





Index-Organized Tables
An index-organized table is a table stored in a variation of a B-tree index structure. In a heap-organized table, rows are inserted where they fit. In an index-organized table, rows are stored in an index defined on the primary key for the table. Each index entry in the B-tree also stores the non-key column values. Thus, the index is the data, and the data is the index.Applications manipulate index-organized tables just like heap-organized tables, using SQL statements.
For an analogy of an index-organized table, suppose a human resources manager has a book case of cardboard boxes. Each box is labeled with a number—1, 2, 3, 4, and so on—but the boxes do not sit on the shelves in sequential order. Instead, each box contains a pointer to the shelf location of the next box in the sequence.
Folders containing employee records are stored in each box. The folders are sorted by employee ID. Employee King has ID 100, which is the lowest ID, so his folder is at the bottom of box 1. The folder for employee 101 is on top of 100, 102 is on top of 101, and so on until box 1 is full. The next folder in the sequence is at the bottom of box 2.
In this analogy, ordering folders by employee ID makes it possible to search efficiently for folders without having to maintain a separate index. Suppose a user requests the records for employees 107, 120, and 122. Instead of searching an index in one step and retrieving the folders in a separate step, the manager can search the folders in sequential order and retrieve each folder as found.
Index-organized tables provide faster access to table rows by primary key or a valid prefix of the key. The presence of non-key columns of a row in the leaf block avoids an additional data block I/O. For example, the salary of employee 100 is stored in the index row itself. Also, because rows are stored in primary key order, range access by the primary key or prefix involves minimal block I/Os. Another benefit is the avoidance of the space overhead of a separate primary key index.
Index-organized tables are useful when related pieces of data must be stored together or data must be physically stored in a specific order. This type of table is often used for information retrieval, spatial (see "Overview of Oracle Spatial" on page 19-14), and OLAP applications (see "OLAP" on page 17-20).
Index-Organized Table Characteristics
The database system performs all operations on index-organized tables by manipulating the B-tree index structure. Table 3–4 summarizes the differences between index-organized tables and heap-organized tables.

Figure 3–3 illustrates the structure of an index-organized departments table. The leaf blocks contain the rows of the table, ordered sequentially by primary key. For example, the first value in the first leaf block shows a department ID of 20, department name of Marketing, manager ID of 201, and location ID of 1800.
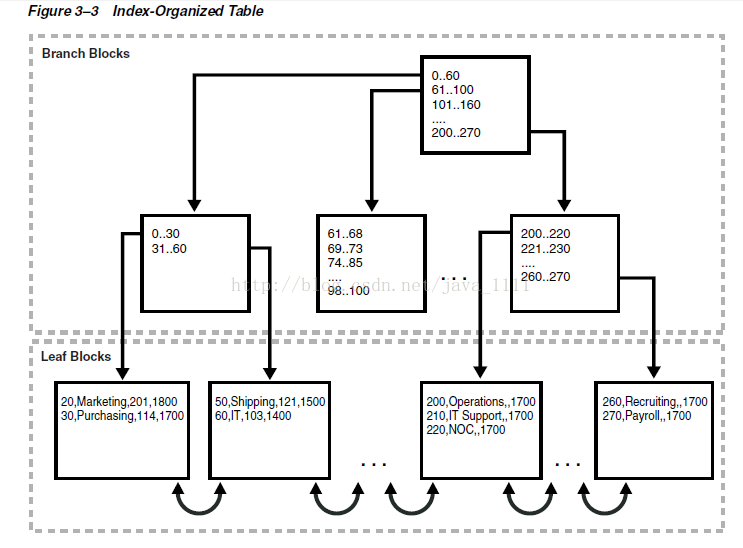
An index-organized table stores all data in the same structure and does not need to store the rowid. As shown in Figure 3–3, leaf block 1 in an index-organized table might contain entries as follows, ordered by primary key:
20,Marketing,201,1800
30,Purchasing,114,1700
Leaf block 2 in an index-organized table might contain entries as follows:
50,Shipping,121,1500
60,IT,103,1400
A scan of the index-organized table rows in primary key order reads the blocks in the following sequence:
1.Block 1
2.Block 2
To contrast data access in a heap-organized table to an index-organized table, suppose block 1 of a heap-organized departments table segment contains rows as follows:
50,Shipping,121,1500
20,Marketing,201,1800
Block 2 contains rows for the same table as follows:
30,Purchasing,114,1700
60,IT,103,1400
A B-tree index leaf block for this heap-organized table contains the following entries, where the first value is the primary key and the second is the rowid:
20,AAAPeXAAFAAAAAyAAD
30,AAAPeXAAFAAAAAyAAA
50,AAAPeXAAFAAAAAyAAC
60,AAAPeXAAFAAAAAyAAB
A scan of the table rows in primary key order reads the table segment blocks in the following sequence:
1.Block 1
2.Block 2
3.Block 1
4.Block 2
Thus, the number of block I/Os in this example is double the number in the index-organized example.
Index-Organized Tables with Row Overflow Area
When creating an index-organized table, you can specify a separate segment as a row overflow area. In index-organized tables, B-tree index entries can be large because they contain an entire row, so a separate segment to contain the entries is useful. In contrast, B-tree entries are usually small because they consist of the key and rowid.
If a row overflow area is specified, then the database can divide a row in an index-organized table into the following parts:
■The index entry
This part contains column values for all the primary key columns, a physical rowid that points to the overflow part of the row, and optionally a few of the non-key columns. This part is stored in the index segment.
■The overflow part
This part contains column values for the remaining non-key columns. This part is stored in the overflow storage area segment.
Logical Rowids and Physical Guesses
Secondary indexes use the logical rowids to locate table rows. A logical rowid includes a physical guess, which is the physical rowid of the index entry when it was first made. Oracle Database can use physical guesses to probe directly into the leaf block of the index-organized table, bypassing the primary key search. When the physical location of a row changes, the logical rowid remains valid even if it contains a physical guess that is stale.
For a heap-organized table, access by a secondary index involves a scan of the secondary index and an additional I/O to fetch the data block containing the row. For index-organized tables, access by a secondary index varies, depending on the use and accuracy of physical guesses:
■Without physical guesses, access involves two index scans: a scan of the secondary index followed by a scan of the primary key index.
■With physical guesses, access depends on their accuracy:
–With accurate physical guesses, access involves a secondary index scan and an additional I/O to fetch the data block containing the row.
–With inaccurate physical guesses, access involves a secondary index scan and an I/O to fetch the wrong data block (as indicated by the guess), followed by an index unique scan of the index organized table by primary key value.
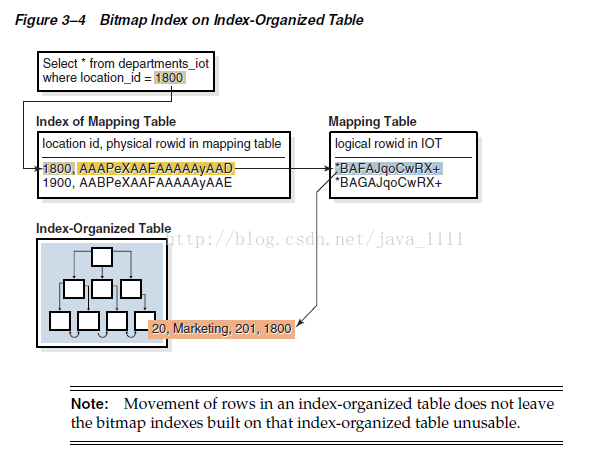
Bitmap Indexes on Index-Organized Tables
A secondary index on an index-organized table can be a bitmap index. As explained in "Bitmap Indexes" on page 3-13, a bitmap index stores a bitmap for each index key.
When bitmap indexes exist on an index-organized table, all the bitmap indexes use a heap-organized mapping table. The mapping table stores the logical rowids of the index-organized table. Each mapping table row stores one logical rowid for the corresponding index-organized table row.
The database accesses a bitmap index using a search key. If the database finds the key, then the bitmap entry is converted to a physical rowid. With heap-organized tables, the database uses the physical rowid to access the base table. With index-organized tables, the database uses the physical rowid to access the mapping table, which in turn yields a logical rowid that the database uses to access the index-organized table. Figure 3–4 illustrates index access for a query of the departments_iot table.
http://www.blogjava.net/wxqxs/archive/2008/10/14/237181.html















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









