





概述
- 不浪费内存:当 Hibernate 从数据库中加载 Customer 对象时, 如果同时加载所有关联的 Order 对象, 而程序实际上仅仅需要访问 Customer 对象, 那么这些关联的 Order 对象就白白浪费了许多内存.
- 更高的查询效率:发送尽可能少的 SQL 语句
类级别的检索策略
- 类级别可选的检索策略包括立即检索和延迟检索, 默认为延迟检索
- 立即检索: 立即加载检索方法指定的对象
- 延迟检索: 延迟加载检索方法指定的对象。在使用具体的属性时,再进行加载
- 类级别的检索策略可以通过 <class> 元素的 lazy属性进行设置
- 如果程序加载一个对象的目的是为了访问它的属性, 可以采取立即检索.
- 如果程序加载一个持久化对象的目的是仅仅为了获得它的引用, 可以采用延迟检索。注意出现懒加载异常!
- 无论 <class> 元素的 lazy 属性是 true 还是 false, Session 的 get() 方法及 Query 的 list() 方法在类级别总是使用立即检索策略
- 若 <class> 元素的 lazy 属性为 true 或取默认值, Session 的 load() 方法不会执行查询数据表的 SELECT 语句, 仅返回代理类对象的实例, 该代理类实例有如下特征:
- 由 Hibernate 在运行时采用 CGLIB 工具动态生成
- Hibernate 创建代理类实例时, 仅初始化其 OID 属性
- 在应用程序第一次访问代理类实例的非 OID 属性时, Hibernate 会初始化代理类实例
- 由 Hibernate 在运行时采用 CGLIB 工具动态生成
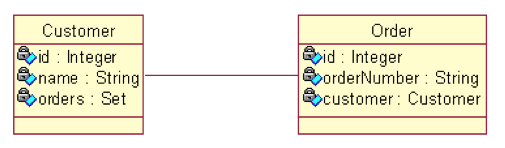
一对多和多对多的检索策略
在映射文件中, 用 <set> 元素来配置一对多关联及多对多关联关系. <set> 元素有 lazy 和 fetch 属性
- lazy: 主要决定 orders 集合被初始化的时机. 即到底是在加载 Customer 对象时就被初始化, 还是在程序访问 orders 集合时被初始化
- fetch: 取值为 “select” 或 “subselect” 时, 决定初始化 orders 的查询语句的形式; 若取值为”join”, 则决定 orders 集合被初始化的时机
- 若把 fetch 设置为 “join”, lazy 属性将被忽略
- <set> 元素的 batch-size 属性:用来为延迟检索策略或立即检索策略设定批量检索的数量. 批量检索能减少 SELECT 语句的数目, 提高延迟检索或立即检索的运行性能.
<set> 元素的 lazy 和 fetch 属性
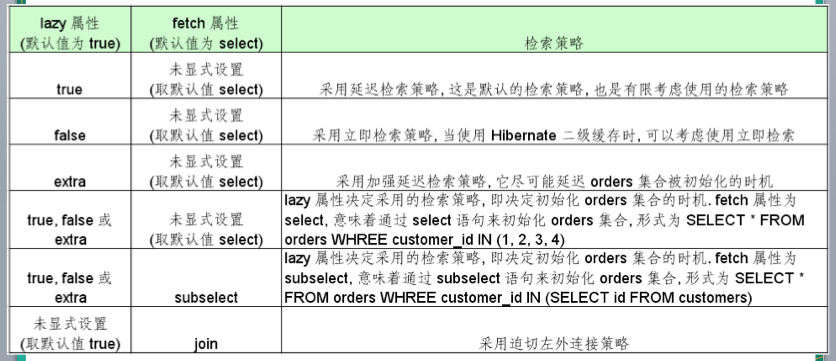
- 在延迟检索(lazy 属性值为 true) 集合属性时, Hibernate 在以下情况下初始化集合代理类实例
- 应用程序第一次访问集合属性: iterator(), size(), isEmpty(), contains() 等方法
- 通过 Hibernate.initialize() 静态方法显式初始化
- 应用程序第一次访问集合属性: iterator(), size(), isEmpty(), contains() 等方法
- 增强延迟检索(lazy 属性为 extra): 与 lazy=“true” 类似. 主要区别是增强延迟检索策略能进一步延迟 Customer 对象的 orders 集合代理实例的初始化时机:
- 当程序第一次访问 orders 属性的 iterator() 方法时, 会导致 orders 集合代理类实例的初始化
- 当程序第一次访问 order 属性的 size(), contains() 和 isEmpty() 方法时, Hibernate 不会初始化 orders 集合类的实例, 仅通过特定的 select 语句查询必要的信息, 不会检索所有的 Order 对象
<set> 元素有一个 batch-size 属性, 用来为延迟检索策略或立即检索策略设定批量检索的数量. 批量检索能减少 SELECT 语句的数目, 提高延迟检索或立即检索的运行性能.
用带子查询的 select 语句整批量初始化 orders 集合(fetch 属性为 “subselect”)
- <set> 元素的 fetch 属性: 取值为 “select” 或 “subselect” 时, 决定初始化 orders 的查询语句的形式; 若取值为”join”, 则决定 orders 集合被初始化的时机.默认值为 select
- 当 fetch 属性为 “subselect” 时
- 假定 Session 缓存中有 n 个 orders 集合代理类实例没有被初始化, Hibernate 能够通过带子查询的 select 语句, 来批量初始化 n 个 orders 集合代理类实例
-
batch-size 属性将被忽略
-
子查询中的 select 语句为查询 CUSTOMERS 表 OID 的 SELECT 语句
- 假定 Session 缓存中有 n 个 orders 集合代理类实例没有被初始化, Hibernate 能够通过带子查询的 select 语句, 来批量初始化 n 个 orders 集合代理类实例
- <set> 元素的 fetch 属性: 取值为 “select” 或 “subselect” 时, 决定初始化 orders 的查询语句的形式; 若取值为”join”, 则决定 orders 集合被初始化的时机.默认值为 select
- 当 fetch 属性为 “join” 时:
- 检索 Customer 对象时, 会采用迫切左外连接(通过左外连接加载与检索指定的对象关联的对象)策略来检索所有关联的 Order 对象
- lazy 属性将被忽略
- Query 的list() 方法会忽略映射文件中配置的迫切左外连接检索策略, 而依旧采用延迟加载策略
- 检索 Customer 对象时, 会采用迫切左外连接(通过左外连接加载与检索指定的对象关联的对象)策略来检索所有关联的 Order 对象
- 和 <set> 一样, <many-to-one> 元素也有一个 lazy 属性和 fetch 属性.
- 若 fetch 属性设为 join, 那么 lazy 属性被忽略
- 迫切左外连接检索策略的优点在于比立即检索策略使用的 SELECT 语句更少.
- 无代理延迟检索需要增强持久化类的字节码才能实现
- Query 的 list 方法会忽略映射文件配置的迫切左外连接检索策略, 而采用延迟检索策略
- 如果在关联级别使用了延迟加载或立即加载检索策略, 可以设定批量检索的大小, 以帮助提高延迟检索或立即检索的运行性能.
- Hibernate 允许在应用程序中覆盖映射文件中设定的检索策略.

检索策略小结
类级别和关联级别可选的检索策略及默认的检索策略

3 种检索策略的运行机制

映射文件中用于设定检索策略的几个属性

比较 Hibernate 的三种检索策略

代码详解:
Customer.java
package com.atguigu.hibernate.strategy;
import java.util.HashSet;
import java.util.Set;
public class Customer {
private Integer customerId;
private String customerName;
private Set<Order> orders = new HashSet<>();
public Integer getCustomerId() {
return customerId;
}
public void setCustomerId(Integer customerId) {
this.customerId = customerId;
}
public String getCustomerName() {
return customerName;
}
public void setCustomerName(String customerName) {
this.customerName = customerName;
}
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
}
Order.java
package com.atguigu.hibernate.strategy;
public class Order {
private Integer orderId;
private String orderName;
private Customer customer;
public Integer getOrderId() {
return orderId;
}
public void setOrderId(Integer orderId) {
this.orderId = orderId;
}
public String getOrderName() {
return orderName;
}
public void setOrderName(String orderName) {
this.orderName = orderName;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer customer) {
this.customer = customer;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((orderId == null) ? 0 : orderId.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Order other = (Order) obj;
if (orderId == null) {
if (other.orderId != null)
return false;
} else if (!orderId.equals(other.orderId))
return false;
return true;
}
}
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.atguigu.hibernate.strategy">
<class name="Customer" table="CUSTOMERS" lazy="true" batch-size="5">
<id name="customerId" type="java.lang.Integer">
<column name="CUSTOMER_ID" />
<generator class="native" />
</id>
<property name="customerName" type="java.lang.String">
<column name="CUSTOMER_NAME" />
</property>
<set name="orders" table="ORDERS"
inverse="true" order-by="ORDER_NAME DESC" lazy="true"
batch-size="2" fetch="subselect">
<key column="CUSTOMER_ID"></key>
<one-to-many class="Order"/>
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.atguigu.hibernate.strategy">
<class name="Order" table="ORDERS">
<id name="orderId" type="java.lang.Integer">
<column name="ORDER_ID" />
<generator class="native" />
</id>
<property name="orderName" type="java.lang.String">
<column name="ORDER_NAME" />
</property>
<many-to-one
name="customer" class="Customer"
column="CUSTOMER_ID"
lazy="false"
fetch="join"></many-to-one>
</class>
</hibernate-mapping>
package com.atguigu.hibernate.strategy;
import java.util.List;
import org.hibernate.Hibernate;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import org.hibernate.service.ServiceRegistry;
import org.hibernate.service.ServiceRegistryBuilder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class HibernateTest {
private SessionFactory sessionFactory;
private Session session;
private Transaction transaction;
@Before
public void init(){
Configuration configuration = new Configuration().configure();
ServiceRegistry serviceRegistry =
new ServiceRegistryBuilder().applySettings(configuration.getProperties())
.buildServiceRegistry();
sessionFactory = configuration.buildSessionFactory(serviceRegistry);
session = sessionFactory.openSession();
transaction = session.beginTransaction();
}
@After
public void destroy(){
transaction.commit();
session.close();
sessionFactory.close();
}
@Test
public void testMany2OneStrategy(){
// Order order = (Order) session.get(Order.class, 1);
// System.out.println(order.getCustomer().getCustomerName());
List<Order> orders = session.createQuery("FROM Order o").list();
for(Order order: orders){
if(order.getCustomer() != null){
System.out.println(order.getCustomer().getCustomerName());
}
}
//1. lazy 取值为 proxy 和 false 分别代表对应对应的属性采用延迟检索和立即检索
//2. fetch 取值为 join, 表示使用迫切左外连接的方式初始化 n 关联的 1 的一端的属性
//忽略 lazy 属性.
//3. batch-size, 该属性需要设置在 1 那一端的 class 元素中:
//<class name="Customer" table="CUSTOMERS" lazy="true" batch-size="5">
//作用: 一次初始化 1 的这一段代理对象的个数.
}
@Test
public void testSetFetch2(){
Customer customer = (Customer) session.get(Customer.class, 1);
System.out.println(customer.getOrders().size());
}
@Test
public void testSetFetch(){
List<Customer> customers = session.createQuery("FROM Customer").list();
System.out.println(customers.size());
for(Customer customer: customers){
if(customer.getOrders() != null)
System.out.println(customer.getOrders().size());
}
//set 集合的 fetch 属性: 确定初始化 orders 集合的方式.
//1. 默认值为 select. 通过正常的方式来初始化 set 元素
//2. 可以取值为 subselect. 通过子查询的方式来初始化所有的 set 集合. 子查询
//作为 where 子句的 in 的条件出现, 子查询查询所有 1 的一端的 ID. 此时 lazy 有效.
//但 batch-size 失效.
//3. 若取值为 join. 则
//3.1 在加载 1 的一端的对象时, 使用迫切左外连接(使用左外链接进行查询, 且把集合属性进行初始化)的方式检索 n 的一端的集合属性
//3.2 忽略 lazy 属性.
//3.3 HQL 查询忽略 fetch=join 的取值
}
@Test
public void testSetBatchSize(){
List<Customer> customers = session.createQuery("FROM Customer").list();
System.out.println(customers.size());
for(Customer customer: customers){
if(customer.getOrders() != null)
System.out.println(customer.getOrders().size());
}
//set 元素的 batch-size 属性: 设定一次初始化 set 集合的数量.
}
@Test
public void testOne2ManyLevelStrategy(){
Customer customer = (Customer) session.get(Customer.class, 1);
System.out.println(customer.getCustomerName());
System.out.println(customer.getOrders().size());
Order order = new Order();
order.setOrderId(1);
System.out.println(customer.getOrders().contains(order));
Hibernate.initialize(customer.getOrders());
//---------------set 的 lazy 属性------------------
//1. 1-n 或 n-n 的集合属性默认使用懒加载检索策略.
//2. 可以通过设置 set 的 lazy 属性来修改默认的检索策略. 默认为 true
//并不建议设置为 false.
//3. lazy 还可以设置为 extra. 增强的延迟检索. 该取值会尽可能的延迟集合初始化的时机!
}
@Test
public void testClassLevelStrategy(){
Customer customer = (Customer) session.load(Customer.class, 1);
System.out.println(customer.getClass());
System.out.println(customer.getCustomerId());
System.out.println(customer.getCustomerName());
}
}















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









