_name in ('JOB_ID_PK','DEPT_ID_PK') and
5* a.table_name=b.table_name
6
hr@ORCL> /
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ---------- -----------------
DEPT_ID_PK 27 5 1
JOB_ID_PK 19 5 1 它的意义:
索引并不一定总是合适的访问方法、如果力图重建表来使索引有一个好的聚簇因子、那只是浪费时间















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









