






最近看了一些利用python来写一些网站的爬虫以自动下载和排版的文章,于是自己动手也写一个,网络上很多的版本都无法正常运行,因为糗事百科现在不能直接使用url去使用爬虫了,必须要伪装成浏览器来下载。所以必须要加工一下现有的版本才行。
经过一下午的查看资料和手动测试,终于实现了,截图为证:

下面是直接在python GUI/IDLE里运行的结果
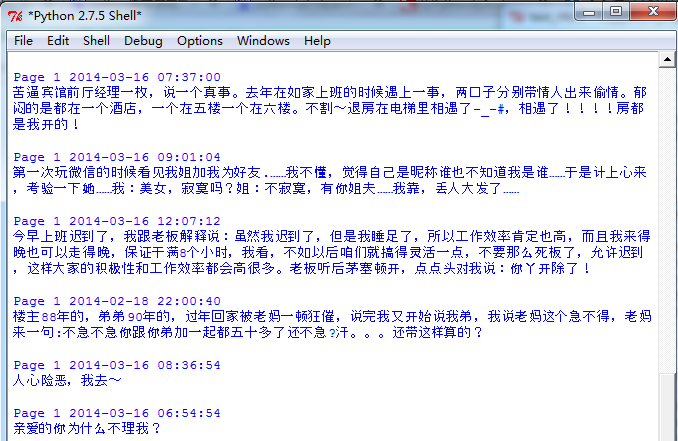
可以直接运行的代码,在http://down.51cto.com/data/1102905,感兴趣可以来尝试看看,以下是一个最简单的直接抓取整个糗事百科的所有源代码的demo,提供下载的版本已经使用正则表达式做过了精细的处理,效果如上图。
# python 2.7.5
import urllib2
myUrl = "http://m.qiushibaike.com/hot/page/"
headers = ('User-Agent','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36 LBBROWSER')
opener = urllib2.build_opener()
opener.addheaders = [headers]
data = opener.open(myUrl).read()
print data


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









