




 博客围绕商城搜索功能优化展开。最初使用 like 方法无法满足需求,尝试字符拆分、使用 regexp_like 及字符串映射,仍出现误搜问题。后调整拆分类型,又遇中文搜索难题,尝试分词工具不理想,最终采用自定义词典定制分词,满足了产品和测试需求,后续还需做缓存提升速度。
博客围绕商城搜索功能优化展开。最初使用 like 方法无法满足需求,尝试字符拆分、使用 regexp_like 及字符串映射,仍出现误搜问题。后调整拆分类型,又遇中文搜索难题,尝试分词工具不理想,最终采用自定义词典定制分词,满足了产品和测试需求,后续还需做缓存提升速度。
从产品拿到了一个需求,要求搜 “jordan3男款” 要显示出 ”AJ 3 Retro Chlorophyll 叶绿素 男款136064-006“ 这款鞋子
商城现在的搜索使用的是like %%方法,只能简单的搜出连续出现 ”jordan3男款“ 标题的产品,于是我对这串文字做了分析
首先 ‘jordan3女款’ 含有三种类型的字符: 英文,数字, 中文,如果对其拆分,可以得到 ‘jordan|3|女款’, 这一下肯定不能使用like来做了,于是我选择使用regexp_like来处理,分词之间也不能使用或的关系了,为了达到目的我把 ”|“ 换成了.*
于是like %jordan3男款% 变成了
regexp_like(field, 'jordan.*3.*女款', 'i')
这样做 3和女款满足了,但是jordan => aj依然不行,于是我想到了使用字符串映射来达到目的,原理很简单写一个映射,jordan映射成aj即可,出于可配置,我在后台写了一个列表管理,效果如下

为了防止标题AJ3变成了 jordan3 这里查询aj或者查询 jordan都会对这两个做搜索,于是变成了
regexp_like(field, '(jordan|aj).*3.*女款', 'i')
很显然,满足产品需求了呀,果断撸了代码提交测试
很快便被打脸了,测试发现一款nike也被搜了出来,它的标题是这样的 “耐克/Nike Air More Uptempo 皮蓬 跑步鞋 红色 AJ3138-600 女款”, 我怀疑nike出这个系列是为了挖aj3关键词的吧 🤦🏻♀️
痛定思痛,于是我再一次对 “jordan3女款” 和 “AJ 3 Retro Chlorophyll 叶绿素 男款136064-006” 产品做对比,同时跟产品讨论了一番,他告诉我3是aj的一个系列,甚至1, 2系列也都有,系列前面很大可能会加空格。
于是我果断放弃了拆成三种类型,改成拆成两种类型英文和数字放在了一起, “jordan3女款” => “jordan3|女款”, 同时对映射也做了处理

处理出来的like语句也变成了
regexp_like(field, '(jordan3|aj 3).*女款', 'i')
深吸一口气,终于完成了,美滋滋提交测试
qa经过一番严格的暴力测试,告诉我说 ”耐克女款“ 搜不到 ”耐克/Nike Air More Uptempo 皮蓬 跑步鞋 红色 AJ3138-600 女款"
我。。。。。。
考虑一番,我发现这需要中文分词,而不是简单的只做类型区分就行的。
于是我找到了ajsi, github地址 https://github.com/NLPchina/ansj_seg,经过测试发现效果不是很理想,不是拆的不准,而是商城的特殊性,使用分词类的工具会把中文拆的太零散,能搜到,但是搜的太多了!!! 🤦🏻♀️
然后我决定使用自定义词典定制分词,数据库分词使用关键词列表(庆幸自己没嫌麻烦把列表写出来了),而且它的好处是前端搜索入表,随着时间的推移,把搜索次数做成权重后,它的精确度会越来越高
于是我添加了耐克关键词,考虑到测试可能搜 nike women,nike女款, 耐克women,我对空格做了拆分,并且对子字符串做了进一步处理,于是变成了
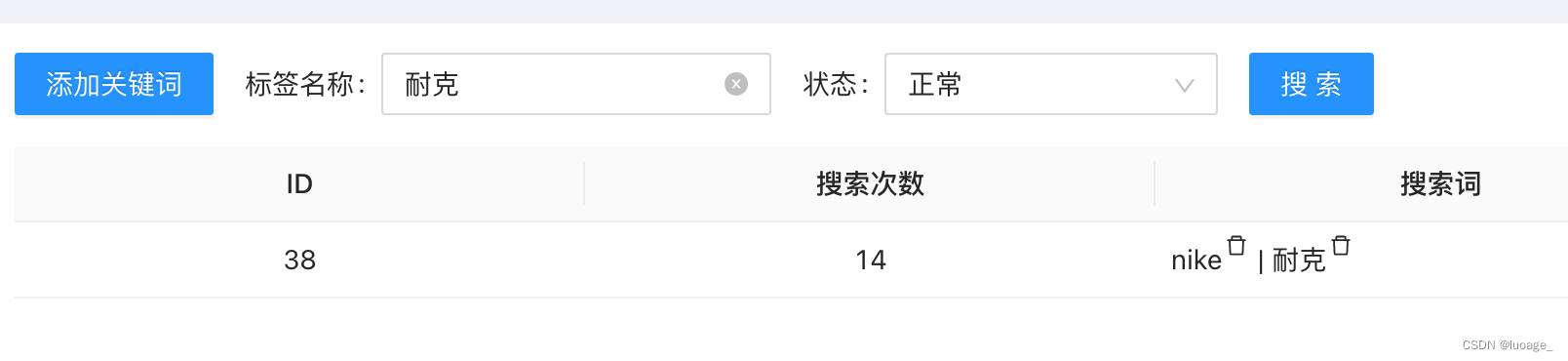
regexp_like(field, '(耐克|nike).*女款', 'i')
到此结束,满足了产品,同时满足了测试, 当然这个方案还是不完善的,后期随着数据量增大,还要把这些关键词做缓存,提升查询速度。
下面是类型拆分代码,数据库部分不便放出来
private String breakWordWithSpace(String word) {
String[] words = word.split("");
String regexp = "[\\u0391-\\uFFE5]"; // 中文正则
StringBuilder stringBuilder = new StringBuilder();
boolean[] isChinese = new boolean[words.length];
for (int i = 0; i < words.length; i++) {
isChinese[i] = words[i].matches(regexp);
if (i == 0) {
stringBuilder.append(words[i]);
continue;
}
if (isChinese[i - 1] != isChinese[i] && i != words.length - 1) {
stringBuilder.append(" ");
}
stringBuilder.append(words[i]);
}
return stringBuilder.toString();
}

















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









