







PageRank 让链接来"投票"
一个页面的「得票数」由所有链向它的页面的重要性來决定,到一个页面的超链接 相当于对该页投一票。一个页面的PageRank是由所有链向它的页面 (「链入页面」)的重要性经过递归 算法得到的。一个有較多链入的页面会有較高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
2005 年 初,Google为网页链接推出一项新属性nofollow ,使得网站管理员 和网志 作者可以做出一些Google不計票的链接,也就是說这些链接不算作"投票"。nofollow 的设置可以抵制评论垃圾。
Google工具条上的PageRank指標从0到10。它似乎是一个对数标度算法,细节未知。PageRank 是 Google 的商标,其技术亦已经申请专利 。
PageRank算法中的点击算法 是由Jon Kleinberg 提出的。
PageRank算法
简单的
假设一个由4个页面组成的小团体:A ,B , C 和 D 。如果所有页面都链向A , 那么A 的PR (PageRank)值将是B ,C 及 D 的和。
- P R (A ) = P R (B ) + P R (C ) + P R (D )
继续假设B 也有链接到C ,并且D 也有链接到包括A 的3个页面。一个页面不能投票2次。所 以B 给每个页面半票。以同样的逻辑 ,D 投 出的票只有三分之一算到了A 的 PageRank 上。
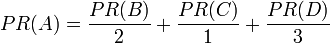
换句话说,根据链出总数平分一个页面的PR 值。
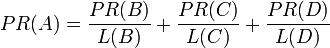
最后,所有这些被换算为一个百分比再乘上一个系数q 。由于下面的算法,没有页面的PageRank会是0。所以,Google通过数 学系统给了每个页面一个最小值1 − q 。
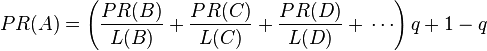
所以一个页面的 PageRank 是由其他页面的PageRank计算得到。Google 不断的重复计算每个页面的 PageRank。如果您给每个页面一个随机 PageRank 值(非0),那么经过不断的重复计算,这些页面的 PR 值会趋向于正常和稳定。这就是搜索引擎使用它的原因。
完整的
这个方程式引入了随机浏览 的概念,即有人上网无聊随机打开一些页面,点一些链接。一个页面的PageRank值也影响了它被随机浏览 的概率。为了便于理解,这里假设上网者不断点网页上的链接,最终到了一个没有任何链出页面的网页,这时候上网者会随机到另外的网页开始浏览。
为了对那些有链出的页面公平,q = 0.15 (这里的q 被称为阻尼系数(damping factor), 其意义是,在任意时刻,假想的随机浏览者停止在某页面后继续浏览的概率。)的算法被用到了所有页面上,估算页面可能被上网者放入书签的概率。
所以,这个等式如下:
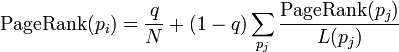
p 1 ,p 2 ,...,p N 是 被研究的页面,M (p i ) 是 链入p i 页面的数量,L (p j ) 是p j 链出页面的数量,而N 是所有页面 的数量。
PageRank 值是一个特殊矩阵中的特征向量。这个特征向量为

R 是等式的答案
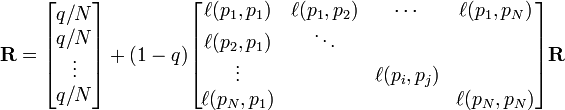
如果p j 不链向p i , 而且对每个j 都成立时,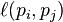 等 于 0
等 于 0
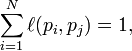
这项技术的主要缺點是旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多上游链接,除非它是某个站点的子站点。
这就是PageRank需要多项算法结合的原因。PageRank似乎倾向于维基百科 页面,在条目名称的搜索结果中总在大多数或者其他所有页面之前。原因主要是维基百科内相互的链接很多,并且 有很多站点链入。
Google经常处罚恶意提高PageRank的行为,至於其如何区分正常的链接交换和不正常的链接堆积仍然是商业机密 。
(转自维基百科)














 3070
3070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









