





Linux的伙伴算法把所有的空闲页面分为10个块组,每组中块的大小是2的幂次方个页面,例如,第0组中块的大小都为20(1个页面),第1组中块的大小为都为21(2个页面),第9组中块的大小都为29(512个页面)。也就是说,每一组中块的大小是相同的,且这同样大小的块形成一个链表。
我们通过一个简单的例子来说明该算法的工作原理。
假设要求分配的块其大小为128个页面(由多个页面组成的块我们就叫做页面块)。该算法先在块大小为128个页面的链表中查找,看是否有这样一个空闲块。如果有,就直接分配;如果没有,该算法会查找下一个更大的块,具体地说,就是在块大小为256个页面的链表中查找一个空闲块。如果存在这样的空闲块,内核就把这256个页面分为两等份,一份分配出去,另一份插入到块大小为128个页面的链表中。如果在块大小为256个页面的链表中也没有找到空闲页块,就继续找更大的块,即512个页面的块。如果存在这样的块,内核就从512个页面的块中分出128个页面满足请求,然后从384个页面中取出256个页面插入到块大小为256个页面的链表中。然后把剩余的128个页面插入到块大小为128个页面的链表中。如果512个页面的链表中还没有空闲块,该算法就放弃分配,并发出出错信号。
以上过程的逆过程就是块的释放过程,这也是该算法名字的来由。满足以下条件的两个块称为伙伴:
·两个块的大小相同
·两个块的物理地址连续
伙伴算法把满足以上条件的两个块合并为一个块,该算法是迭代算法,如果合并后的块还可以跟相邻的块进行合并,那么该算法就继续合并。
2.数据结构
在6.2.5节中所介绍的管理区数据结构struct zone_struct中,涉及到空闲区数据结构:
free_area_t free_area[MAX_ORDER];
我们再次对free_area_t给予较详细的描述。
#difineMAX_ORDER10
typestruct free_area_struct {
structlist_headfree_list
unsignedint*map
} free_area_t
其中list_head域是一个通用的双向链表结构,链表中元素的类型将为mem_map_t(即struct page结构)。Map域指向一个位图,其大小取决于现有的页面数。free_area第k项位图的每一位,描述的就是大小为2k个页面的两个伙伴块的状态。如果位图的某位为0,表示一对兄弟块中或者两个都空闲,或者两个都被分配,如果为1,肯定有一块已被分配。当兄弟块都空闲时,内核把它们当作一个大小为2k+1的单独快来处理。如图6.9给出该数据结构的示意图:
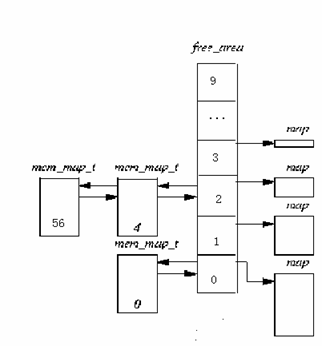
图6.9伙伴系统使用的数据结构
图6.9中,free_aea数组的元素0包含了一个空闲页(页面编号为0);而元素2则包含了两个以4个页面为大小的空闲页面块,第一个页面块的起始编号为4,而第二个页面块的起始编号为56。
我们曾提到,当需要分配若干个内存页面时,用于DMA的内存页面必须是连续的。其实为了便于管理,从伙伴算法可以看出,只要请求分配的块大小不超过512个页面(2KB),内核就尽量分配连续的页面。















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









