





Index B-Tree
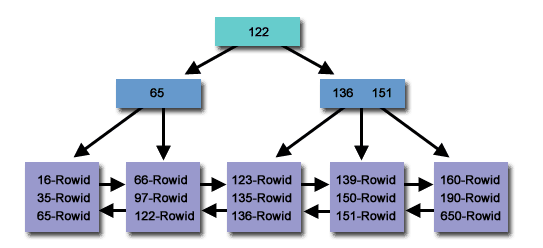
Index的叶节点指向RowID,然后根据RowID再找对应的Block
语法:CREATE INDEX NAME_SALARY_IDX ON PERSON(LAST_NAME ASC,SALARY DESC);
Index Unique Scan
对于unique index来说,如果where条件后面是=,那么就会执行index unique scan。
AskTom:well, the optimizer can look at an index that is unique and say "ah-hah, if you use "where x =:x and y = :y and ...." I'm going to get ONE row back, I can cost that much better" (refer)
Index Unique Scan的条件:
1.Index是唯一性索引;
2.where条件类似于 x = :x and y=: y ...;
Example:
CREATE TABLE PT_TEST AS SELECT * FROM DBA_OBJECTS;
CREATE UNIQUE INDEX UNIQUE_IDX ON PT_TEST(OBJECT_ID); --UNIQUE_IDX是唯一索引
EXEC DBMS_STATS.GATHER_TABLE_STATS('APPS','PT_TEST', CASCADE=>TRUE ); --重做统计
SQL> set auto trace
SQL> select * from pt_test where object_id=10;
Elapsed: 00:00:00.47
Execution Plan
----------------------------------------------------------
Plan hash value: 2398730171
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 97 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| PT_TEST | 1 | 97 | 3 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | UNIQUE_IDX | 1 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=10)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
1194 bytes sent via SQL*Net to client
338 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>
Performance:index unique scan的性能非常好。
Index Range Scan
Case 1
基于上面的case,还是以object_id这个唯一性索引列为条件
SQL> select owner from pt_test where object_id<10;
8 rows selected.
Elapsed: 00:00:00.45
Execution Plan
----------------------------------------------------------
Plan hash value: 1470047708
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| PT_TEST | 1 | 11 | 4 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | UNIQUE_IDX | 1 | | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<10)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
6 consistent gets
0 physical reads
0 redo size
388 bytes sent via SQL*Net to client
338 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
8 rows processed
SQL>Case 2
这个时候给owner字段增加一个非唯一性索引
create index ind_owner on pt_test(owner); --给owner字段增加非唯一性索引SQL> select owner from pt_test where owner='SCOTT';
123 rows selected.
Elapsed: 00:00:00.80
Execution Plan
----------------------------------------------------------
Plan hash value: 2280863269
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1472 | 7360 | 6 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IND_OWNER | 1472 | 7360 | 6 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OWNER"='SCOTT')
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
13 consistent gets
0 physical reads
0 redo size
1653 bytes sent via SQL*Net to client
426 bytes received via SQL*Net from client
10 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
123 rows processed
SQL>对于none unique index来说,如果where 条件后面出现了=,>,<,betweed...and...的时候(返回多行值的时候),就有可能执行index range scan。
Performance:It depends ..How selective ? Throw-away later ? single block IO, CF
The problem is that it is impossible to tell how many rows the range scan is scanning. A range scan that scans 5 rows on average will probably be fairly efficient. However a range scan scanning 10000 rows on average will probably be causing grief.
INDEX SKIP SCAN
Reference:http://blog.csdn.net/robinson1988/article/details/4980611















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









