







零、前言
彩虹表的出现是为了解决破解 Hash 算法成本过高的问题(时间过长、所需硬盘空间过大)。
以前我也跟其他很多人一样,认为彩虹表就是描述“明文 & 密文”对应关系的一个大型数据库,破解时通过密文直接反查明文。
今天因某些需要而详细了解了彩虹表的一些细节,才发现其原理比之前想象的更值得称赞。它所谓的 time-memory trade-off,并不是简单地“以空间换时间”,而是双向的“交易”,在二者之间达到平衡。在此分享一些心得。本部分内容本答案主要参考资料为英文维基的 Rainbow table 词条。答案末尾分隔线后附上一个简化的比喻,希望能给更多的人说清楚这个问题。
一、前身
在彩虹表之前,已经出现了对哈希函数的破解算法,被称为“预计算的哈希链集”(Precomputed hash chains)。
当面对要破解的哈希函数 H,首先要定义一个约简函数(reduction function)R,该函数的定义域和值域需要和哈希函数相反,通过该函数可以将哈希值约简为一个与原文相同格式的值(plain text value)。
需要强调的是,由于哈希函数 H 是不可逆的,所以对于密文进行 R 运算几乎不可能得到明文原文。例如,五位字母明文“zhihu”进行 H 运算后得到了“D2A82C9A”,而对“D2A82C9A”进行 R 运算后得到另一个五位字母格式的值“vfkkd”。因为这个值落在 H 的定义域中,因此可以对它继续进行 H 运算。就这样,将 H 运算、R 运算、H 运算……这个过程反复地重复下去,重复一个特定的次数 k 以后,就得到一条哈希链,例如 k 为 2 时得到:
![]()
这条链条并不需要完整地保存下来,只需要保存其起节点和末节点即可,例如上例中只需要保存起节点“zhihu”和末节点“crepa”。以大量的随机明文作为起节点,通过上述步骤计算出哈希链并将终节点进行储存,即可得到一张哈希链集。
这张集合需要如何使用呢?例如,我们知道哈希运算后的密文为“0CAFC376”,则先对其进行一次 R 运算,得到“crepa”。
![]()
正巧在本例中,它等于集合中的一个末节点,因此我们可以猜测,明文有极大的可能存在于以起节点“zhihu”开头、末节点“crepa”结尾的这条哈希链中。(注意可能性并不是100%,因为函数 H 和 R 均有可能发生碰撞,从不同的输入值得到相同的输出值。)为了验证我们的猜测,可以从起节点“zhihu”开始重复哈希链的计算过程:
![]()
算到这里我们发现,“vfkkd”进行哈希运算的结果正是密文“0CAFC376”,这样就找到了所需的明文。
如果密文不是“0CAFC376”而是“D2A82C9A”,第一次 R 运算后的结果并未在末节点中找到,则再重复一次 H 运算 + R 运算,这时又得到了末节点中的值“crepa”,则我们还是从起节点“zhihu”开始计算,这次可得到“D2A82C9A”对应的明文为“zhihu”。<
如果如是重复了 k(=2)次之后,仍然没有在末节点中找到对应的值,则可以断定,所需的明文不在这张集合中 -- 集合中并未储存长度大于 k 的哈希链,因此再计算也没有意义了。
如果让我来解释哈希链的意义,我认为,每一条哈希链实际上是代表了属性相同的一组明文。每一个明文都可以通过起节点迅速的计算得出,计算次数不大于 k,因而可以大大节约时间。对每一组明文,只需要保存其特征值(起节点和末节点),储存空间只需约 1/ k,因而大大节约了空间。
二、R的问题
在构造哈希链的时候,一个优秀的函数 R 功不可没。首先 R 需要能将值域限定在固定的范围——例如给定的长度范围、给定的字符取值范围等等——之内,否则的话,哈希链中大量的计算结果并不在可接受的取值范围内,一条链条无法对应多个明文,链条就失去了意义;其次R必须同哈希函数一样,尽量保证输出值在值域中的均匀分布,减少碰撞的概率。
然而实际上,很难找到能满足这些需求的完美的 R 函数。当计算中发生碰撞时,就会出现如下的情况:

图中加粗的部分,所涉及到的明文是完全重复的,因此这两条哈希链能解密的明文数量就远小于理论上的明文数 2×k。不幸的是,由于集合只保存链条的首末节点,因此这样的重复链条并不能被迅速地发现。随着碰撞的增加,这样的重复链条会逐渐造成严重的冗余和浪费。
三、改进
对于这个问题,2003年提出的彩虹表算法进行了针对性的改进。
它在各步的运算中,并不使用统一的 R 函数,而是分别使用R1…Rk共 k 个不同的 R 函数。这样生成的哈希链集即被称为彩虹表。(在不同的运算位置使用不同的R函数,就像彩虹由内而外的不同位置上显示出不同的颜色一样。)这样一来,如果发生碰撞,通常会是下图的情况:

不难发现,当两个链条发生碰撞的位置并非相同的序列位置时,后续的R函数的不一致使得链条的后续部分也不相同,从而最大程度地减小了链条中的重复节点,保证了链条的有效性。同时,如果在极端情况下,两个链条有 1/ k 的概率在同一序列位置上发生碰撞,导致后续链条完全一致,这样的链条也会因为末节点相同而检测出来,可以丢弃其中一条而不浪费存储空间。
彩虹表的使用比哈希链集稍微麻烦一些。首先,假设要破解的密文可能位于任一链条的 k-1位置处,对其进行 Rk 运算,看是否能够在末节点中找到对应的值。如果找到,则可以如前所述,使用起节点验证其正确性。否则,需要继续假设密文位于 k-2 位置处,这时就需要进行 R(k-1)、H、R(k) 两步运算,然后在末节点中查找结果。如是反复,最不利条件下需要将密文进行完整的R(1)、H、…R(k)运算后,才能得知密文是否存在于彩虹表之中。
四、时间、空间的平衡
通过彩虹表的使用方法可以明显地看出,一条哈希链实际代表的是一组明文的解密规则:
![]()
等价于k条子规则:
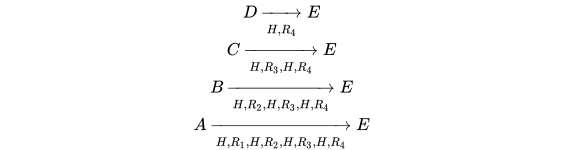
类似的,前述的哈希链集也可以进行这样的拆解,只不过其拆解后的子规则的运算过程中有很多中间结果可以复用,因此其最大计算次数为 k,平均计算次数为![]() ;而彩虹表的最大计算次数为
;而彩虹表的最大计算次数为![]() ,平均计算次数为
,平均计算次数为 ![]() 。可见,要解相同个数的明文,彩虹表的代价会高于哈希链集。不过,因为彩虹表可以节省不少重复链条的存储和计算的代价,所以还是值得的。
。可见,要解相同个数的明文,彩虹表的代价会高于哈希链集。不过,因为彩虹表可以节省不少重复链条的存储和计算的代价,所以还是值得的。
同时,对于相同个数的明文,当 k 越大时,破解的期望时间就越长,但彩虹表所占用的空间就越小;相反,k 越小时,彩虹表本身就越大,相应的破解时间就越短。这正是保持空间、时间二者平衡的精髓所在。
RainbowCrack 中 rtgen 工具使用的默认 k 值好像是 2100。极端的,令 k = 1,简化函数 R(x) = x,这样的彩虹表就变成了通常的错误理解,即将明文、密文对应关系全部保存的表。此时由于 k 极小,因而得到的表的体积极大,甚至可能超出储存能力。(当然,对于范围较小的明文,如 6 位以下数字英文的组合,或是全世界常用密码的集合,生成 k = 1 的表还是不费什么事的。)
五、再谈 R 函数
先重复一下前面所说的 R 函数所需的性质:
1、R 需要能将值域限定在固定的范围之内。事实上,在计算和下载彩虹表时,不同类型的猜解范围是需要用不同的库的,例如下载网站 List of Rainbow Tables 上,按照不同的哈希函数、字符集、密码长度等分为很多个不同的库,这些库所使用的 R 函数都是不一样的,这样才能保证 R 函数的值域和所需的猜解范围保持一致。
2、R 需要尽量保证输出值在值域中的均匀分布,减少碰撞的概率。
六、彩虹表的防御
关于彩虹表的防御方式,大多与彩虹表的原理,即其生成步骤中用到的函数 H 有关。
最常用的方法,在其它的答案中也提到了,那就是加盐(salt),这其实是改变了哈希函数 H 的形式。由于彩虹表在生成和破解的过程中,都反复用到了函数 H,H 如果发生了改变,则已有的彩虹表数据就完全无法使用,必须针对特定的 H 重新生成,这样就提高了破解的难度。
防御彩虹表的另一种方法是提高 H 函数的计算难度,例如将 H 定义为计算一千次 MD5 后的结果。由于H在算法中的重复性,当单次 H 函数的计算耗时增加,意味着彩虹表的生成时间会大大的增加,从而也能提高破解的成本。
七、总结
如果将哈希后的密文比作一把锁,暴力破解的方法就是现场制作各种各样不同齿形的钥匙,再来尝试能否开锁,这样耗时无疑很长;我以前错误理解的“彩虹表”,是事先制作好所有齿形的钥匙,全部拿过来尝试开锁,这样虽然省去了制作钥匙的时间,但是后来发现这些钥匙实在是太多了,没法全部带在身上。
真正的彩虹表,是将钥匙按照某种规律进行分组,每组钥匙中只需要带最有特点的一个,当发现某个“特征钥匙”差一点就能开锁了,则当场对该钥匙进行简单的打磨,直到能开锁为止。这种方法是既省力又省时的。
须知:本篇来源于知乎,若侵权请告知,本人会立刻删除。
(SAW:Game Over!)















 8449
8449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









