





 本文详细解析了通过代码示例观察函数入口地址的行程,从Windows编译、链接过程到PE文件格式解读,再到虚拟地址(VA)与物理地址(PA)的转换,直至指令获取与执行过程。深入探讨了TLB、段机制、分页映射、内存访问与Cache机制,以及最终如何通过内存完成指令执行。
本文详细解析了通过代码示例观察函数入口地址的行程,从Windows编译、链接过程到PE文件格式解读,再到虚拟地址(VA)与物理地址(PA)的转换,直至指令获取与执行过程。深入探讨了TLB、段机制、分页映射、内存访问与Cache机制,以及最终如何通过内存完成指令执行。
The Trip of An Address -- An Outline
Jason Lee
[Scene 1. Code -> VA]
本文将以如下代码(ttoaa.c)为例,观察函数f入口地址的行程。
整篇文章的内容会涉及Linux和Windows两种不同系统的场景。
#include <stdio.h> void f() { printf("0x%08x\n", f); } int main() { f(); printf("0x%08x\n", main); return 0; }
将以上代码在Windows上进行编译、链接,得到ttoaa.exe,运行输出:
0x00401000 0x00401020


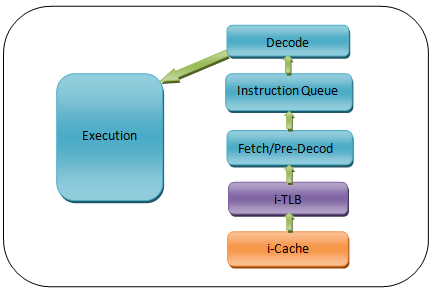
[Scene 3.Segmentation]

由此可知道函数f的VA为0x00401000。那么,这个VA是怎么来的?
通过执行命令dumpbin /ALL ttoaa.exe > ttoaa.exe.dump,可以得到PE文件格式内容。
OPTIONAL HEADER VALUES 10B magic # (PE32) 8.00 linker version 9000 size of code 5000 size of initialized data 0 size of uninitialized data 131E entry point (0040131E) 1000 base of code A000 base of data 400000 image base (00400000 to 0040EFFF) 1000 section alignment 1000 file alignment 4.00 operating system version 0.00 image version
在Optional Header Values中可以看到image base为0x00400000,而base of code为1000,
所以可以知道代码段的起始位置为0x00401000,而函数f正好位于代码段起始位置。
参考ttoaa.exe.dump文件的内容,可以想象这个程序在内存中的布局可能如下图:
[ 图 - 1 ]
[Scene 2.TLB]
关于TLB的位置,我有点小疑惑:是在Segmentation之前还是之后呢?
后来我想,不论是从TLB的实际作用(VA -> PA),还是从目的(加快地址映射)来看,都应该在Segmentation前面。
现在获得了函数f的VA,CPU要执行相应代码,首先要获取第一条指令。
怎么获取这一条指令呢?首先看main函数:
前面就知道main函数的入口地址为0x00401020,从反汇编结果可以看出一进入main函数先保存栈顶指针,继而调用函数f。
现在CPU需要做的就是获取VA为0x00401000的指令,然后执行。
[ 图 - 2 ]
如上图,CPU的取指(Fetch)阶段会先访问TLB,看是否存在VA到PA的映射。
并且由于现在要获取的是指令,所以对应的是i-TLB,即Instruction TLB。
TLB全称为Translation Lookaside Buffer,存储着key-value映射,其中key为VA,value为PA。
由于是第一次访问0x00401000,所以i-TLB中还没有相关映射,需要继续进行地址映射,并把映射结果回填到i-TLB,以加速下次访问。
[Scene 3.Segmentation]
按理说,现在位于代码段中,VA需要加上CS指定的偏移量才能获得线性地址,不过Windows和Linux都采用Flat Model屏蔽了段机制,毕竟32位地址线足够指向整个4G空间。
所以,逻辑地址(或者说虚拟地址)即是线性地址。
为了实现Flat Model(地址平面化),只需要设置CS、DS两个段寄存器(指向GDT中的段描述符)相应的段描述符,将其基址设为0,段范围限制设为4G。
[Scene 4. Paging]
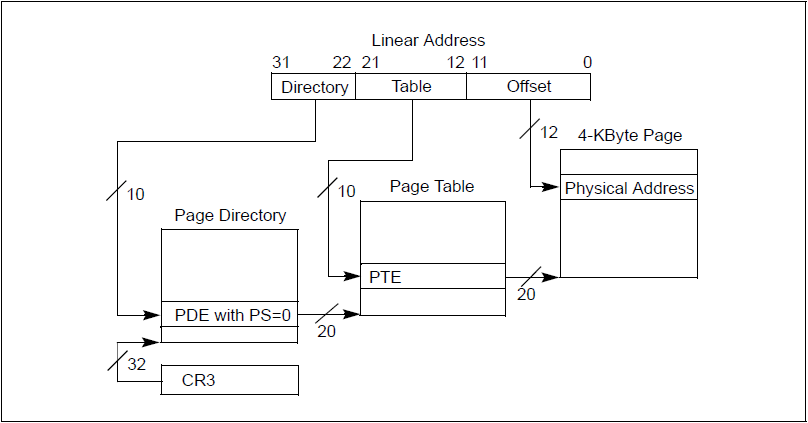
这里考虑的是页面大小为4KB的情况。
如果没有开启PAE,页式映射过程如下(参考Intel Software Developer Manual):
[ 图 - 3 ]
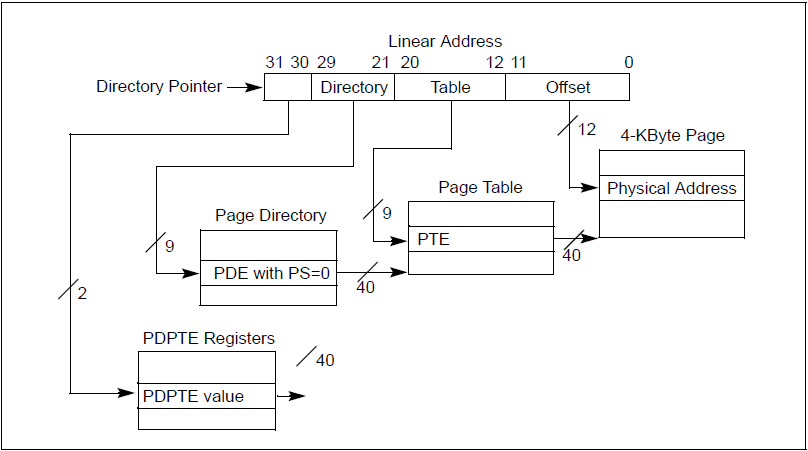
如果开启了PAE,页式映射过程如下:
[ 图 - 4 ]
[Scene 5. Cache]
昂贵的Cache本身就已经是为了尽量提高CPU的执行速度,消除CPU和内存之间的瓶颈,除此之外,芯片设计者
为了提高查找缓存的速度,还将访问Cache和页式映射两件事设计成同时进行的——这利用了低位/页内地址在影射过程的不变形。
先了解下Cache的工作原理。
首先,Cache对于CPU给的地址有两种观察方式:Look-aside和Look-through。
在前者模式下,Cache就是作为旁观者,类似抓了一个包过来观察的同时不影响原有的电路逻辑,直到HIT了才终止到内存寻找的逻辑;在后者模式下,Cache就作为必经之路,一定要先Cache判断为MISS后,才允许电路继续执行。
其次,Cache是由若干个Cache-line组成的,每一个Cache-line又分为Tag和Data,一列Cache-line称为一路(1-way)。
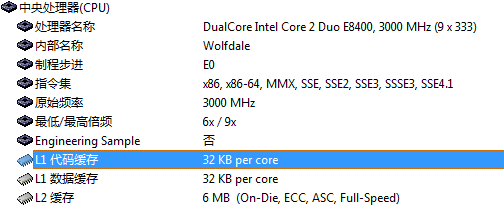
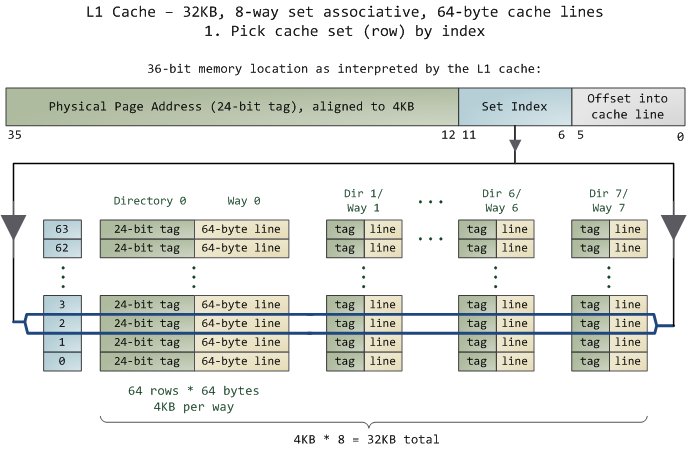
用Everest查看本机数据,得知L1-iCache为32KB:
这里引用下Gustavo Duarte博客关于Cache的用图,刚好和我机子上的芯片是一样的:
从上图可以了解到L1 Cache有8路,每一路有64个Cache-line,每一个Cache-line分为24位的tag和64字节的数据部分。
这里可以发现每一路都是4K,对应着一个内存页面,于是可以产生一种良好(当然还有混乱的、只适合小缓存使用的全相联等方式,这里不讨论)的关联方式,每一个内存页相应的页内地址直接对应一个Cache-line。
根据页式映射[ 图 - 3 ]可以知道低12位是不变的,只在最后定位页内地址时才使用到。所以,在进行页式映射的同时,就可以利用地址的低位信息先确定缓存索引,等物理映射完成后,就不必再匹配索引了,直接利用高24位匹配Cache-line的tag。
如果上述tag和索引都匹配到了,那么地址的低6位就可以用来确定Cache-line中64字节的位置,进而获取数据。
[Scene 6. Memory]
如果Cache那边MISS了,就进一步来到了内存。
这时候由控制总线确定操作类型(比如读或写),然后由地址总线确定内存中的位置,再由数据总线来传输要读或者写的数据。
这些电平的传输就要靠我们拆开机箱、卸下风扇才能看到的芯片引脚了。
如果缺页了,就要进行换页了,由OS来控制。
[End]
结尾有点仓促,不过今天确实有点累(昨天去上海听演唱会,回来又熬夜写了下记录),也想这周一定要结束这一个系列的回顾学习,并以此篇作为一个学习小结,毕竟拖了有段时间了。
[参考资料]
1. Wikipedia
2. Gustavo Duarte
3. CSAPP
4. Linux内源源代码情景分析
5. Windows内核原理与实现
6. Intel Software Developer Manual















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









