





Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处理,例如对日志的分析,也涉及内容部分,结构化数据等。使用Hadoop主要基于可扩展性的考虑,规模从当初的3-4百节点增长到今天单一集群3000节点以上,2-3个集群,支付宝的集群规模也达700台,使用Hbase,个人消费记录,key-value型。
阿里对Hadoop的源码做了如下修改:
- 改进Namenode单点问题
- 增加安全性
- 改善Hbase的稳定性
- 改进反哺Hadoop社区
阿里数据处理的整体架构图如下:

架构分为五层,分别是数据源、计算层、存储层、查询层和产品层。
- 数据源:这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
- 计算层:在数据源层实时产生的数据,通过淘宝主研发的数据传输组件DataX、DbSync和Timetunnel准实时地传输到Hadoop集群“云梯”,是计算层的主要组成部分。在“云梯”上,每天有大约40000个作业对1.5PB的原始数据按照产品需求进行不同的MapReduce计算。一些对实效性要求很高的数据采用“云梯”来计算效率比较低,为此做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
- 存储层:针对前端产品设计了专门的存储层。在这一层,有基于MySQL的分布式关系型数据库集群MyFOX和基于HBase的NoSQL存储集群Prom。
MyFOX的结构图如下:

Prom(即普罗米修斯)结构图如下:

- 查询层(glider)
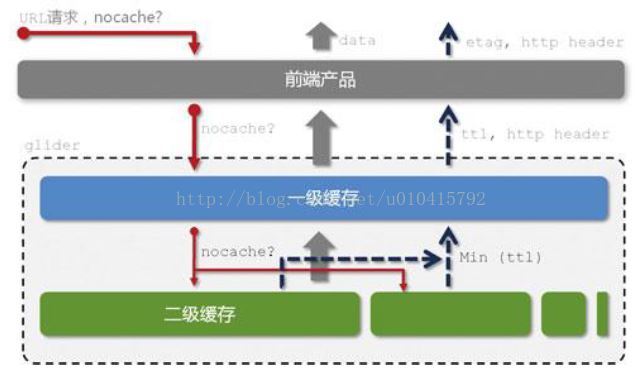
- 产品层:数据魔方、量子恒道等















 3859
3859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









