







- 1.1. 数组
- 1.2. 集合
- 1.3. 枚举器
- 1.4. 集合的类型
- 1.4.1. Vector
- 1.4.2. BitSet
- 1.4.3. Stack
- 1.4.4. Hashtable
- 1.5. 排序
- 1.6. 新集合
- 1.6.1. Collections
- 1.6.2. Lists
- 1.6.3. Sets
- 1.6.4. Maps
- 1.6.5. 关于具体集合类的选用
- 1.6.6. 排序和搜索等实用操作
1.1. 数组
数组相对而言是接触比较多的一种容纳对象的对象,对于数组的初始化有下面三种默认初始方式:
- 容纳基本数据类型的数组会自动初始化为0;
- 容纳字符类型的数组会自动初始化为
null; - 容纳
boolean类型的数组会自动初始化为false;
另外,对于未初始化的数组我们一般是不能对其进行输出行为的操作。值得注意的是对于一个数组实际使用的空间情况我们是不能简单的通过x.length的方式来获取(这是获取数组的总容量而非实际使用容量),而应该根据上述的3种默认的赋值就行判断某个或者某些位置被实际使用。在本小节最后,给出一个8种口味冰淇淋随机选择的20种方案(每种方案中不包含相同口味的冰激淋),也初次认识到retry这玩意儿,带着看了下其用法,基本是作为一个标记(通常是给一个循环体作标记,比如for、while),然后可以通过retry来对该循环体进行操作。
1.2. 集合
与之前的数组相比,集合具备更灵活的特点,Java提供了包括Vector、BitSet、Stack和Hashtable四种类型的集合,使用集合需要注意由类型引起的异常。
1.3. 枚举器
对于之前使用的Vector很方便,容量非固定,可以随实际使用情况不断扩充,但是对于使用需要事先知道对象的具体类型,从书中提出的Vector转List的案例中提出了迭代器(我习惯这么叫,书中称作“反复器”),引入枚举器Enumeration,可以直接通过集合类elements()方法可以获取一个枚举器实例,通过枚举器的nextElement()方法获取枚举器中的元素,枚举器的hasMoreElements()方法来判断其中是否还有元素,通过这两种方法的结合往往通过一个While循环可以取出其中所有元素。
1.4. 集合的类型
本小节主要针对前面提到了四种集合类:Vector、BitSet、Stack和Hashtable进行学习。
1.4.1. Vector
存–addElement(),取–elementAt(index),在书中给出如下的一段代码
public class CrashJava {
@Override
public String toString() {
return "CrashJava address: " + this + "\n";
}
public static void main(String[] args) {
Vector v = new Vector();
for (int i = 0; i < 10; i++) {
v.addElement(new CrashJava());
}
System.out.println(v);
}
}初次看没看明白,在跑上述的代码时,JVM抛出堆栈溢出的异常,主要是由于java在对于输出语句中的关键字this的处理,因为在CrashJava类中重写了其toString()方法,在返回结果时同时夹杂有CrashJava address:这类字符串,所以java自然而然会调用当前对象的toString()方法试图将这里的this转换成字符串信息,这就造成了自身不端调用自身的尴尬情况,而且没有停止的标识符,导致堆栈溢出,可以直接调用父类的toString()方法来解决此问题。
1.4.2. BitSet
BitSet是位操作对象,按位存储,它默认长度为64位,当位数不够时,自动扩充,每次扩充64位,最终以long segement的形式存储,这个集合类在我自己平时做东西过程中几乎没有接触过,或许等用到时会仔细搞一下。
1.4.3. Stack
对于堆的概念相对接触的比较多一些,不论是数据结构还是JVM中GC机制,对这一块都有多多少少的涉及,Stack典型特征就是先进后出(LIFO),它继承自Vector类,所以除了它自身具备的pop()、push()、peek()等方法外,我们同样可以像书中案例中那样使用Vector的操作来操作Stack(addElement()、elementAt()等)。
1.4.4. Hashtable
在该小点开始时,书中搞了一个Dictionary的Demo,整体并不复杂,但是在实现过程中出了一点小插曲:在最后的输出中是这样一种表述System.out.println("Uppercase: " + d.get(String.valueOf(ca[i])));,再看被调函数的声明public Object get(Object key),当时太马虎,一脸懵逼,为啥这里非要搞成String类型的,还固执的改成ca[i]去试一下,果不其然得到的都是null,回头再一看,在进行put操作时,键、值都是以String的形式存入,这样一来就恍然大悟了,但是随即又冒出一个智障想法,为什么在申明方法的时候不直接将参数声明成String而是Object,然后瞬间就明白了,毕竟自己还太浅薄,程序员基本素质是具备一定的抽象能力,写的代码需要具备一定的复用性,所以作者声明为Object,再说key值并不一定非要是String,通过字典程序的执行效率问题,引入Hashtable。
书中关于Hashtable的使用,主要是以Counter和SpringDetector两个案例,使用相差不大,意在说明在Hashtable中key可以是基本数据类型的包装类,也可以是我们自定义的类,关键是后者,使用自定义类存储可以存储,那么如何通过自定义类来取出对应的value(简单点讲就是如何判断key值就是Hashtable中的key),文中以new Groundhog2(3)为key取出值,现然此new Groundhog2(3)非彼new Groundhog2(3),所以最终探讨的问题是回到最基本的对象是否相同判断上,引出SpringDetector2案例,必须重写自定义类的hasCode()和equals()方法,从而解决问题。
1.5. 排序
在正式论述排序前,文章有意无意的花了一部分时间在讲代码复用的思想,由于Java中类单继承的特性,接口可以很大程度上帮我们提升代码复用率,文中也指出:
程序设计一个主要的目标就是“将发生变化的东西同保持不变的东西分隔开”。
之前读Head First设计模式时,真正意义上开始认识到这种思想的伟大,现在回头来看,程序的设计者思想确实很很棒,书中使用一个英文字母排序的案例,作者介绍了两种实现的方式,个人偏向于第一种实现方式,虽然实现方式相对第二种略显繁琐,但是具备较强的通用性,第二种将对象对象固定为String类型,本身代码具备局限性(即使String类排序有很多用处),虽然有这个毛病,但是在第二种实现方式中,有下面这样一段代码:
public void addElement(String s) {
v.addElement(s);
sorted = false;
}
public String elementAt(int index) {
if(!sorted) {
v.sort();
sorted = true;
}
return (String)v.elementAt(index);
}
public Enumeration elements() {
if(!sorted) {
v.sort();
}
return v.elements();
}之所以将这段贴出来是因为考虑到程序执行效率的问题,其中addElement()为存方法,只是简单的存入,而elementAt()和Enumeration()为取方法,做了一个检查排序标志位的行为,如果未排序则先执行排序操作然后再返回,这样可以保证用户在读取时是读取的有序数据,这里让我很容易想到“懒加载”的概念。
1.6. 新集合
其实相对于之前四种的集合讲解对于我而言有些陌生,较为熟悉的是这一小节的新集合:Map、List、Set,正像作者所说的用“反复器”(其实我更习惯叫迭代器,任何集合都可以生成迭代器)代替了“枚举”,总之新集合改了一些名称同时也增强了功能,新集合主要分割为下面两类:
| 集合类别 | 特性 |
|---|---|
集合(Collection) | 一组单独的元素,通常应用某种规则,如List必须按照特定的顺序容纳元素,而Set不能包含重复元素 |
映射(Map) | 是一系列的键-值对,但是不以键-值对的方式实现它,而是将两者单独分开,这样可以方便的查看Map的某个部分,Map可以返回包含键的Set、包含值的List或者是包含键-值对的一个List |
1.6.1. Collections
下面总结了一个集合大概可以干的事(Set和List共有的功能,List拥有一些额外的功能):
| 方法 | 含义 |
|---|---|
Boolean add(Object) | 保证集合正常添加元素,否则返回false |
Boolean addAll(Collection) | 将一个集合的所有元素添加到另一个集合中,如果该集合中根本没有元素添加返回false,若所有元素均被添加返回true(书中翻译有误) |
Boolean contains(Object) | 若包含该元素返回true |
Boolean containsAll(Collection) | 若集合内包含参数集合内所有元素返回true |
Boolean isEmpty() | 集合为空返回true |
Iterator iterator() | 返回一个用于遍历集合的迭代器 |
Boolean remove(Object) | 删除集合内已有的元素后返回true |
Boolean removeAll(Collection) | 删除参数集合中所包含的所有元素后返回true |
Boolean retainAll(Collection) | 只保留参数集合也存在的元素(两个集合的交集)后返回true |
int size() | 返回集合中元素的数量 |
Object[] toArray() | 返回一个包含集合中所有元素的数组 |
Object[] toArray(Object[] a) | 返回一个包含集合所有元素的数组,必须是数组类型而非普通的Object |
文中的案例也是围绕上表的方法进行操作说明,但是值得一说的是最后两个方法,也是我初学时比较困惑的地方,toArray()方法是返回一个包含集合中所有元素的数组,相信大多数人都曾将在使用它的时候将其返回值强转成某种具体类型的数组(比如String[]),但是都会出现java.lang.ClassCastException,当然直接使用返回的Object[]可以取出集合元素(并且很安全,它是将原有集合元素拷贝了一份来给我们操作),但是有时就想给他写到具体的类型,这时候就会用到第二种方法toArray(Object[] a),该方法的返回值就可以进行强转,比如String[] arr = (String[]) list3.toArray(new String[list3.size()]),但对于前者一直有一个疑问,写成Object[]是否合适(java中万物皆对象,就像别人问你是谁,你回答你是人,虽然这个回答在一定程度上体现了以为程序员高深的编程思想,但是正常人会觉得你有毛病),所以对于这个返回值一直有种疑问,这个具体是什么,为什么在集合中存放String类型的元素,用String[]来接受就出现转换异常。
1.6.2. Lists
List:作为集合的一种(接口),按序排列是其很重要的一点特征,List为Collection添加很多允许在List中间添加、删除元素的方法(只推荐用LinkedList),由List产生的迭代器可以用来正向或逆向遍历集合元素,同样包含在List中间添加或删除元素;ArrayList:基于动态数组实现的一种List,允许对元素随机访问,但是在其中插入和删除元素比较缓慢(因为需要移动元素),因此它的迭代器一般只用于遍历元素,而不用来进行插入或删除操作;LinkedList:提供最优的顺序访问,在其中间进行插入或删除都很快,但随机存取相对较慢,基于链表实现
至于书中的List1案例,都是正常使用,在JDK1.7版本中有一些方法已经移除(比如removeRange()和indexOf(var, index)),主要记录一下利用迭代器进行插入、删除的操作(大部分人都是利用它来做遍历操作),其实我理解下来这里的迭代器跟游标或者指针很相似,下面是代码部分:
//定位cur到第15个元素(4)的位置(总共30个元素)
ListIterator x = a.listIterator(a.size() / 2);
//在“4”后面插入“one”,cur后移一位到"one"位置
x.add("one");
print(a);
//“one”后面是“5”,cur定位到“5”
System.out.println(x.next());
//移除当前cur位置的元素
x.remove();
//原来的“5”后面为“6”,cur定位至“6”
System.out.println(x.next());
//将cur当前所谓元素(“6”)设置为“47”
x.set("47");
print(a);
//逆序遍历
x = a.listIterator(a.size());
while (x.hasPrevious()) {
System.out.print(x.previous() + " ");
}1.6.3. Sets
Set与Collection接口完全相同,所以比上述List少一些功能,都是第一部分Collections中的方法,前面知道List的特征是有序可重复的,这里Set特征则是无序不可重复的,下面是几种Set的实现类:
HashSet:对于快速查找很重要的集合,对象必须定义hashCode();TreeSet:基于红黑树的有序集合;
书中有这么一句话:
一个Set不能保证自己可按任何特定的顺序维持自己的元素。
【注意】那么TreeSet在存储Integer、String类型时自动按照升序排列怎么解释呢,很奇葩。通常要想将自定义类存放到TreeSet中,那么该类必须实现Comparable接口重写compareTo()方法
1.6.4. Maps
Map都是以键-值对的形式出现,可以通过key值来查找对应的value,主要有HashMap和TreeMap。
HashMap:基于哈希表实现,对于键-值对的插入和检索具备稳定的性能(可通过构造器进行性能的调整)。TreeMap:基于红黑实现,当查看时,返回有序序列(取决于Comparable),它有其他Map没有的subMap()方法,此方法可以返回树的一部分。
本部分TreeMap和TreeSet有些相似,会按照传入的键值升序排列元素,这里主要记录一下Map的遍历方式:
//法1
Collection entries = m.entrySet();
Iterator i = entries.iterator();
while(i.hasNext()) {
Map.Entry e = (Map.Entry) i.next();
System.out.println("Key = " + e.getKey() + ", Value = " + e.getValue());
}
//法2
Iterator iterator = m.keySet().iterator();
while(iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + ": " + m.get(key));
}【注】上述的方法2本人时常犯错,主要如下:
Iterator iterator = m.keySet().iterator();
while(iterator.hasNext()) {
System.out.println(keiterator.next()y + ": " + m.get(iterator.next()));
}注意cur的位置!!,这样会错位一个,到最后一个key时,会出现没有对象的value,即出现java.util.NoSuchElementException异常
1.6.5. 关于具体集合类的选用
集合总共有三大类:Map、List和Set,每一大类中又有各种具体的实现类,不同场景需要我们可以决定到底使用哪种集合类,这对于程序的性能有很大影响。比如ArrayList和LinkedList(前者是基于数组实现,适用于随机存取,后者适用于频繁在列表中部插入、删除操作的场景),再比如ArraySet适用于创建和删除大量Set对象的场合,只支持少量元素,如果需要在Set容纳大量元素,ArraySet性能会很糟糕,所以默认使用HashSet,除非有特殊性能要求,才切换到ArraySet。具体总给书中所讲大致可以得出下面的结论:
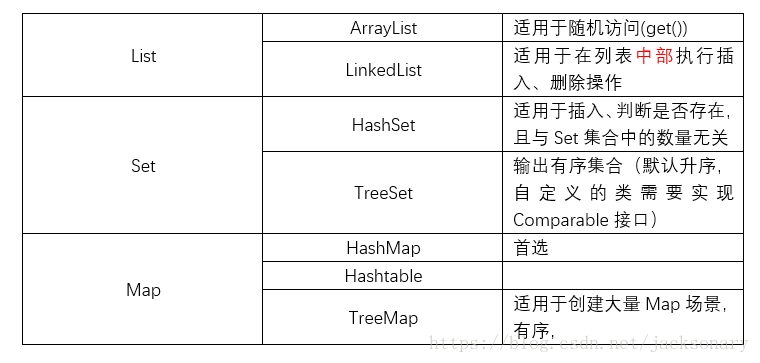
但是注意TreeMap适用于大量创建Map场景并不适用,在jdk1.7版本中,创建1W、10W、100W的Map对象时,TreeMap的表现并不像上述表中描述的那样,下面是创建100W个Map对象的耗时结果:
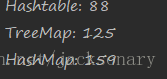
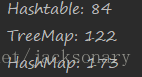
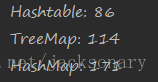
可见Hashtable的表现要比其他两个要好的多。
1.6.6. 排序和搜索等实用操作
将书中的一些工具代码整理如下:
1.随机字符串生成器
static Random r = new Random();
static String ssource = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" +
"abcdefghijklmnopqrstuvwxyz";
static char[] src = ssource.toCharArray();
public static String randString(int length) {
char[] buf = new char[length];
int rnd;
for (int i = 0; i < length; i++) {
rnd = Math.abs(r.nextInt())%src.length;
buf[i] = src[rnd];
}
return new String(buf);
}2.排序和搜索
先看数组的操作:Arrays.binarySearch()可以搜索出对象的索引号,Arrays.sort(b)可以对数组b进行排序(升序且对于String类型大写始终排在小写前面,估计是按ASCII码排的),当然Arrays.sort()方法也可以接受比较器的参数,比如下面的案例:
public class AlphaComp implements Comparator {
//若o1>o1返回整数,若o1=o2返回0,若o1<o2返回负整数
@Override
public int compare(Object o1, Object o2) {
String s1 = ((String)o1).toLowerCase();
String s2 = ((String)o2).toLowerCase();
return s1.compareTo(s2);
}
public static void main(String[] args) {
String[] s = Array1.randStrings(4, 10);
Array1.print(s);
AlphaComp ac = new AlphaComp();
Arrays.sort(s, ac);
Array1.print(s);
int loc = Arrays.binarySearch(s, s[3], ac);
System.out.println("Location of " + s[3] + " = " + loc);
}
}书中提及的一句话让我想知道具体的原因,为什么会产生这种情况:
若在执行一次binarySearch()之前不调用 sort(),便会发生不可预测的行为,
其中甚至包括无限循环。
还有一种方式,之前也有说过,使需要比较的自定义类实现Comparable接口,重写其中的compareTo(Object o)方法,比如下面的:
public class CompClass implements Comparable {
private int i;
public CompClass(int ii) {i = ii;};
@Override
public int compareTo(Object o) {
int argi = ((CompClass)o).i;
if(i==argi) return 0;
if(i<argi) return -1;
return 1;
}
public static void print(Object[] a) {
for (int i = 0; i < a.length; i++) {
System.out.print(a[i] + " ");
}
System.out.println();
}
public String toString() {return i + " ";}
public static void main(String[] args) {
CompClass[] a = new CompClass[20];
for (int i = 0; i < a.length; i++) {
a[i] = new CompClass((int)(Math.random()*100));
}
print(a);
Arrays.sort(a);
print(a);
int loc = Arrays.binarySearch(a, a[3]);
System.out.println("Location of " + a[3] + " = " + loc);
}
}再看列表的操作:和数组Arrays类中方式类似,方法基本都存在与Collections类中,连名字基本都一样,下面是一个案例:
public class ListSort {
public static void main(String[] args) {
final int SZ = 20;
List a = new ArrayList();
for (int i = 0; i < SZ; i++) {
a.add(new CompClass((int) (Math.random() * 100)));
}
Collection1.print(a);
Collections.sort(a);
Collection1.print(a);
Object find = a.get(SZ/2);
int loc = Collections.binarySearch(a, find);
System.out.println("Location of " + find + " = " + loc);
List b = new ArrayList();
for (int i = 0; i < SZ; i++) {
b.add(Array1.randString(4));
}
Collection1.print(b);
AlphaComp ac = new AlphaComp();
Collections.sort(b, ac);
Collection1.print(b);
find = b.get(SZ/2);
loc = Collections.binarySearch(b, find, ac);
System.out.println("Location of " + find + " = " + loc);
}
}3.使Collection或Map不可修改
对应不同的集合类有不同的方法,一旦修改为不可修改,那么再对该集合修改就会抛出UnsupportedOperationException异常,对象集合修改方式如下:
Collection c = new ArrayList();
//填充数据...
c = Collections.unmodifiableCollection(c);
List a = new ArrayList();
a = Collections.unmodifiableList(a);
Set s = new HashSet();
s = Collections.unmodifiableSet(s);
Map m = new HashMap();
m = Collections.unmodifiableMap(m);文中也提到在修改前必须用有效的数据进行填充,在上述的代码片中省略了这一步,但是使用时需要填充。
4.同步机制
Collections提供了线程同步机制,和上述的不可修改类似的行为方式,如下:
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());













 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









