



转自:http://blog.csdn.net/sxf_824/
任何技术点在你未曾接触过的时候,都是觉得雾里看花,水中望月,既遥远又神秘,但是当你尝试学习并通过实践对其脉络掌握清楚以后,就会觉得原来这么简单,技术就是那么一回事儿。
mapreduce分布式编程模型是google在2004年提出来的,目的是为了解决海量数据的处理,我们通过一段时间的应用,对mapreduce编程的实现机理有了一定了解,现总结如下,希望能为应用开发者提供帮助,我尽量阐述的简单易懂。
海量数据的处理,无非就是首先将海量文件进行打散,然后对打散后的每一份数据块儿分别处理,最终将数据结果归并,所谓分而治之也。你一定会问数据之间有关联怎么办,将数据打散到多台机器上,那有关联的数据是不是就没办法进行分析了?后面会详细介绍。
我们先看一下hadoop的处理流程。
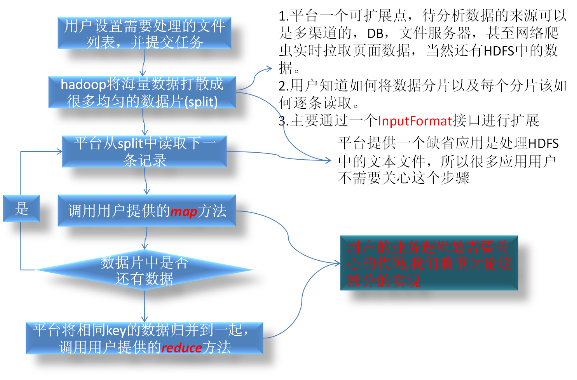
map方法的主要目的是进行数据进行分拣,分析出自己关心的数据,并为与同一类指标相关联的数据都打上一个标记:KEY, 平台会将打上同一个标记KEY的数据从各台机器上收集起来集中到一台机器,然后调用用户的reduce方法进行数据的统计分析。
我们通过一个具体实例学习mapreudce代码的编写。
1.数据统计分析
需求:
假如我有一整天用户访问页面流水日志,日志格式如下:
用户访问的页面 用户QQ号码 用户访问IP .....
www.qq.com/sub/.. 21201421 202.201.22.23
qzone.qq.com/21201421/.. 2222222 10.201.22.23
我需要统计出每个域名一天的用户数(需要去重),访问量,各地区访问人数(假如通过IP可以分析出地区信息)。
那用户的map方法做什么操作呢?
我们看一下map方法的参数
以下的例子都是通过java接入方式实现,当然还支持很多语言(这一点也不重要,呵呵!)
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter);
我们使用系统缺省提供的处理文本文件的InputFormat: TextInputFormat,它是基本按照64M大小进行数据切片的,它提供的RecordReader读出的Key是文件行数,value是一行的内容。Key和value的类型用户也可以自定义(当然这些与我们这次分析主题无关,大家只要知道有这么回事儿就行了)
我们需要分析每个域名一天的用户数,办法很简单,就要找到每次访问是由哪个用户触发的,将所有用户归总起来,再去重后就可以得到用户数,但是数据量多的时候就不好处理了,(*^__^*)...嘻嘻,没关系,有分布式计算平台。
1.Map要做的事情,仅仅是分析出每项记录中的域名,以及用户QQ号码。
OK! 下面是伪代码
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
String lineValue = value.toString();
String[] values = lineValue.split("/t");
//处理values[0]得到域名前缀: 比如 www.qq.com
domain = process(values[0]);
//核心在这里,同一个域名下的数据需要归并到一起,找到与一个域名相关的用户信息(QQ号码),只需要将这个信息打上一个标记反馈给框架。
//标记在这里生成,不要和其他指标冲突哦
key = domain+"_UV";
//得到QQ号码
value = values[1];
//将找到的key->value对反馈给框架
Output.emit(Key ,Value);
}
2.Reduce方法需要做什么
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( postFix( key ) == "_UV" ) //判断是否是用户数这个指标相关的数据
{
//values中的数据就是从各台机器上归总过来的QQ号码
String uv = distinctCount( values );
//push出最终结果
Output.emit(key,uv );
}
}
是不是很简单? 用户并不需要关系分布式平台如何分解任务,如何归并结果,只需要关心自己的业务逻辑,这样的设计也就是所谓的关注点分离。
用户在map方法中从原始数据中分析出与自己关心的某个数据指标有关联的数据,给这个数据打个标签(这个标签是关键,不要和其他指标有重复哦!!,将来平台自动将与这个标签相关连的数据汇总到一起,再提供给用户,调用用户的reduce方法),在reduce方法中只需要都聚集到一起的数据进行统计或其他操作,随便你...
可上面的分析需求我们只满足了一个,其他两个怎么实现呢,我认为到这里大家应该知道该如何写mapreudce程序了,我会利用更简单的伪代码进行描述,ok 开始了。
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
1.域名一天的用户数
从value中分析出域名和QQ号码
output.emit(“$(域名)_UV",$(QQ号码));
2.域名一天的访问量,
output.emit(“$(域名)_PV",1);
看到了没有??这个指标的后缀我改成_PV了,有人会问为什么emit最后一个参数是常数"1"而不是QQ号码呢?这个功能只是做个计数,又不需要去重,我拿QQ号码作甚?还浪费网络带宽,将来我只要将这些个"1"加起来就得到访问次数了。
3.各地区总访问人数
从value中分析出IP,从IP映射出地区
Output.emit( func_IP_to_district(ip)+"_DIS" , 1 );
因为我也只是计数地区访问次数,所以不需要emit出QQ号码
}
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( key的后缀是"_UV" )
{
去重values中的QQ号码,计数count
//最终找到各域名的用户数,交给框架输出
output.emit(key,count);
}
if(key的后缀是"_PV")
{
pvCount=0;
for 循环遍历values
{
pvCount++;
}
//最终找到各域名的访问量,交给框架输出
output.emit(key,pvCount);
}
if(key的后缀是"_DIS")
{
disCount=0;
for 循环遍历values
{
disCount++;
}
//最终找到各域名的访问量,交给框架输出
output.emit(key,disCount);
}
}
以上两个简单的方法,其实也变相实现了单表的grouyby统计。
Select( count(*) , count(distinct(QQ)) ) from table grouy by $取域名(网页url)
Select count(*) from table groupby $取地区(IP);
当然mapreudce不仅仅实现数据的统计操作,各类数据分析都可以进行支持,我在这里只是举个例子。
我们再结合一张数据流向图,进一步说清楚这个问题:
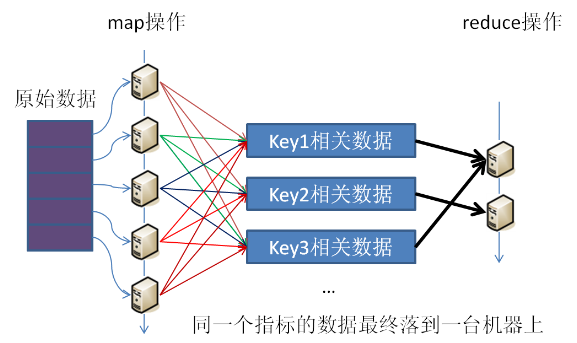
每台机器处理的数据片都不一样,与同某一指标有关联的数据很可能分配到多台机器上,但最终通过key这个纽带,与一个指标相关联的数据被汇总到一起,交给用户进行处理。
2.多数据关联分析
下面我们看一个稍复杂的需求,类似于
select sum(A.price),sum(B.count) form A B where A.id=B.id group by id;
数据A的格式
| id | price | 其他字段1 | 其他字段2 |
| 1 | 2.4 | XXX | XXX |
| 2 | 3.6 | XXX | XXX |
| 1 | 4.8 | XXX | XXX |
| ... |
|
|
|
1,2.4,XXX,XXX
2,3.6,XXX,XXX
1,4.8,XXX,XXX
...
数据B的格式
| id | count | 其他字段1 | 其他字段2 |
| 2 | 8 | XXX | XXX |
| 2 | 4 | XXX | XXX |
| 1 | 3 | XXX | XXX |
| ... |
|
|
|
2,8,XXX,XXX
2,4,XXX,XXX
1,3,XXX,XXX
经过上面case的讲解大家应该比较清楚如何做了,在这里我就不罗嗦了,直接上代码:
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
首先从配置的上下文中判断目前正在对哪一个文件的数据集进行处理
If( 是A文件的数据 )
{
Split(",")得到 自己关心的id和price两个字段。
//这里有些小技巧,我们通过id这个字段做key,那将来两个文件中同一个key的数据就会由平台帮你归并到一起,加上“PRICE:”前缀是为了更方便,准确的区分数据。
Output.emit(id,"PRICE:"+price);
}
If( 是B文件的数据 )
{
Split(",")得到 自己关心的id和count两个字段。
Output.emit(id,"COUNT:"+count);
}
}
//平台将每个key的数据归并到一起时,就会有很多形似如下格式的信息。
比如 id=1的KEY对应的数据序列为:
PRICE:2.4
PRICE:4.8
COUNT:3
...
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
float priceSum = 0.0;
long countSum = 0;
for( Text value :values)
{
根据“PRICE:”和“COUNT:”前缀区分数据代表什么值
if( 是price)
priceSum + = price;
else if( 是count)
countSum += count;
}
output.collect(key,"PRICESUM:"+priceSum +"/t"+"COUNTSUM:"+countSum );
}
是不是很简单,SO EASY!
打个广告,分布式计算平台发布以来已经承接了公司WSD,ISD,SOSO,点击流等BU以及系统的数据分析任务,长期以来系统保持稳定,并通过机器平行扩展的方式维持着一定的数据分析性能,如果哪位同事有海量数据的分析需求,请联系数据平台部-分布式计算平台项目组:tedxu,jakegong,joeyli,stevenshi...
mapreudce代码方式目前只是我们的一种数据分析任务接入方式,java,C++,SQL脚本,shell,python..等脚本都可以实现分析任务的编写
希望分布式计算平台可以帮助大家解决海量数据处理问题,谢谢!!
任何一个解决方案都不可能做到天衣无缝,在不断出现的应用面前,一定会不断暴露出问题,暴露出问题就要解决。
问题1.与同一个KEY相关联的数据不能太多。
需求如下:
假如有如下的数据(我尽量简化字段):
域名 QQ号码 性别。
www.qq.com 21201421 男
....
我需要做类似如下功能的统计 select count(distinct QQ号码) from 数据源 group by 性别。
根据上次的文章,我们可能的做法如下:
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
//如何抽取字段我就不多说了,大家应该都清楚了。
//关键就是这个KEY的取值。
key = 性别+"_UV";
value = QQ号码
//将找到的key->value对反馈给框架
Output.emit(Key ,value);
}
2.Reduce方法需要做什么
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( postFix( key ) == "_UV" ) //判断是否是用户数这个指标相关的数据
{
//values中的数据就是从各台机器上归总过来的QQ号码
String uv = distinctCount( values );
//push出最终结果
Output.emit(key,uv );
}
}
这样的方式乍看上去没什么问题,但是如果真正提交任务,很有可能将多个机器磁盘撑爆都无法完成任务的执行,问题在哪里呢?
关键就是KEY值的生成,因为这个需求是按照性别进行统计分析,很显然最终会有两个KEY:"男性_UV","女性_UV",也就是说这个job只有两个reduce任务,所有男性的QQ号码会集中到一台机器,所有女性的QQ号码也会集中到一台机器,这就导致承担reduce任务的机器负载过大,如果涉及的数据量过大,很可能任务就会执行失败。
问题就在这里,想必大家都已经清楚了,那么如何解决这个问题呢?
解决办法:将KEY打散。
还是这个需求。
map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
{
//关键就是这个KEY的取值,我们按照QQ号码后5五位进行数据打散。
key = 性别+"_UV_"+$func_取QQ号码后五位(QQ号码);
value = QQ号码
//将找到的key->value对反馈给框架
Output.emit(Key ,value);
}
2.Reduce方法需要做什么(reduce代码不做任何变化)
void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
{
if( postFix( key ) == "_UV" ) //判断是否是用户数这个指标相关的数据
{
//values中的数据就是从各台机器上归总过来的QQ号码
String uv = distinctCount( values );
//push出最终结果
Output.emit(key,uv );
}
}
这样就会有很多个类似于如下格式的KEY "男性_UV_00000" "男性_UV_00001" "男性_UV_00002" ..... "男性_UV_99999" (女性时一样)
也就是说
原来的统计结果为:
男性_UV: XXXXXX
女性_UV:XXXXXX
而现在的统计结果为:
以00000结尾的男性的QQ号码_UV: XXXXX
以00001结尾的男性的QQ号码_UV: XXXXX
以00002结尾的男性的QQ号码_UV: XXXXX
.....
以99999结尾的男性的QQ号码_UV: XXXXX
以00000结尾的女性的QQ号码_UV: XXXXX
以00001结尾的女性的QQ号码_UV: XXXXX
以00002结尾的女性的QQ号码_UV: XXXXX
.....
以99999结尾的女性的QQ号码_UV: XXXXX
拿到结果再做一次统计操作就可以得到整体指标数据了。
该模块儿是整个hadoop平台命令类协议通讯的基础,Hadoop平台中所有的协议调用都是通过该套机制进行实现。
术语解释:
远程进程调用
client调用远程Server中某实例的方法。
。
具体实现:
远程过程调用,一定通过网络进行方法参数以及返回值信息传输,该模块儿主要采用通用的网络Server设计实现方式,利用Socket构建Server服务器,并在其上构造一个具体业务实例,client将方法调用参数按照一定格式进行序列化,通过网络传输到Server端,Server解析用户请求调用相应的实例方法,将返回值或者捕获的异常通过网络反馈给client。
整体涉及到的主要类为:
Org.apache.hadoop.ipc.Server以及其内部实现类
org.apache.hadoop.ipc.Client以及其内部实现类
org.apache.hadoop.ipc.Rpc$Server
客户端(client)具体实现:
客户端主要通过proxy模式,利用java自身动态代理技术,Proxy.newProxyInstance
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
该函数主要的两个参数Class<?>[] interfaces, InvocationHandler h
用户调用该函数生成一个Object实例,该实例是一个实现了interfaces接口的具体实例,用户通常将返回的Object转化为具体的interfaces进行使用,当用户调用该实例(实现了interfaces接口)某个具体方法时,系统就将请求转发给InvocationHandler h这个参数对应的实例。
public interface InvocationHandler
{
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}
最终用户的请求被push到InvocationHandler h这个参数的invoke方法,系统将method以及args这两个参数进行序列化,通过网络传输到server端。
主要流程如下:其中Invoker是一个实现了InvocationHandler 接口的类
1.生成代理
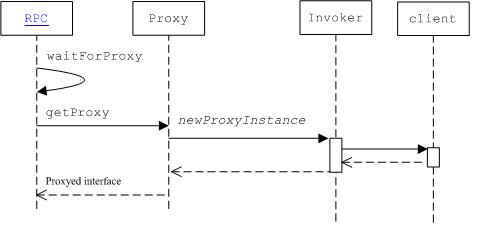
生成远程代理的主要关键步骤就是java的动态代理技术 Proxy.newProxyInstance.
2.远程实例方法调用:

最终用户的请求被push到InvocationHandler h这个参数的invoke方法,系统将method以及args这两个参数进行序列化,通过网络传输到server端(实例化Invoker的同时会实例化一个Client类实例,这个client主要负责将调用方法以及参数序列化以后,通过网络传输到Server端)。
远程调用的主要关键就是Invocation实现了Writable接口,Invocation在write(DataOutput out)函数中将调用的methodName写入到out,将调用方法的参数个数写入out ,同时逐个将参数的className写入out,最后将所有参数逐个写入out,这也就决定了通过RPC实现调用的方法中的参数要么是简单类型,要么是String,要么是实现了Writable接口的类(参数自己知道如何序列化到stream),要么是数组(数组的元素也必须为简单类型,String,实现了Writable接口的类)。
Invocation序列化参数的实现是通过如下函数实现的:
Org.apache.hadoop.io.ObjectWritable.writeObject
(DataOutput out, Object instance,
Class declaredClass, Configuration conf);
{
if (instance == null)
{ // null
instance = new NullInstance(declaredClass, conf);
declaredClass = Writable.class;
}
//首先写入参数名称写入out
UTF8.writeString(out, declaredClass.getName()); // always write declared
//如果是数组
if (declaredClass.isArray())
{ // array
int length = Array.getLength(instance);
//首先写入数组元素个数
out.writeInt(length);
//逐步序列化数组中的元素
for (int i = 0; i < length; i++)
{
writeObject(out, Array.get(instance, i), declaredClass
.getComponentType(), conf);
}
}
//
else if (declaredClass == String.class)
{ // String
UTF8.writeString(out, (String) instance);
}
else if (declaredClass.isPrimitive())
{ // primitive type
if (declaredClass == Boolean.TYPE)
{ // boolean
out.writeBoolean(((Boolean) instance).booleanValue());
}
else if (declaredClass == Character.TYPE)
{ // char
out.writeChar(((Character) instance).charValue());
}
else if (declaredClass == Byte.TYPE)
{ // byte
out.writeByte(((Byte) instance).byteValue());
}
else if (declaredClass == Short.TYPE)
{ // short
out.writeShort(((Short) instance).shortValue());
}
else if (declaredClass == Integer.TYPE)
{ // int
out.writeInt(((Integer) instance).intValue());
}
else if (declaredClass == Long.TYPE)
{ // long
out.writeLong(((Long) instance).longValue());
}
else if (declaredClass == Float.TYPE)
{ // float
out.writeFloat(((Float) instance).floatValue());
}
else if (declaredClass == Double.TYPE)
{ // double
out.writeDouble(((Double) instance).doubleValue());
}
else if (declaredClass == Void.TYPE)
{ // void
}
else
{
throw new IllegalArgumentException("Not a primitive: "
+ declaredClass);
}
}
else if (declaredClass.isEnum())
{ // enum
UTF8.writeString(out, ((Enum) instance).name());
}
//其他元素通过自身实现的writable接口功能实现序列化
else if (Writable.class.isAssignableFrom(declaredClass))
{ // Writable
UTF8.writeString(out, instance.getClass().getName());
((Writable) instance).write(out);
}
else
{
throw new IOException("Can't write: " + instance + " as "
+ declaredClass);
}
}
服务端(Server,具体调用实例所在)具体实现:
1.具体相关类
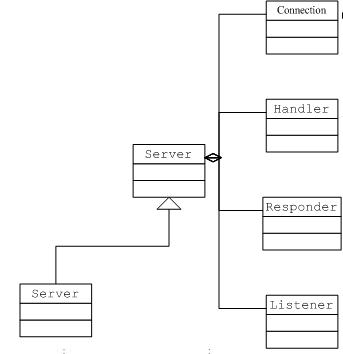
最底层的抽象类Server是整个网络通讯的核心,完成Listener,Responser以及Handler实例的初始化,并控制所有功能模块儿服务的启动。
Listener主要负责Socket的监听以及Connection的建立,同时监控ClientSocket的数据可读事件,通知Connection进行processData,收到完成请求包以后,封装为一个Call对象(包含Connection对象,从网络流中读取的参数信息,调用方法信息),将其放入队列。
Handler主要负责从请求队列中取出数据逐个进行处理,最终调用Server抽奖类的call方法,目前抽象类Server实现了一个具体的实现类,名称也是Server。Server的call方法中根据方法名以及参数构建method对象,并在实际服务的实例对象上进行方法调用。方法调用返回值或异常对象被序列化到一个ByteBuffer,由Responser.doRespond方法进行发送数据。
Responser的主要作用是发送数据,如果数据量比较大一次发送不出去,就监听Write事件,一直Select是否可写,保证数据发送完整.
2.Server端相关调用流程图如下:

设计思想
HDFS中对数据存储的最小单位为block,HDFS会将其存储的大文件打散成很多64M大小的block,并将这些block分别存储在集群中datanode机器上。服务器namenode主要存储文件元数据信息(文件目录结构,具体文件由那些block组成),该部分主要涉及的关键对象为:INode,INodeFile,INodeDirectory,Block,BlockInfo,FSDirectory
NameNode主要负责存储文件目录结构以及具体文件由那些block组成这些元数据基本信息,以上对象存在于namenode上。上述对象的主要关系如下。
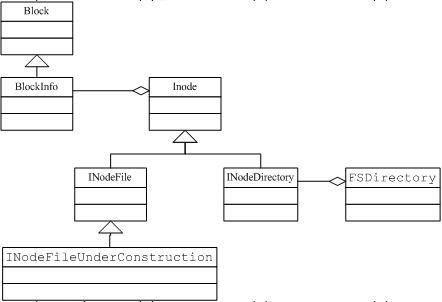
INode
INode是抽象基类,从字面上能够了解到它表示一个文件属性目录结构中的一个节点,它包含的主要属性为:
//节点名称
protected byte[] name;
//父节点
protected INodeDirectory parent;
//最后修改时间
protected long modificationTime;
//访问时间
protected long accessTime;
//访问权限(同linux 0777,0666 之类)
private long permission;
INodeFile
INodeFile继承自INode,表示文件节点。 包含的主要属性如下:
//该文件中包含的所有Block,这些对象并不包含实际的文件block内容,主要的属性为blocks,后续通过blockID和时间戳信息可以找到这些Block存在哪台datanode机器上,客户端直接与该datanode建立链接,请求这个BockID对应的Block中具体文件内容数据(后续再讲,该字段为关键字段)
protected BlockInfo blocks[] = null;
//block的复制个数
protected short blockReplication;
//缺省block大小
protected long preferredBlockSize;
INodeDirectory
INodeDirectory同样继承自INode,表示文件目录节点,主要包含的属性如下:
//该文件目录下所有的子节点信息
private List<INode> children;
Block
public class Block implements Writable, Comparable<Block>
Block本身是一个抽象概念,就表示HDFS中一个最小存储单元,其主要包含的属性如下:
//BlockID标识
private long blockId;
//这个Block包含多少字节数据
private long numBytes;
//一个时间戳,表示Block的版本
private long generationStamp;
注:这个Block对象只是一个抽象的概念(你可以理解为一个数据块的标识,一个存储单元的标识),这个对象并不包含实际Block数据。
Block信息的读取就是client通过网络传递一个序列化的block对象到DataNode,DataNode在本机中的读取这个Block对应的存储文件,返回给客户端。
Block是一个实现了Writable, Comparable<Block>的对象。说明Block对象可以进行序列化并通过网络进行传输,DataNode也可以通过HashMap的方式将Block与实际的存储文件进行对应关联。
BlockInfo
BlockInfo继承自Block,其包含的主要属性如下:
//该Block所属的文件
private INodeFile inode;
/**
* This array contains triplets of references.
* For each i-th data-node the block belongs to
* triplets[3*i] is the reference to the DatanodeDescriptor
* and triplets[3*i+1] and triplets[3*i+2] are references
* to the previous and the next blocks, respectively, in the
* list of blocks belonging to this data-node.
*/
private Object[] triplets
triplets是一个关键字段。
通过triplets[3*i+1] 和 triplets[3*i+2]可以得到某台datanode机器上所有的block列表,triplets[3*i+1] 和triplets[3*i+2]为BlockInfo类型对象。
该项功能主要应用在DatanodeDescriptor实例的
private volatile BlockInfo blockList = null 这个字段中。
通过triplets[3*i]可以得到这个Block其他副本的所属datanode的位置,triplets[3*i]为DatanodeDescriptor类型对象
抓住BlockInfo就抓住了整个HDFS按Block进行文件分布式存储的关键。
BlockInfo信息中不仅包括了一个Block都存储在哪些DataNode上,还包含了某个具体datanode上存储的所有Block信息,以及该block属于哪一个INodeFile。用户需要读取文件时首先通过INodeFile得到这个文件所有的Block---INodeFile中的 BlockInfo[] getBlocks() 方法。通过BlockInfo又可以得到Block存储的DataNodeInfo列表。 用户就可以向得到的DataNode列表的机器发送读取Block具体数据的请求(这部分具体实现后面再讲)。
在系统运行过程中,上述关键对象主要存储在内存中,也就是说HDFS的Namenode有一个内存镜像,其中的内容就是以上对象组成的树形结构,也许有人会问,如果Namenode当机会出现什么问题呢?这个问题问得好:)(具体的解决办法后续会详细讲解,目前先提一下)
HDFS为了能够保证数据安全性,完整性,采用和数据库一样的容灾机制,记录数据操作行为日志:对应的功能对象为FSEditLog 。
系统定时将内存中的文件系统结构镜像序列化到磁盘(FsImage),并删除当前的EditLog 。 如果系统机器重启,Namenode会从镜像文件中读取目录结构信息,同时执行EditLog中记录的操作,用以恢复最新的内存镜像。
FSDirectory
FSdirectory的一个主要作用是就是上述所说的从镜像文件中读取目录结构信息,同时执行EditLog中记录的操作,用以恢复最新的内存镜像。
FSdirectory另一个主要作用就是操作INodeDirectory,INodeFile对象,对文件系统的目录,文件以及文件包含的Block进行操作。FSdirectory有一个关键属性:rootDir,这个对象是整个文件系统的根目录。
该对象涉及的主要方法如下:
void loadFSImage(Collection<File> dataDirs, Collection<File> editsDirs,StartupOption startOpt) throws IOException
boolean mkdirs(String src, PermissionStatus permissions,
boolean inheritPermission, long now)
Block addBlock(String path, INode[] inodes, Block block) throws IOException
private <T extends INode> T addChild(INode[] pathComponents, int pos,T child, long childDiskspace, boolean inheritPermission)
throws QuotaExceededException
INodeFileUnderConstruction
这个类继承自INodeFile,它的实例代表一个正在处于写入状态的文件,新文件的创建和文件的追加(文件追加目前HDFS支持不是很好)时都会使用到这个对象,INode有一个方法 boolean isUnderConstruction(),如果这个方法返回true,表示这个对象目前处于写入状态,可以将这个对象引用转化为INodeFileUnderConstruction。
当文件处于isUnderConstruction状态时,往往就和文件租约产生关联,因为文件的写入操作都会首先实现申请一个租约(租约有专门一章进行讲解),从FSNameSystem的startFileInternal()方法中的部分逻辑代码可以看出端倪。
//首先判断文件是否存在,并且处于文件写入状态
if (myFile != null && myFile.isUnderConstruction())
{
//转换文件为INodeFileUnderConstruction类型
INodeFileUnderConstruction pendingFile =
(INodeFileUnderConstruction) myFile;
// If the file is under construction , then it must be in our
// leases. Find the appropriate lease record.
//如果文件处于写入状态一定有租约与之对应
Lease lease =
leaseManager.getLease(new StringBytesWritable( holder));
下面我们分析一下INodeFileUnderConstruction的关键属性以及方法
INodeFile这个对象仅仅表示一个文件节点,它的大部分属性都是与BlockInfo相关的。
而INodeFileUnderConstruction就会有一些文件创建以及追加时必要的信息,,详细如下:
//这个属性表示当前文件的租约属主是哪次应用
StringBytesWritable clientName = null; // lease holder
StringBytesWritable clientMachine = null;
//client很可能也是datanode其中之一
DatanodeDescriptor clientNode = null; // if client is a cluster node too.
//这个属性主要应用于block的recover操作(该操作后续会详细描述)
private int primaryNodeIndex = -1; // the node working on lease recovery
//文件最后一个block需要写入的机器,这是很重要的属性,也是显而易见的,文件的追加写入一定是对最后一个Block进行操作
private DatanodeDescriptor[] targets = null; // locations for last block
private long lastRecoveryTime = 0;
下面看一个很重要的方法,这个方法后续会详细描述。
void assignPrimaryDatanode()
当文件写入过程中,很可能在某些datanode上写入失败,这就需要对block进行recover操作,而恢复操作中的主节点就是那些写入正常的datanode。
上文已经提到,HDFS中存储数据的最小单位是BLOCK,一个文件对应的所有BLOCK全部按照一定的部署策略存在于DataNode上;我们也提到namenode负责存储文件系统的元数据信息(文件目录结构,以及文件包含的所有block). 当client用户请求读取某个文件时,client首先通过RPC的方式调用NameNode上的服务模块,得到一个文件包含的所有BLOCK列表,以及这些Block所在的Datanode信息。 随后client与相应的Datanode建立链接,发送读取BLOCK的请求。
那么Namenode如何知道文件的block部署在哪台datanode上,以及它是如何管理这些信息的?
上文已经提到过几个关键类:
1.Block,BlockInfo,DataNodeID,DataNodeInfo,DataNodeDescriptor,BlockMap(重点)
Block和BlockInfo两个类前面已经有详细的说明,这里不再赘述。不过再次提醒一点,BlockInfo中有个非常关键的属性就是:triplets。
他主要负责两个功能。
1.双向链表
triplets[3*i+1] 和 triplets[3*i+2] 存储BlockInfo类型对象
这两个字段主要存储某一台DataNode机器上所有的Block列表。
2.链表
triplets[3*i] 存储DataNodeDescriptor类型的对象。
这个字段主要存储这个Block都存储在那些DataNode上。
注:这两个功能没有太大的直接联系,不要混淆。
首先了解一下几个重点类:
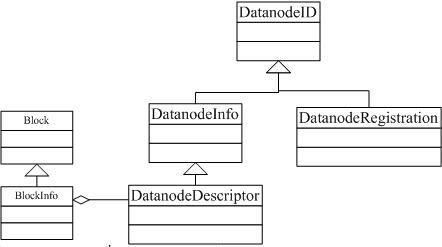
DatanodeID
public class DatanodeID
implements WritableComparable<DatanodeID>
这个类可以完全标识一个DataNode,先看一下这个类的关键字段
public String name; /// hostname:portNumber
public String storageID; //unique per cluster storageID
protected int infoPort;//the port where the infoserver is running
public int ipcPort;// the port where the ipc server is running
name直接由两个关键组成:hostname:portNumber
StorageID:表示datanode的存储ID(这部分的相关功能我们后续进行介绍)
infoPort:InfoServer所监听的端口
ipcPort:IPC服务所监听的端口
这个类包含了一个Server服务的所有网络相关信息。
DatanodeInfo
/**
* DatanodeInfo represents the status of a DataNode.
* This object is used for communication in the
* Datanode Protocol and the Client Protocol.
* 同时这个类也存储DataNode本身在网络环境的节点信息。
*/
public class DatanodeInfo extends DatanodeID implements Node
该类的关键字段:
protected long capacity;
protected long dfsUsed;
protected long remaining;
protected long lastUpdate;
protected int xceiverCount;
protected String location = NetworkTopology.DEFAULT_RACK;
另外该对象还包行两个关键字段
private int level; //which level of the tree the node resides
private Node parent; //its parent
这两个字段表示该datanode节点在网络拓扑架构中的相对位置信息。
这些字段都可以直接从字面上了解其实现的作用。
DatanodeDescriptor
public class DatanodeDescriptor extends DatanodeInfo
这个类相对来说就比较复杂一些,这个类的实例存在于Namenode Server上,保存很多实时信息,该对象包含很重要的几个。
这个类包含三个重要的内部类。
BlockIterator
BlockTargetPair
BlockQueue
BlockIterator:这个类从命名中就可以了解到,他主要的作用是对这个DataNode上所有的Block信息进行遍历,可想而知整个遍历过程借助的就是DatanodeDescriptor的private volatile BlockInfo blockList = null 这个字段, BlockInfo中的triplets[3*i+1] 和 triplets[3*i+2]。
遍历的流程如下:
首先设置迭代器中current对象为DatanodeDescriptor 中的 blockList。利用current.findDatanode(this)方法得到DatanodeDescriptor在blockInfo中 triplets数组的索引位置index,最后利用triplets[index*3+2]得到这个datanode的下一个BlockInfo,并将这个BlockInfo保存为current。
BlockTargetPair:这个类主要保存一个Block和一组DatanodeDescriptor信息。主要为了方便其他模块儿在这组datanode上进行对该Block的操作。
BlockQueue:这个类实质就是一个BlockTargetPair对象的队列。
关于这个类的详细应用我们后续进行讨论,本次主要目的就是了解block如何与datanode节点建立对应关系。
BlockMap
public class BlocksMap
下面介绍我们本节的重头戏:BlockMap,这个类虽然简单但是非常重要,它几乎贯穿于整个HDFS架构,这个类主要是对BlockInfo操作的封装。
我们看到BlockMap有两个内部类,一个就是我们先前介绍过的BlockInfo,另一个就是NodeIterator。
BlockInfo这里不在赘述。
public static class BlockInfo extends Block
NodeIterator
private static class NodeIterator implements Iterator<DatanodeDescriptor>
这个类主要作用是对某个具体block所在的所有DataNode节点信息进行遍历,其主要实现就是通过BlockInfo中的triplets[3*i] 。这部分代码比较简单,这里就不详细进行分析了。
下面看一些重要的方法。
1.
BlockInfo addINode(Block b, INodeFile iNode)
{
BlockInfo info = checkBlockInfo(b, iNode.getReplication());
info.inode = iNode;
return info;
}
这个函数主要应用在用户对新建的文件进行写操作时,Namenode需要新创建一个block来标识用户写入的数据(对应于Datanode上一个具体的block文件),一个block写满时(一般为64M),又会新建一个block标识后续用户写入的数据。这些新建的block需要添加到INodeFile中的BlockInfo数组。
loadFSImage(),这个方法同样需要进行这个函数的调用,将文件系统的元数据信息从文件镜像恢复到内存镜像。
2.
/**
* Add BlockInfo if mapping does not exist.
*/
private BlockInfo checkBlockInfo(Block b, int replication)
{
BlockInfo info = map.get(b);
if (info == null)
{
info = new BlockInfo(b, replication);
map.put(info, info);
}
return info;
}
这个方法的只要目的就是建立block到blockinfo的映射关系,往往通过网络进行RPC调用时一些参数是Block类型的。例如datanode启动时上报所有的block给namenode。因为blockinfo这个对象只是存在于Namenode Server上的。
3.
/** Returns the block object it it exists in the map. */
BlockInfo getStoredBlock(Block b)
{
return map.get(b);
}
通过一个block对象,返回Namenode上与之对应的blockinfo对象。
4.
Iterator<DatanodeDescriptor> nodeIterator(Block b)
{
return new NodeIterator(map.get(b));
}
返回上述提到的一个DatanodeDescriptor迭代器,遍历存储同一个block的所有datanode信息。
这个函数主要是应用于用户通过client对HDFS中的文件进行读取的过程,Namenode会返回一系列包含block以及datanodeinfo[] 的对象。 其中的datanodeinfo数组就是通过这个迭代器获取的所有datanode列表。
5.
/**
* Remove the block from the block map; remove it from all data-node lists
* it belongs to; and remove all data-node locations associated with the
* block.
*/
void removeBlock(BlockInfo blockInfo)
{
if (blockInfo == null)
return;
blockInfo.inode = null;
for (int idx = blockInfo.numNodes() - 1; idx >= 0; idx--)
{
DatanodeDescriptor dn = blockInfo.getDatanode(idx);
dn.removeBlock(blockInfo); // remove from the list and wipe the
// location
}
map.remove(blockInfo); // remove block from the map
}
应用于namesystem.commitBlockSynchronization函数中,调用这个函数的主要原因是系统主动调用recoverBlock方法。
6.
void removeINode(Block b)
{
BlockInfo info = map.get(b);
if (info != null)
{
info.inode = null;
if (info.getDatanode(0) == null)
{ // no datanodes left
map.remove(b); // remove block from the map
}
}
}
该方法主要应用于:用户创建文件后,准备对文件进行写操作,首先需要在namenode添加注册新的block,并添加到INodeFile对象的block数组中,然后与多个datanode尝试创建写block的管道,如果创建失败,就调用该方法将上一步,目的就是删除第一步新注册的block。
同时,该方法还应用于用户删除文件操作。
7.
boolean removeNode(Block b, DatanodeDescriptor node)
{
BlockInfo info = map.get(b);
if (info == null)
return false;
// remove block from the data-node list and the node from the block info
boolean removed = node.removeBlock(info);
if (info.getDatanode(0) == null // no datanodes left
&& info.inode == null)
{ // does not belong to a file
map.remove(b); // remove block from the map
}
return removed;
}
该方法从参数就可以看出,被调用的主要原因就是某一个DataNode节点失效,或者某个DataNode节点的某个具体block失效。
在lease一章我们已经对文件创建流程有了一个大致了解,
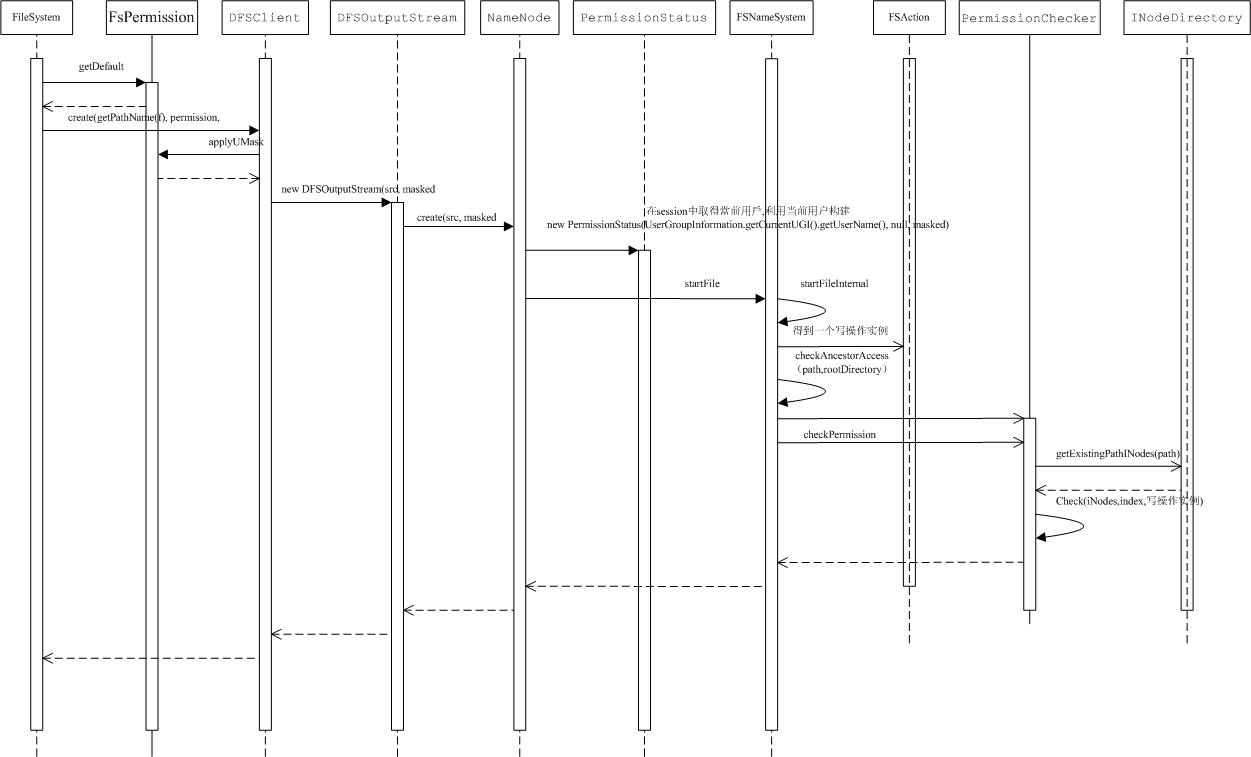
文件的创建主要是通过提供给用户前项层工具抽象类FileSystem,针对于HDFS这个类的具体实现为DistributedFileSystem。
文件夹的创建是一个相对简单的过程,主要是通过FileSystem中的mkdirs()方法,这个方法在DFSClient实例中调用同名方法mkdirs(),通过Hadoop本身的RPC机制调用Namenode的mkdirs()方法,最终这个调用PUSH到FSNameSystem的mkdirsInternal方法,这个方法主要就是检验访问权限,最后通过FSDirectory的unprotectedMkdir()方法,构建一个INodeDirectory实例添加到文件系统的目录树中。
文件节点的创建与添加相对比较麻烦,主要步骤如下:
FileSystem的create方法返回一个很重要的类FSDataOutputStream,这一点也比较好理解,就像java中的文件流一样,创建一个文件写入流对文件内容进行追加,首先我们看文件创建阶段namenode主要做了什么事情(权限验证以及租约验证这些前面都已经有提到,下面的内容就会掠过这一部分)
DfSOutputStream在实例构建时,通过Hadoop本身的RPC机制调用Namenode的create方法,最终这个调用PUSH到FSNameSystem的StartFileInternal方法,需要做权限验证,租约检验等工作,这个方法主要作用就是创建一个INodeFileUnderConstruction实例(上面已经提过,文件写入过程中都会有一个INodeFileUnderConstruction与这个文件对应),这个实例最后通过FSDirectoty的addNode()方法添加到文件系统目录数中,这个时候文件创建操作就算完成了重要的第一步,文件系统中已经有了这个文件的记录。
下面就涉及到文件的写入操作(相当复杂的部分)
这个时候就需要用到返回的DfSOutputStream对象。
这部分太复杂了,我们先分析一些基本模块儿,逐步吃透这部分的实现。
整个分布式文件系统中网络通讯部分分为两类:
1.命令类调用(这部分通过HADOOP的RPC机制进行支持)
2.流式数据传输(这部分通过HADOOP的流式数据传输协议支持)
为了保证数据的正确性,hadoop在多个关键处理单元做了数据检验操作,在流式数据网络传输部分通过校验和保证数据传输正常。
Client在DfSOutputStream对象调用write方法时,系统并不会马上把数据写入SOCKET中,而是逐个构建Package并将这些Package加入一个队列。
在DfSOutputStream对象构建时,系统通过Hadoop本身的RPC机制调用Namenode的create方法后,会启动一个后台线程 streamer.start(); 这个线程的主要目的就是将上述的package队列写入SOCKET中。
我们首先看DfSOutputStream的继承关系

其中FSOutputSummer这个类其实质是一个decorator设计模式的实现,主要的目的就是在OutputStream的void write(byte b[], int off, int len)方法中增加一些功能,上文已经提过,文件数据传输的同时,系统会在传输的数据中增加检验和数据,系统收到数据后对数据进行校验,保证数据传输的正确性,但是用户在对文件输出流进行操作的时候并不需要关注校验和数据,用户只需要不断的调用write方法在目标文件中追加数据。
我们看一下FSOutputSummer中write(byte b[], int off, int len)的实现
public synchronized void write(byte b[], int off, int len)
throws IOException
{
if (off < 0 || len < 0 || off > b.length - len) {
throw new ArrayIndexOutOfBoundsException();
}
for (int n=0;n<len;n+=write1(b, off+n, len-n))
{ }
}
可以看到不断调用write1方法,保证数据发送的完整性。
那么write1方法又做了什么事情呢,write1将用户需要写入的数据流首先写到自己的BUFFER中,达到一定数量(基本是一个chunk的大小)后进行CheckSum方法调用得到一段数据的校验和按照一定格式要求一并写入Stream
private int write1(byte b[], int off, int len) throws IOException {
if(count==0 && len>=buf.length)
{
// local buffer is empty and user data has one chunk
// checksum and output data
final int length = buf.length;
sum.update(b, off, length);
writeChecksumChunk(b, off, length, false);
return length;
}
// copy user data to local buffer
int bytesToCopy = buf.length-count;
bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy;
sum.update(b, off, bytesToCopy);
System.arraycopy(b, off, buf, count, bytesToCopy);
count += bytesToCopy;
if (count == buf.length)
{
// local buffer is full
flushBuffer();
}
return bytesToCopy;
}
sum是什么咚咚呢? new CRC32(),通过这个对象得到校验和
从代码中可以清楚的看到,用户不断往outputstream中追加数据,这些数据会首先存到一个buffer中,等用户写入的数据达到一定数量(基本是一个chunk的大小)后就会对这段数据取校验和,然后通过writeChecksumChunk这个方法将数据以及该部分数据的校验和,按照一定格式一并写入到SOCKET。
接下来我们一起看一下writeChecksumChunk()这个方法
private void writeChecksumChunk(byte b[], int off, int len, boolean keep) throws IOException
{
int tempChecksum = (int) sum.getValue();
if (!keep)
{
sum.reset();
}
int2byte(tempChecksum, checksum);
writeChunk(b, off, len, checksum);
}
这个方法的主要作用就是将用户写入的数据以及该部分数据的校验和做为参数调用writeChunk()方法,这个方法是一个虚方法,真正的实现在DFSOutputStream这个类中,这也合情合理,本身FSOutputSummer这个类的作用仅仅是在输出流中增加校验和数据,至于数据是如何进行传输的是通过DFSOutputStream来实现的。
那么接下来需要说明的就是DFSOutputStream的writeChunk这个方法了。
HDFS流式数据网络传输的基本单位有哪些呢?
chunk->package->block
我们上文已经提过:等用户写入的数据达到一定数量(基本是一个chunk的大小)后就会对这段数据取校验和。
一定数量的chunk就会组成一个package,这个package就是最终进行网络传输的基本单元,datanode收到package后,将这些package组合起来最终得到一个block。
我们接下来通过实际主要的代码了解这部分功能的实现:
currentPacket这个对象初始化的时候就是null,第一次写入数据时这个判断成立
if (currentPacket == null)
{
currentPacket = new Packet(packetSize, chunksPerPacket,
bytesCurBlock);
...
//下面开始构建package包。
//在package包中增加一个chunk,首先添加这个chunk所包含数据的checksum
currentPacket.writeChecksum(checksum, 0, cklen);
//然后添加这个chunk所包含的数据
currentPacket.writeData(b, offset, len);
//增加这个package所包含的chunk个数
currentPacket.numChunks++;
//当前已经写入的byte个数
bytesCurBlock += len;
// If packet is full, enqueue it for transmission
//如果这个package已经达到一定的chunk数量,准备实际的传输操作
if (currentPacket.numChunks == currentPacket.maxChunks
|| bytesCurBlock == blockSize)
{
......
//如果用户写入的数据,已经达到一个block缺省大小(64M)
if (bytesCurBlock == blockSize)
{
//设置当前的package是某一个block的最后一个package
currentPacket.lastPacketInBlock = true;
//清除一些变量的值
bytesCurBlock = 0;
lastFlushOffset = -1;
}
//这三段代码是关键的一部分代码,将已经构建完成的package写入一个dataQueue队列,由另一个线程(就是我们开始提到的:启动一个后台线程 streamer.start(); 这个线程的主要目的就是将上述的package队列写入SOCKET中)从该队列中不断取出package,进行实际的网络传输
dataQueue.addLast(currentPacket);
//产生event,进而通知并唤醒等待线程
dataQueue.notifyAll();
//这一步也很重要,设置currentPacket 为空,表示这个package已经满了,需要new一个新的package继续接收用户后面进一步需要写入的数据。
currentPacket = null;
// If this was the first write after reopening a file, then
// the above write filled up any partial chunk. Tell the summer to generate full
// crc chunks from now on.
if (appendChunk)
{
appendChunk = false;
resetChecksumChunk(bytesPerChecksum);
}
int psize = Math.min((int) (blockSize - bytesCurBlock),
writePacketSize);
computePacketChunkSize(psize, bytesPerChecksum);
}
computePacketChunkSize这个方法的主要作用是计算两个参数:
1.chunksPerPacket
接下来的package需要承载多少个chunk;因为最后一个package承载的chunk个数与文件大小也有关系。
2.packetSize
接下来的package的大小。
以上两个参数与判断是否需要new一个新的PACKAGE很有关系。
private void computePacketChunkSize(int psize, int csize)
{
int chunkSize = csize + checksum.getChecksumSize();
int n = DataNode.PKT_HEADER_LEN + SIZE_OF_INTEGER;
chunksPerPacket = Math.max((psize - n + chunkSize - 1) /
chunkSize,1);
packetSize = n + chunkSize * chunksPerPacket;
if (LOG.isDebugEnabled())
}
可以看到构建的package不断添加到dataQueue这个队列,streamer.start()这个线程从中弹出package进行实际网络传输操作。
下面就涉及到比较复杂的网络传输协议部分。
我们先看一下这部分的流程:
1.上面已经讲过,开始的一步就是客户端调用create方法,在namenode上的目录树中注册一个INodeFileUnderConstruction节点,并得到一个DfSOutputStream。
2.用户得到这个outputStream后就可以进行写入操作,用户写入的数据就不断构建成package写入dataQueue这个队列。
3.streamer.start()这个线程从dataQueue队列中取出package进行实际网络传输操作。
下面的网络传输流程为关键流程:
4.streamer是一个DataStreamer的实例,这是一个线程实例。大家知道HDFS中的文件数据会分成很多64M大小的block,所以在HDFS中保存文件数据第一步就是在namenode上申请一个特殊的blockID(当然还是通过RPC调用的方式)。

文件写入流程

形成的数据传输链路

链路中某一节点的前后链路
DataStreamer线程实现类最重要的方法:
public void run()
{
....//以上代码略
Packet one = null;
synchronized (dataQueue)
{
// process IO errors if any
boolean doSleep = processDatanodeError(hasError, false);
// wait for a packet to be sent.
while ((!closed && !hasError && clientRunning && dataQueue
.size() == 0) || doSleep)
{
try
{
dataQueue.wait(1000);
}
catch (InterruptedException e)
{}
doSleep = false;
}
if (closed || hasError || dataQueue.size() == 0
|| !clientRunning)
{
continue;
}
try
{
// get packet to be sent.
//从dataQueue取出package准备进行发送
one = dataQueue.getFirst();
long offsetInBlock = one.offsetInBlock;
// get new block from namenode.
if (blockStream == null)
{
LOG.debug("Allocating new block");
//这个方法很重要,后面需要详细讲述,主要的操作包含,通过RPC调用在namenode中申请新的block,以及这个block的所有副本需要保存在哪些datanode上(主要就是一个LocatedBlock对象),并建立数据传输链路。
nodes = nextBlockOutputStream(src);
this.setName("DataStreamer for file " + src
+ " block " + block);
response = new ResponseProcessor(nodes);
response.start();
}
//将用户写入的数据包括校验和信息数据通过建立的网络传输链路传输出去
blockStream.write(buf.array(), buf.position(), buf
.remaining());
//...以下代码省略
}
}
}
这里面我们首先看一下LocatedBlock这个类实现
public class LocatedBlock implements Writable
{
//...以上代码省略
//在namenode上申请的新的block
private Block b;
//这个block针对于文件的偏移量
private long offset;
//这个block的副本都存在那些datanode节点上
private DatanodeInfo[] locs;
//...以下代码省略
}
有了LocatedBlock对象的实例,client就可以与datanode节点建立传输数据的链路,上传这个block对应的真正文件数据。
关于文件上传协议细节我们会在3.2.1章节进行讨论
数据文件真正存储的地方是在datanode,当用户需要填充文件中某一个block的实际数据内容时,就需要连接到datanode进行实际的block写入操作,下面我们看一下datanode如何管理block,以及如何存储block。
Datanode是通过文件存储block数据的,datanode中有一个FSDatasetInterface接口,这个接口的主要作用就是对block对应的实际数据文件进行操作。
首先我们看一下这部分涉及的主要类关系:
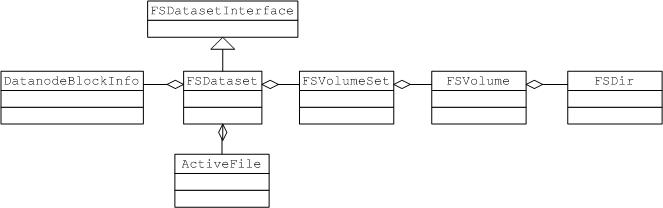
FSDataset实现了接口FSDatasetInterface,主要承载block对应的文件操作。
FSDataset有几个重要的属性:
FSVolumeSet volumes;
private HashMap<Block, ActiveFile> ongoingCreates = new HashMap<Block, ActiveFile>();
private HashMap<Block, DatanodeBlockInfo> volumeMap = null;
Datanode可以配置多个目录来存储block对应的文件,配置的每一个目录就对应一个FSVolume,每一个FSVolume对应的目录中会有一个current目录,这个目录进行实际文件存放,同时系统会在这个目录下自行创建很多子文件夹(每个文件夹存放的文件个数是有限制的)。每个子文件夹就会对应一个FSDir对象。
我么先看一个FSVolume对应目录的文件结构:

/data1/dfs/data/这个目录是我们配置的一个存储block对应的文件的目录,也就是对应一个FSVolume,其中current目录是我们真正存放block数据块文件的地方,其中还有一个tmp目录,这个目录主要临时存放一些正在写入的block数据文件,成功写入完成后这个临时文件就会从tmp目录移动到current目录。
看一下我们的配置文件内容
可以看到我们配置了/data1/dfs/data/目录做为我们数据存储目录之一。
下面我们看一下实际的/data1/dfs/data/current目录下会有那些内容:
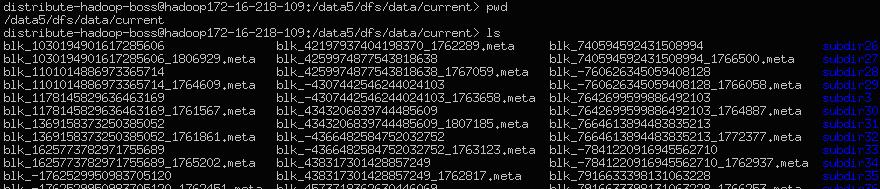
可以看到这个目录主要存放了block数据文件,block数据文件的命名规则是blk_$BLOCKID$,还有就是block文件的元数据文件,元数据文件的命名规则是:blk_$BLOCKID$_$时间戳$,同时大家可以看到很多累似subdir00命名的文件夹,这些文件夹其中存放的也是block数据文件及其元数据文件,hadoop规定每个目录存放的block数据文件个数是有限制的,达到限制之后就会新建sub子目录进行存放,这些sub子目录包括current目录,都会和一个FSDir对象对应。
我们来看一下FSDir对象,这个对象和文件系统中的目录是很相近的概念,他的主要作用就是管理一个目录下的所有与block相关的文件。
我们先看一个这个类的主要属性:
//这个对象对应的文件目录对象。
File dir;
//这个目录下的子文件夹对象
FSDir children[];
这个对象在进行实例化构造的过程就会遍历文件夹下的文件,判断哪些是目录,然后生成相应的FSDir添加到children数组中。
主要方法:
void getVolumeMap(HashMap<Block, DatanodeBlockInfo> volumeMap,
FSVolume volume)
这个方法的主要目的就是遍历整个目录,得到所有block文件列表,并添加所有block的记录到FSDataset的volumeMap属性中,参数中的volumeMap传入的正是FSDataset的volumeMap属性,这个对象保存block与DatanodeBlockInfo的映射关系,便于通过block查询具体的block文件信息。
datanodeBlockInfo对象主要保存了block属于哪一个FSVolume,以及block块实际的存放文件是哪个。
{
if (children != null)
{
for (int i = 0; i < children.length; i++)
{
//遍历子文件夹
children[i].getVolumeMap(volumeMap, volume);
}
}
File blockFiles[] = dir.listFiles();
for (int i = 0; i < blockFiles.length; i++)
{
//判断文件是否是一个block,主要是通过文件名来判断的,block的文件名的命名特征是"blk_$BLOCKID"
if (Block.isBlockFilename(blockFiles[i]))
{
long genStamp = getGenerationStampFromFile(blockFiles,
blockFiles[i]);
volumeMap.put(new Block(blockFiles[i], blockFiles[i]
.length(), genStamp), new DatanodeBlockInfo(volume,blockFiles[i]));
}
}
}
Volumes相对来说比较简单,他就是一个FSVolume集合,并封装了对所有volume的操作,比如:getBlockReport()这个方法,就是得到所有的block列表,上报给namenode。有了volumes这个集合对象,类似这样的操作就可以封装起来,方便后续操作。
ongoingCreates
这个对象主要存储了正在创建的block列表,这个对象中的block表示用户正在进行该block文件数据上传操作,这个对象中包含ActiveFile对象的实例,我们先看一下ActiveFile对象,这个对象中有两个关键属性:1.对象对应的数据文件。2.正在操作这个文件的线程列表。
final File file;
final List<Thread> threads = new ArrayList<Thread>(2);
保存线程列表的主要目的是:
在进行block文件写入操作时,如果datanode收到了对这个block进行recoverblock的请求后,需要先interrupt所有正在写入这个block文件的线程。
我们先看一下文件数据的接受流程。
在接下来的3.2.2章节我们会详细介绍datanode接收数据的协议,下文中会提到Datanode构建一个BlockReceiver实例,进行实际数据的接受操作。
BlockReceiver在构建实例过程中会首先通过如下方法:streams = datanode.data.writeToBlock(block, isRecovery);打开block数据写入datanode本地文件的通道,以便datanode接收到block数据块儿内容以后将数据内容写入磁盘。第一步我们可能需要了解BlockWriteStreams这个对象,因为writeToBlock会返回BlockWriteStreams对象实例。
static class BlockWriteStreams
{
OutputStream dataOut;
OutputStream checksumOut;
BlockWriteStreams(OutputStream dOut, OutputStream cOut) {
dataOut = dOut;
checksumOut = cOut;
}
我们可以看到这个对象包含两个重要的属性:dataOut,checksumOut。从字面意思我们也可以揣测到,这两个outputstream对象,一个用来写入block数据,一个用来写入block数据中的checksum数据。
接下来我们详细分析一下这个方法:
public BlockWriteStreams writeToBlock(Block b, boolean isRecovery)
{
...
//前面主要做一些合法性判断。
...
if (!isRecovery)
{
v = volumes.getNextVolume(blockSize);
//这是很重要的方法,主要是先创建一个临时文件存储上传的数据,等一个完成的block文件写入完成以后,再将这个文件以及元数据文件移动到正式文件目录。
f = createTmpFile(v, b);
volumeMap.put(b, new DatanodeBlockInfo(v));
...
}
...
return createBlockWriteStreams(f, metafile);
}
主要是创建一个临时文件和一个存放元数据信息的临时文件,然后打开两个文件将返回的OutputStream返回给前端。
文件读取相对文件写入要简单的多得多,client首先需要从namenode得到一个文件的block列表以及每个block的一个副本所在的datanode,随后client逐个和这些datanode建立链接发送读取block数据的请求(过程比较简单,我们看一下这部分涉及的主要对象)
下面是文件读取部分的前半部分流程,主要是从namenode上得到文件对应block的信息。
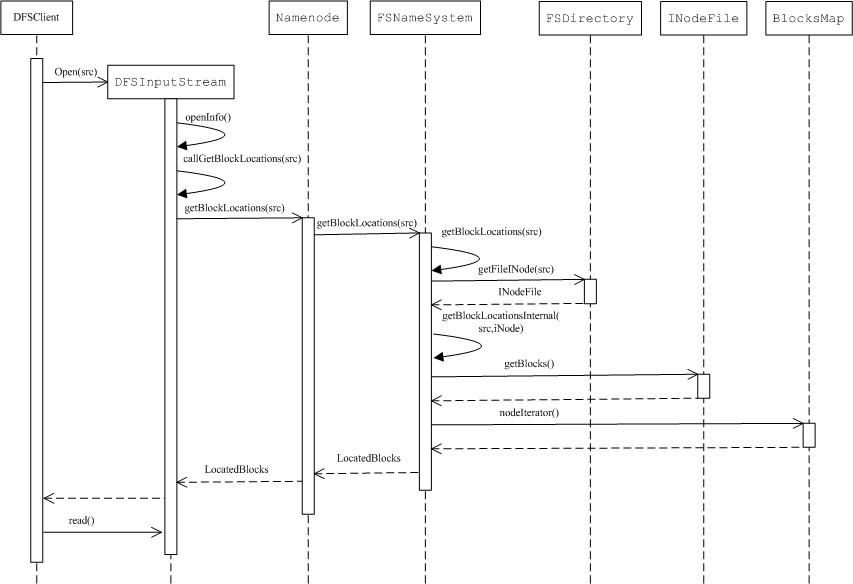
可以看到主要是返回一个LocateBlocks实例给DFSInputStream对象,LocateBlocks对象主要的作用是什么呢?我们首先看一下这个对象的基本属性:
public class LocatedBlocks implements Writable
{
private long fileLength;
private List<LocatedBlock> blocks;
...
}
可以看到这个对象最重要的属性就是List<LocatedBlock> blocks和一个文件长度字段,LocatedBlock上文已经有所提及:有了LocatedBlock对象的实例,client就可以与datanode节点建立传输数据的链路,读取这个block对应的真正文件数据。
下面我们看一下block数据的读取流程,肯定与datanode有关联了,又涉及到文件读取数据流相关协议,协议部分可以参考3.2.3章节。
首先我们看一下文件读取部分涉及到的主要对象:
DFSClient一侧相关对象:

InputStream是JDK中的基础类库的抽象基类,FSInputStream主要增加了三个虚方法的定义:
public abstract void seek(long pos) throws IOException;
public abstract long getPos() throws IOException;
public abstract boolean seekToNewSource(long targetPos) throws IOException;
从上面的调用序列图中可以清晰的看到,DFSClient会首先构建一个DFSInputStream实例,在DFSInputStream构造过程中会调用自身openInfo()方法完成环境的初始化操作,主要是从Namenode通过RPC调用得到文件的block列表信息,对应与LocatedBlocks的一个具体实例。
接下来我们就看一下DFSInputStream类的read方法,读取数据的操作主要依赖于从namenode返回的LocatedBlocks实例。
public synchronized int read(byte buf[], int off, int len)
throws IOException
{
...
//首先做一些检查工作
...
if (pos < getFileLength())
{
int retries = 2;
while (retries > 0)
{
try
{
//这句语句是非常重要的步骤,判断现在读取的位置是否已经到了目前正在操作的block数据块儿的结束位置,如果已经完成了一个block数据块儿的读取操作,就需要重新定位到下一了block,需要与下一了block所在的datanode建立链接,发送读取数据的请求。
if (pos > blockEnd)
{
currentNode = blockSeekTo(pos);
}
int realLen = Math.min(len, (int) (blockEnd - pos + 1));
//开始从与datanode建立的SOCKET连接中读取数据。
int result = readBuffer(buf, off, realLen);
if (result >= 0)
{
pos += result;
}
...
}
}
}
}
可以看到read()方法中调用了一个很重要的方法,就是blockSeekTo(pos),我们看一下这个方法的实现:
private synchronized DatanodeInfo blockSeekTo(long target)
throws IOException
{
...
//blockReader是一个封装的对象,主要作用就是从datanode读取block的实体数据,我们下面再讲
if (blockReader != null)
{
//关闭与原来datanode的链接,因为上一个block已经读取完毕了
blockReader.close();
blockReader = null;
}
if (s != null)
{
//关闭与原来datanode的链接,因为上一个block已经读取完毕了
s.close();
s = null;
}
//这个方法就是从LocatedBlocks对象的所有LocatedBlock列表中得到下一个LocatedBlock。
LocatedBlock targetBlock = getBlockAt(target);
//下一个block读取的偏移量(这个应用主要满足于随即读取的需要)
long offsetIntoBlock = target - targetBlock.getStartOffset();
//定位到正确的block,我们还需要找一个合适的datanode进行读取,因为每个block都有多个副本分别存在于多台机器上。
DatanodeInfo chosenNode = null;
while (s == null)
{
//选择一个最合适的datanode
DNAddrPair retval = chooseDataNode(targetBlock);
chosenNode = retval.info;
InetSocketAddress targetAddr = retval.addr;
//发送数据读取协议字段到Datanode,进行实际数据读取操作,具体协议我们在3.2.3章节进行详细阐述。
try
{
s = socketFactory.createSocket();
s.connect(targetAddr, socketTimeout);
s.setSoTimeout(socketTimeout);
Block blk = targetBlock.getBlock();
//构造一个blockreader准备进行实际block数据块的读取
blockReader = BlockReader.newBlockReader(s, src, blk
.getBlockId(), blk.getGenerationStamp(),
offsetIntoBlock, blk.getNumBytes()
- offsetIntoBlock, buffersize,
verifyChecksum, clientName);
return chosenNode;
}
}
}
DFSInputStream在构造的时候会调用自身方法openInfo(),请求namenode得到一个LocatedBlocks对象,保存了所读取文件的LocatedBlock列表,getBlockAt()这个方法从LocatedBlock列表中得到下一个Item,hadoop向namenode请求一个文件的block信息时,并不是一次性取得所有block对应的LocatedBlock,
callGetBlockLocations(namenode, src, offset,prefetchSize);
方法中的prefetchSize参数,表明每次预取一定数量的block信息,等读取完成后再取下一批。
下面就要分析一下BlockReader这个对象了,
blockReader = BlockReader.newBlockReader(s, src, blk.getBlockId(), blk.getGenerationStamp(),offsetIntoBlock, blk.getNumBytes()- offsetIntoBlock, buffersize,verifyChecksum, clientName);
上文有提过下面这个方法,主要就是利用blockReader进行数据读取
//开始从与datanode建立的SOCKET连接中读取数据。
int result = readBuffer(buf, off, realLen);
blockReader继承自FSInputChecker,FSInputChecker的主要目的就是对从datanode读取的数据进行checksum的校验操作,这和我们上面提到的写入block数据的实现方式如出一辙,FSInputChecker其实是一个Decorator的实现方式,在数据读取的过程中插入了数据校验的功能。
private synchronized int readBuffer(byte buf[], int off, int len)
throws IOException
{
IOException ioe;
boolean retryCurrentNode = true;
while (true)
{
try
{
return blockReader.read(buf, off, len);
}
....
boolean sourceFound = false;
//如果对一个Datanode尝试多次读取失败以后,需要从其他的Datanode上进行读取。
if (retryCurrentNode)
{
sourceFound = seekToBlockSource(pos);
}
else
{
addToDeadNodes(currentNode);
sourceFound = seekToNewSource(pos);
}
retryCurrentNode = false;
}
}
接下来我们看一下blockReader.read()方法的实现。
public synchronized int read(byte[] buf, int off, int len)
throws IOException
{
//用户很可能不是从文件头部对文件进行读取,所以针对于定位到的第一个block也应用是很可能有偏移的,还有就是在读取block的过程中出错了,去另一个datanode读取该block剩下的数据。
if (lastChunkLen < 0 && startOffset > firstChunkOffset && len > 0)
{
int toSkip = (int) (startOffset - firstChunkOffset);
if (skipBuf == null)
{
skipBuf = new byte[bytesPerChecksum];
}
//调用FSInputChecker的read方法,这个方法的调用主要是对从datanode读取过来的数据进行校验和操作
if (super.read(skipBuf, 0, toSkip) != toSkip)
{
throw new IOException(
"Could not skip required number of bytes");
}
}
boolean eosBefore = gotEOS;
int nRead = super.read(buf, off, len);
}
下面我们就看一下FSInputChecker.read()方法的实现
public synchronized int read(byte[] b, int off, int len) throws IOException
{
...//一些参数检查工作
int n = 0;
for (;;)
{
int nread = read1(b, off + n, len - n);
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
if (n >= len)
return n;
}
}
核心功能还是在read1()方法中实现
private int read1(byte b[], int off, int len) throws IOException
{
int avail = count - pos;
if (avail <= 0)
{
//如果用户自己提供的buffer足够存储读取的数据,那直接写入用户的buffer中
if (len >= buf.length)
{
//从网络数据流中读取一个chunk单位的数据,并加以checksum验证
int nread = readChecksumChunk(b, off, len);
return nread;
}
else
{
//首先写入系统BUFFER中,完成后拷贝到用户提供的buffer中。
fill();
if (count <= 0)
{
return -1;
}
else
{
avail = count;
}
}
}
int cnt = (avail < len) ? avail : len;
System.arraycopy(buf, pos, b, off, cnt);
pos += cnt;
return cnt;
}
readChecksumChunk会调用readChunk()方法,这个方法主要的实现在BlockReader代码中,FSInputChecker目的仅仅是对读取的数据和相应的校验数据进行校验,BlockReader进行实际数据读取操作,主要就是根据hadoop数据流传输协议对数据进行解析;
FileSystem是一个提供给用户对文件系统进行访问的抽象类,访问HDFS的具体实现类为DistributedFileSystem,用户对HDFS的所有操作就是通过这个类的具体实例完成的。在HDFS写入文件之前需要首先在Namenode创建并注册一个INodeFileUnderConstruction,在向文件进行数据追加时,会针对这一文件逐个向系统中追加BLOCK,如果是第一次写入(或者上一个BLOCK已经写满),需要在Namenode中注册一个新的BLOCK,通过RPC调用Namenode的具体实例返回LocatedBlock对象,除了新申请的block这个LocatedBlock对象还包含多个datanodeinfo信息,表示这个block块儿需要传输的哪些datanode上进行保存。
下面我们详细看一下数据传输的具体流程以及传输协议的详细内容:
第一步将返回的多个datanode逐个建立链接形成数据传输链,如下图所示(以三份数据拷贝为例):
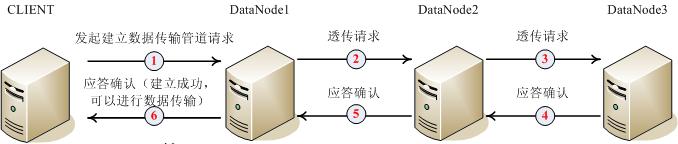
当流程到达第6步的时候这个管道才算建立成功,每一步都是与下一个节点建立链接,发送管道创建协议包。
下面我们看一下管道建立协议:
| 4字节 | 数据传输协议版本号(0.19.1版本的hadoop这个字段为14) | |
| 4字节 | 操作码(追加文件时为:OP_WRITE_BLOCK) | |
| 8字节 | Block的BLOCKID字段 | |
| 8字节 | Block的时间戳字段 | |
| 4字节 | 建立的传输链中一共有多少台datanode | |
| boolean | 表示是否为恢复数据请求(recoverblock操作) | |
| Text | Client名称字串,格式为字串长度(这个采取了压缩形式)+字串内容 | |
| boolean | 表示是否传输客户端信息 | |
| DatanodeInfo | 如果上面字段为true,才会有该字段,表示client信息 | |
| int | 表示数据链中后续节点个数(每过一个节点,这个字段就减少一) | |
| DatanodeInfo[] | 表示数据链中后续节点信息,上面字节是多少就读多少个DatanodeInfo信息,传给后面的节点做下一节点的链接 | |
| Checksum | byte | Checksum的类型,可以根据该字段实例化具体checksum类 |
| int | 对多少字节进行取checksum操作 | |
Client发出上面的请求后就等待应答,应答的协议格式如下:
| Text | Client名称字串,格式为字串长度(这个采取了压缩形式)+字串内容 |
返回就是一个字串信息,如果字串为空表示后续节点所有链路都链接成功,如果不为空该字段保存的就是出错的datanode信息,格式如下:name:port。
针对于一个block传输操作创建数据链路成功以后,就可以进行实际数据传输了。后面的数据就是一个接一个的Package包。
| 4字节 | Package数据长度 |
| 4字节 | package在这个block中的偏移量 |
| 8字节 | 一个序列号 |
| byte | 这个package是否是这个block中最后一个包 |
| 4字节 | 实际的数据长度,除去checksum。 |
| CheckSum数据 | 缺省的CheckSum为CRC32,(缺省每个chunk的checksum占四个字节) |
| 实际block数据 | 有多少写多少 |
数据传输过程中一定需要耗时,如何知道数据传输链中的datanode都是正常工作的呢?以及datanode成功收到package包以后是如何应答吗?这部分协议相关字段如下:
如果收到下一个datanode返回4字节(-1),表示心跳正常
| 4字节 | opCode(-1,表示心跳正常) |
如果收到下一个datanode返回4字节(不等于-1,也不等于-2)
| 4字节 | packageID(向上一级返回接受到的packageID) |
| 4字节 | OP_STATUS_SUCCESS = 0; OP_STATUS_ERROR = 1; 0表示接受成功,1表示接受失败。 这个字节根据数据链中的位置可能会收到多个,详细见下图: |
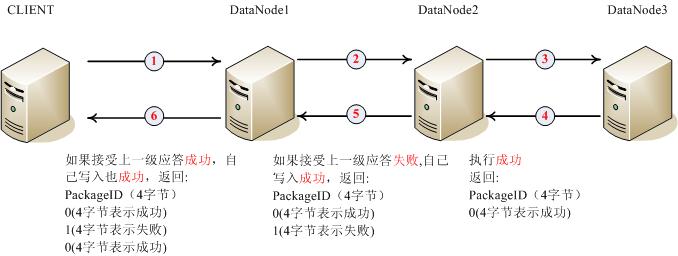
client最终可以根据返回的PackageID后的多个状态字节得知哪台机器可能出现问题,从上面的流程可以看到:datanode3可能已经写入成功,datanode2由于没有收到datanode3的应答,故而认为datanode3接受package失败,这个状态一直透传到client。
也有可能datanode3节点的确失效,datanode2也会收不到datanode3的应答响应。
接下来我们详细介绍一下这个模块儿主要涉及到的模块儿。
DFSClient从Namenode取得需要读取的文件对应的LocatedBlocks信息以后,就会按照block的顺序与datanode建立链接并发送读取block数据的请求。我们看一下这部分的协议格式:
| 4字节 | 数据传输协议版本号(0.19.1版本的hadoop这个字段为14) |
| 4字节 | 操作码(读取文件时为:OP_READ_BLOCK,对应81) |
| 8字节 | Block的BLOCKID字段 |
| 8字节 | Block的时间戳字段 |
| 8字节 | 读取在block数据文件开始的偏移量 |
| 8字节 | 一共读取多少字节 |
| Text | Client名称字串,格式为字串长度(这个采取了压缩形式)+字串内容 |
DFSClient发送读取数据块儿请求完成以后,首先等待datanode的应答,datanode应答协议格式如下:
| 4字节 | OP_STATUS_SUCCESS=0表示链接建立成功OP_STATUS_ERROR=1表示链接建立失败 |
接下来Datanode就开始进行数据传送,具体数据格式如下:
| 数据校验相关信息 | Byte | Chunksum类型 |
| int | bytesPerChecksum每次checksum对应的字节数 | |
| 8字节 (这8字节有些情况是没有的) | Offset(读取一个block开始的偏移量) 1.DFSClient从Datanode读取block数据时,这个字段是必须有的。 2.Datanode之间进行block互相拷贝时(balance需要,或者block块儿没有达到副本个数要求),这个字段是不存在的。 | |
| 4字节 | packetLen,package长度 | |
| 8字节 | chunk的偏移量(用戶读取文件时,很可能偏移一个位置,偏移的位置很可能不在一个chunk的结束位置,因为checksum是按照chunk来计算的,所以hadoop会将这部分偏移量的数据多传送给client,client需要将这部分数据丢弃) | |
| 8字节 | Seqno序列号 | |
| byte | 是否是block数据块的最后一个package | |
| 4字节 | 传输的block中包含的数据大小 | |
| CheckSum数据 | 缺省的CheckSum为CRC32,(缺省每个chunk的checksum占四个字节) | |
| 实际block数据 | 有多少写多少
在3.1.9章节中我们已经详细讲述了Client在需要上传文件时,需要进行的操作以及相关实现模块,这一章节我们着重讲述datanode一侧支持数据传输的重要模块。 DataXceiverServer: datanode在启动以后会首先初始化一个DataXceiverServer对象实例,这个对象是实现了Runnable接口的对象,它附着于一个特定线程监听在特定端口。 public void run() { while (datanode.shouldRun) { try { Socket s = ss.accept(); s.setTcpNoDelay(true); new Daemon(datanode.threadGroup, new DataXceiver(s, datanode, this)).start(); ... }}} 以上代码就是该线程对象的主要运行实体,他仅仅是监听端口处理连接请求,建立好连接以后,就会创建另一个线程处理该链接的请求,这个线程的运行实体为DataXceiver的实例对象,下面我们重点看一下DataXceiver的实现。 DataXceiver也是实现了Runnable接口的类,主要逻辑在run()方法中。
public void run() { DataInputStream in=null; try { in = new DataInputStream( new BufferedInputStream(NetUtils.getInputStream(s), SMALL_BUFFER_SIZE)); //首先读取协议版本号,并进行判断 short version = in.readShort(); if ( version != DataTransferProtocol.DATA_TRANSFER_VERSION ) { throw new IOException( "Version Mismatch" ); } boolean local = s.getInetAddress().equals(s.getLocalAddress()); //读取操作码,追加文件时对应的是OP_WRITE_BLOCK byte op = in.readByte(); ... } //通过用户传过来的操作码,进行相应的操作 long startTime = DataNode.now(); switch ( op ) { case DataTransferProtocol.OP_READ_BLOCK: readBlock( in ); datanode.myMetrics.readBlockOp.inc(DataNode.now() - startTime); if (local) datanode.myMetrics.readsFromLocalClient.inc(); else datanode.myMetrics.readsFromRemoteClient.inc(); break; case DataTransferProtocol.OP_WRITE_BLOCK: writeBlock( in ); datanode.myMetrics.writeBlockOp.inc(DataNode.now() - startTime);
...//省略
default: throw new IOException("Unknown opcode " + op + " in data stream"); } } ... 前面我们一直在讨论文件写入的实现,我们就首先看一下writeBlock( in );其中主要涉及到文件block传输协议关键字段的读取,完成数据传输链路的建立以及block数据块儿的传输。
private void writeBlock(DataInputStream in) throws IOException { DatanodeInfo srcDataNode = null; //读取client传过来的blockID和时间戳,构造一个block。 Block block = new Block(in.readLong(), dataXceiverServer.estimateBlockSize, in.readLong()); //数据传输链路中有多少台机器 int pipelineSize = in.readInt(); //是否是一次数据BLOCK恢复操作 boolean isRecovery = in.readBoolean(); //客户端名称 String client = Text.readString(in); //客户端是否是集群中一台datanode机器 boolean hasSrcDataNode = in.readBoolean(); //如果客户端是集群中一台datanode机器,得到datanodeinfo信息 if (hasSrcDataNode) { srcDataNode = new DatanodeInfo(); srcDataNode.readFields(in); } //表示数据链中后续节点个数(每过一个节点,这个字段就减少一) int numTargets = in.readInt();
... //读取后续节点的详细datanodeinfo信息 DatanodeInfo targets[] = new DatanodeInfo[numTargets]; for (int i = 0; i < targets.length; i++) { DatanodeInfo tmp = new DatanodeInfo(); tmp.readFields(in); targets[i] = tmp; } //生成一个BlockReceiver实例接收客户端传输过来的文件数据内容。 blockReceiver = new BlockReceiver(block, in, s .getRemoteSocketAddress().toString(), s .getLocalSocketAddress().toString(), isRecovery, client,srcDataNode, datanode);
//下面就是根据上面返回的datanode列表,建立数据传输链路 mirrorOut.writeShort(DataTransferProtocol.DATA_TRANSFER_VERSION);mirrorOut.write(DataTransferProtocol.OP_WRITE_BLOCK); mirrorOut.writeLong(block.getBlockId()); mirrorOut.writeLong(block.getGenerationStamp()); mirrorOut.writeInt(pipelineSize); mirrorOut.writeBoolean(isRecovery); Text.writeString(mirrorOut, client); mirrorOut.writeBoolean(hasSrcDataNode); if (hasSrcDataNode) { // pass src node information srcDataNode.write(mirrorOut); } mirrorOut.writeInt(targets.length - 1); for (int i = 1; i < targets.length; i++) { targets[i].write(mirrorOut); }
blockReceiver.writeChecksumHeader(mirrorOut); mirrorOut.flush();
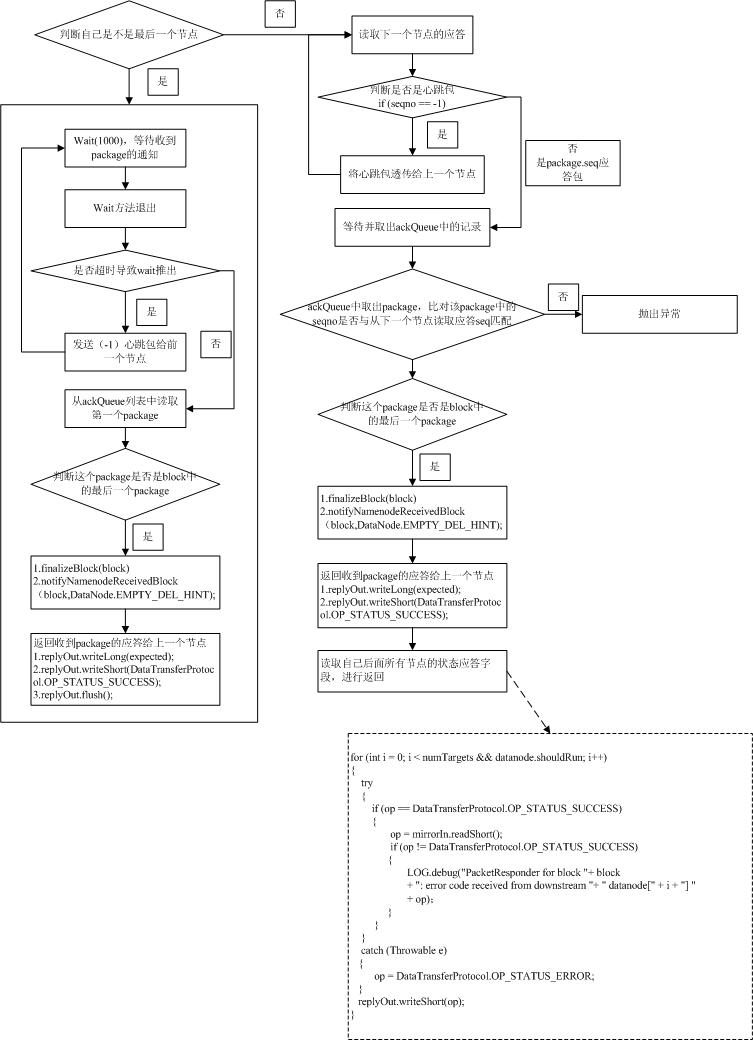
//发送完建立数据传输链的请求后,等待下一个节点的应答,返回空字串表示链路建立成功。 链路建立成功以后,应答给前一个节点,然后就是等待前一个节点发过来的数据,主要的实现是下面的方法。 blockReceiver.receiveBlock(mirrorOut, mirrorIn, replyOut, mirrorAddr, null, targets.length);
该方法中会初始化一个PacketResponder线程,这个线程的主要目的就是发送心跳包给上一个节点,同时接受下一个节点成功收到pachage后的应答,并发送应答信息给前一个节点,如果接受完一个完整的block,还有两个重要的操作要做: 1.datanode.data.finalizeBlock(block);(这部分我们后面再讲,主要是在datanode上完成block文件从tmp目录移动到正式的数据存放目录) 2.datanode.notifyNamenodeReceivedBlock(block,DataNode.EMPTY_DEL_HINT);(这个方法比较简单就是同时namenode自己收到一个block,namenode就可以在blockinfo中加入这个datanodeinfo的信息)
同时调用自身最重要的一个方法:receivePacket(); 这个方法就是根据数据流传输协议,解析package数据包,将用户传来的数据追加到block文件中(当然还有很多数据校验的操作,block和本地文件会有一个映射关系,这部分我们后面介绍),这个方法中比较重要的方法就是readNextPacket(),主要是对ByteBuffer这个对象的灵活应用(详细可以参考代码)。 成功接收完成一个Package后就会做一个比较重要的操作就是: ((PacketResponder) responder.getRunnable()).enqueue(seqno, lastPacketInBlock); 将接收到的package中的seqno构造一个package对象写入一个ackQueue队列,前面提到的PacketResponder线程从该队列中取出seqno应到给上一个节点。 下面我们看一下PacketResponder线程的主要流程:
下面我们共同讨论一下readBlock( in )方法的实现,这个方法主要应用于DFSClient读取block数据块的操作。从前面的协议字段详细描述表已经比较清晰地看出:客户端与datanode建立连接以后版本号验证通过,下面一个协议字段就是opCode,datanode通过这个操作码进行后面的操作,如果是OP_READ_BLOCK(81)表示DFSClient需要进行block数据块读取请求,我们详细分析一下这个方法。
private void readBlock(DataInputStream in) throws IOException { //根据协议解析blockid字段 long blockId = in.readLong(); //再解析时间戳字段构建出block对象 Block block = new Block(blockId, 0, in.readLong()); //读取block时的偏移量,有些时候从一个datanode读取block过程中,datanode当机,这个时候从另一个datanode继续读取该block就要有一个偏移量。 long startOffset = in.readLong(); //需要读取多少字节 long length = in.readLong(); String clientName = Text.readString(in);
OutputStream baseStream = NetUtils.getOutputStream(s, datanode.socketWriteTimeout); DataOutputStream out = new DataOutputStream( new BufferedOutputStream(baseStream, SMALL_BUFFER_SIZE));
BlockSender blockSender = null; try { try { //blockSender对象负责具体的block数据传送工作 blockSender = new BlockSender(block, startOffset, length, true,true, false, datanode, clientTraceFmt); } out.writeShort(DataTransferProtocol.OP_STATUS_SUCCESS); //读取block数据按照协议规则写入out流对象中 long read = blockSender.sendBlock(out, baseStream, null); ... } } 我们看看blockSender在构造的过程中具体做了哪些操作。 { this.blockLength = datanode.data.getLength(block); ... try { if (!corruptChecksumOk || datanode.data.metaFileExists(block)) { //从block的元数据文件中读取信息,主要是checksum类型以及每次做checksum的字节数 checksumIn=new DataInputStream(new BufferedInputStream(datanode.data.getMetaDataInputStream(block) ,BUFFER_SIZE)); BlockMetadataHeader header = BlockMetadataHeader .readHeader(checksumIn); short version = header.getVersion(); ... checksum = header.getChecksum(); } else { //如果没有读到元数据信息,使用缺省的checksum对象 checksum = DataChecksum.newDataChecksum( DataChecksum.CHECKSUM_NULL, 16 * 1024); } ... checksumSize = checksum.getChecksumSize(); ...
// 根据读取block的偏移位置确定偏移checksum数据流的位置 if (offset > 0) { long checksumSkip = (offset / bytesPerChecksum) * checksumSize; if (checksumSkip > 0) { IOUtils.skipFully(checksumIn, checksumSkip); } } seqno = 0; //获得block数据的读取数据流,datanode.data这个对象就是FSDataset对象的实例,后续block的数据发送过程就是从这个对象中读取block数据 blockIn = datanode.data.getBlockInputStream(block, offset); ... } | |

















 4002
4002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









