








Elasticsearch简称ES,官网对它的介绍是
The Heart of the Elastic Stack. Elasticsearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected.
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它几乎可以提供几乎实时的方式快速存储、搜索和分析大量的数据,它通常用作底层引擎/技术,为具有复杂搜索功能和要求的应用程序提供支持。它是一个分布式、支持Restful搜索以及分析的引擎,是Elastic Stack的核心产品。主要使用场景有:
- 在线网上商城,提供用户搜索你所卖的商品功能。在这个例子中,你可以使用Elasticsearch去存储你的全部的商品目录和存货清单并且提供搜索和搜索自动完成以及搜索推荐功能。
- 收集日志或者业务数据,并且去分析并从这些数据中挖掘寻找市场趋势、统计资料、摘要信息或者反常情况。在这个例子中,你可以使用Logstash(part of the Elasticsearch/Logstash/Kibana stack)去收集、聚合并且解析你的数据,然后通过Logstash将数据注入Elasticsearch。一旦数据进入Elasticsearch,你就可以运行搜索和聚集并且从中挖掘任何你感兴趣的数据。
- 一个价格预警平台,它可以让那些对价格精明的客户指定一个规则,比如:“我相中了一个电子产品,并且我想在下个月任何卖家的这个电子产品的价格低于多少钱的时候提醒我”。在这个例子中,你可以抓取所有卖家的价格,把价格放入Elasticsearch并且使用Elasticsearch的反向搜索(过滤器/抽出器)功能来匹配价格变动以应对用户的查询并最终一旦发现有匹配结果时给用户弹出提示框。
- 有分析学/商业情报的需求并且想快速审查、分析并使用图像化进行展示,并且在一个很大的数据集上查询点对点的问题(试想有百万或千万的记录)。在这个例子中,你可以使用Elasticsearch去存储你的数据然后使用Kibana(part of the Elasticsearch/Logstash/Kibana stack)去构建定制化的仪表盘。这样你就可以很直观形象的了解对你重要的数据。此外,你可以使用Elasticsearch的集成功能,靠你的数据去展现更加复杂的商业情报查询。
Elasticsearch底层Lucene开源库,其实它就是帮我们写了代码去调用Lucene的接口,提供了REST API的操作接口,JDK版本至少是JDK 8才能安装使用,具体介绍及其使用见官网文档
1. 启动
启动Elasticsearch:elasticsearch-6.4.0\bin\elasticsearch.bat,可以在DOS窗口看到启动信息,最终会看到类似于下面的一行(主要是节点名[V8JnETy]可能会不同):
[2018-09-01T10:14:11,633][INFO ][o.e.n.Node ] [V8JnETy] started
在浏览器端访问9200端口(或者直接在powershell中输入curl http://localhost:9200命令),得到一个JSON格式的说明信息:
{
"name" : "V8JnETy",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Pkr4spGJTMy0K5BQ4rn5GA",
"version" : {
"number" : "6.4.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "595516e",
"build_date" : "2018-08-17T23:18:47.308994Z",
"build_snapshot" : false,
"lucene_version" : "7.4.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
这里可以手动更改集群cluter和节点名node,命令如下:
./elasticsearch -Ecluster.name=my_first_cluster -Enode.name=my_first_node
节点名为V8JnETy、集群名字为elasticsearch(默认名),以及版本信息;
默认情况Elasticsearch只允许本机访问,如果需要远程访问,需要配置elasticsearch-6.4.0\config\elasticsearch.yml中的network.host属性(大约在55行处),将其改为network.host: 0.0.0.0,表示任何IP都可以访问,实际开发中会设置为具体的IP。
1.1 ES的集群配置
ES的集群配置(都是修改ES的配置文件elasticsearch.yml)主要分为:主节点配置和从节点配置。
配置主节点jack_master:
# 配置分布式主节点
# 集群名
cluster.name: jack
# 节点名
node.name: jack_master
# 是否为主节点
node.master: true
# 绑定IP
network.host: 127.0.0.1
然后再次解压ES安装包到其他目录,每解压一个出来就可以配置一个ES的从节点,比如这里是解压两次就可以配置2个从节点,分别修改它们的配置文件让它们加入到集群jack中:
配置从节点jack_slave1:
# 配置从节点的信息
# 集群名一定要和主节点所在集群名一致,默认集群按名字匹配
cluster.name: jack
# 节点名
node.name: jack_slave1
# 绑定IP
network.host: 127.0.0.1
# 默认端口是9200,如果不配置就会和主节点端口冲突
http.port: 8100
# 用于寻找集群,不加这个配置这个节点是游离在集群之外的
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
配置从节点jack_slave2:
# 配置从节点的信息
# 集群名一定要和主节点所在集群名一致,默认集群按名字匹配
cluster.name: jack
# 节点名
node.name: jack_slave2
# 绑定IP
network.host: 127.0.0.1
# 默认端口是9200,如果不配置就会和主节点端口冲突
http.port: 8200
# 用于寻找集群,不加这个配置这个节点是游离在集群之外的
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
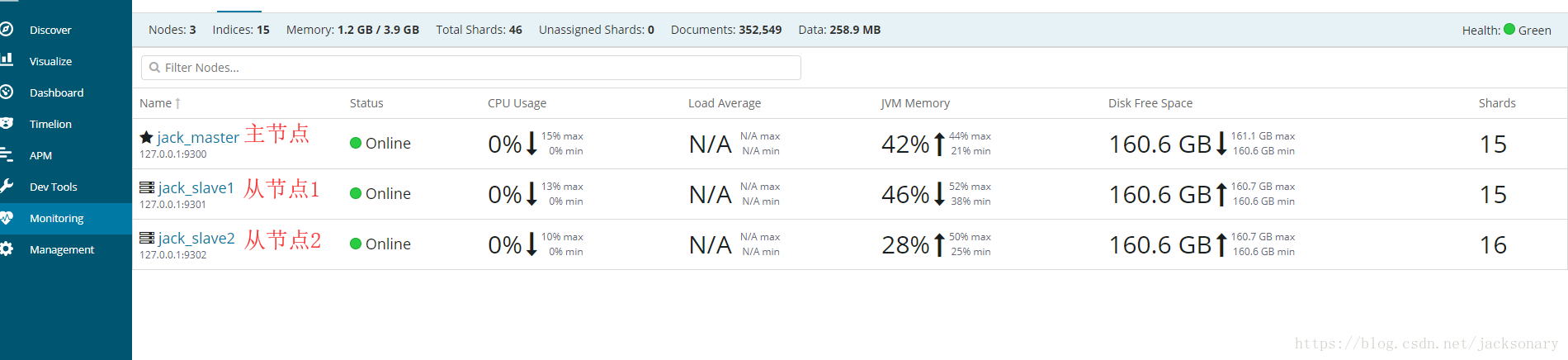
就照着上面的步骤ES可以轻松实现扩容,启动的时候注意节点启动顺序,先主节点再从节点再Kibana,在Kibana监控页面可以看到启动的三个节点,启动界面和监控页面如下:
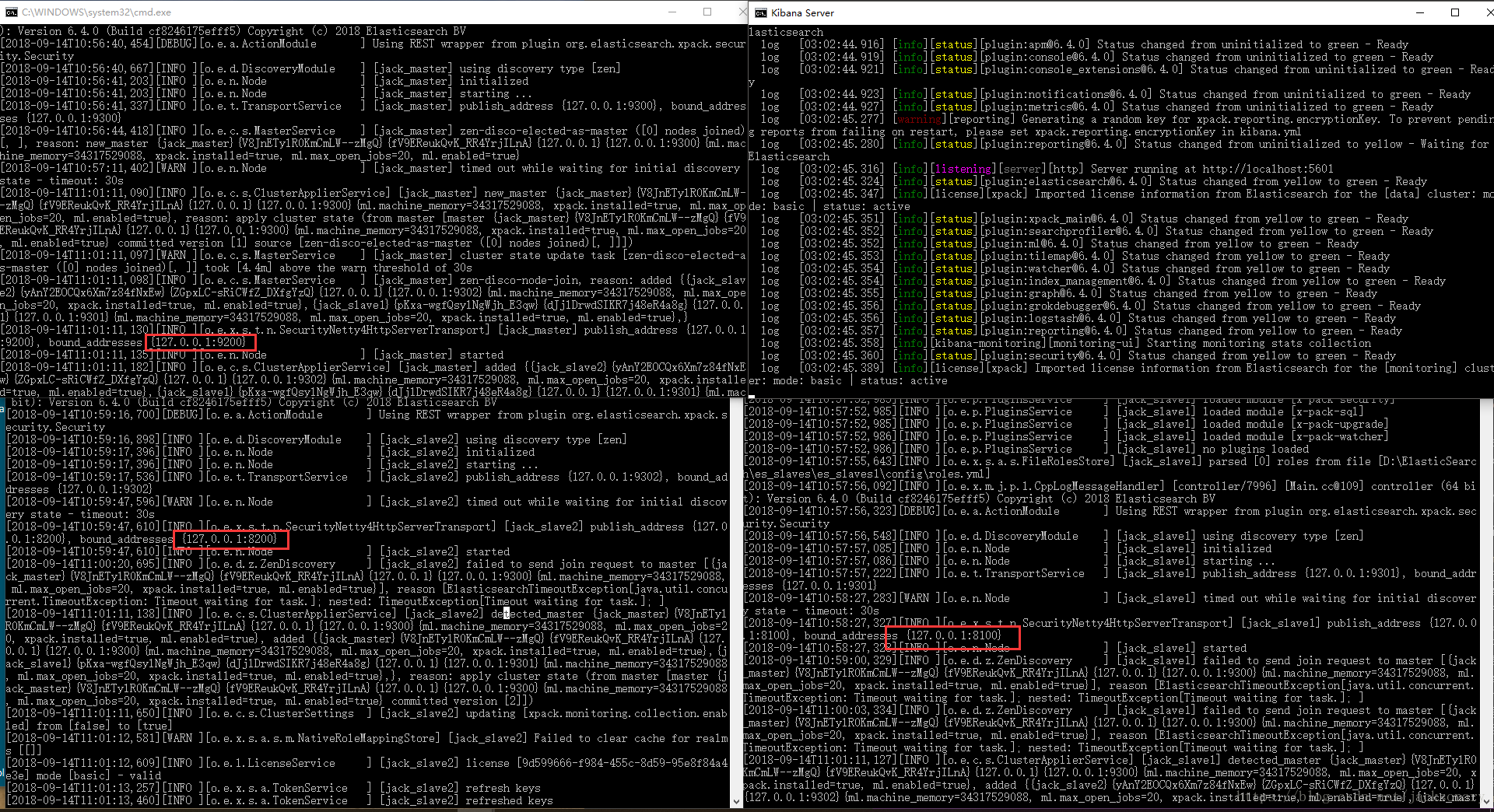
【问题】
后来在启动集群时(场景:主节点jack_master启动后无警告,在启动从节点jack_slave1时,主节点窗口抛出此警告),出现如下的警告:
[2018-11-16T08:53:31,911][WARN ][o.e.d.z.ElectMasterService] [jack_master] value for setting "discovery.zen.minimum_master_nodes" is too low. This can result in data loss! Please set it to at least a quorum of master-eligible nodes (current value: [-1], total number of master-eligible nodes used for publishing in this round: [2])
上述警告是因为默认情况下discovery.zen.minimum_master_nodes=1一台服务器只能有一个主节点(选举一个Master需要多少节点,即最少候选节点),这个参数根据经验一般设置为N/2+1(若不为整数,则向下取整),N为集群中节点的数量。这个参数也是我在后面学习过程中导致脑裂的原因,扯得有点远了,回来上述的问题,可以配置上述参数为2即可(我本地是3个节点)。
1.2 ES配置
ES有很好的默认值,所以只需要很少的配置,可以使用Cluster Update Settings API在正在运行的群集上更改大多数设置。主要是指本地的一些配置,借助于配置文件进行配置,主要分为3块:
elasticsearch.yml,ES的配置文件;jvm.options,ES的JVM配置文件;log4j2.properties,ES的日志配置文件;
关于配置文件的路径,默认是解压缩包的解压路径$ES_HOME/config,但是具体的配置路径可以通过ES_PATH_CONF环境变量来改变,比如:
ES_PATH_CONF=/path/to/my/config ./bin/elasticsearch
ES的配置文件是yaml格式,下面是配置data和logs目录的方法:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
环境变量还可以使用${...}这样的形式配置,比如:
node.name: ${HOSTNAME}
network.host: ${ES_NETWORK_HOST}
ES配置文件中,可配置的参数有(汇总,来源于网络):
# es集群名,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群
cluster.name: elasticsearch
# 节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,6.4.0版本中好像已经没有这个文件了
node.name: "Franz Kafka"
# 候选资格,表示该节点是否有资格被选举成为master,默认是true,es默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
node.master: true
# 表示该节点是否存储索引数据,默认为true
node.data: true
# 设置索引分片个数,默认为5
index.number_of_shards: 5
# 设置索引副本个数,默认为1
index.number_of_replicas: 1
# 设置ES配置文件的存储路径,默认是es根目录下的config文件夹下
path.conf: /path/to/conf
# 设置索引数据的存储路径,默认是es根目录下的data文件夹下,可以设置多个存储路径,用逗号隔开,例:path.data: /path/to/data1,/path/to/data2
path.data: /path/to/data
# 设置临时文件的存储路径,默认是es根目录下的work文件夹
path.work: /path/to/work
# 设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.logs: /path/to/logs
# 设置插件的存放路径,默认是es根目录下的plugins文件夹
path.plugins: /path/to/plugins
# 设置ES可以是否可以锁定内存,因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许ES的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令
bootstrap.mlockall: true
# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0
network.bind_host: 192.168.0.1
# 设置其它节点和该节点交互的ip地址(真实IP),如果不设置它会自动判断
network.publish_host: 192.168.0.1
# 这个参数是用来同时设置bind_host和publish_host上面两个参数
network.host: 192.168.0.1
# 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
# 设置是否压缩tcp传输时的数据,默认为false,不压缩
transport.tcp.compress: true
# 设置对外服务的http端口,默认为9200
http.port: 9200
# 设置内容的最大容量,默认100mb
http.max_content_length: 100mb
# 是否使用http协议对外提供服务,默认为true,开启
http.enabled: false
# gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说
gateway.type: local
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 1
# 设置初始化数据恢复进程的超时时间,默认是5分钟
gateway.recover_after_time: 5m
# 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复
gateway.expected_nodes: 2
# 初始化数据恢复时,并发恢复线程的个数,默认为4
cluster.routing.allocation.node_initial_primaries_recoveries: 4
# 添加删除节点或负载均衡时并发恢复线程的个数,默认为4
cluster.routing.allocation.node_concurrent_recoveries: 2
# 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制
indices.recovery.max_size_per_sec: 0
# 来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5
indices.recovery.concurrent_streams: 5
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 1
# 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错
discovery.zen.ping.timeout: 3s
# 设置是否打开多播发现节点,默认是true
discovery.zen.ping.multicast.enabled: false
# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
1.3 ES的JVM配置
ES的java虚拟机设置,很少需要手动配置,如果需要改动,绝大部分是改动堆的大小,设置JVM首选方式是配置jvm.options文件,这个配置文件包含了一系列分隔线分隔的JVM参数,使用的是一种特殊的语法,具体规则如下:
- 仅包含空格的行将被忽略;
- 以
#开头的行被视作注释; - 以
-开头的行被视作JVM选项,这个选项独立于JVM而应用,如-Xmx2g; - 以数字开头后面接
-:符号的,也被视作JVM选项,但仅在JVM的版本大于等于这个数字时才使用,如8-:-Xmx2g(大于等于JDK8版本才适用); - 以数字开头后面接
:-符号的,也被视作JVM选项,但仅在JVM版本和数字相同时才适用,如8:-Xmx2g(仅适用于JDK8); - 以数字开头后接
-数字:的,也被视作JVM想象,但仅在JVM版本在这两个数字区间内,如8-9:-Xmx2g; - 除此之外的所有行都不生效;
1.4 ES的安全配置
ES中有些配置是敏感的,仅通过系统文件权限来保护是不够的,为此,Elasticsearch提供了一个密钥库和elasticsearch-keystore工具来管理密钥库中的设置。这些设置就像elasticsearch.yml中的常规配置一样,需要在集群中的每个节点进行指定,目前,所有安全设置都是基于特定于节点的设置,每个节点上的值必须相同。
1.5 ES的日志配置
ES采用log4j 2作日志管理,log4j 2可以使用log4j2.properties文件进行配置,ES就暴露出三个属性:${sys:es.logs.base_path}(解析为日志目录)、${sys:es.logs.cluster_name}(解析为集群名,在默认配置中用作日志文件名的前缀)和${sys:es.logs.node_name}(如果通过node.name显式的设置了节点名称,将解析为节点名),可以在配置文件中引用来确定日志文件的位置。
加设置ES的根目录是/var/log/elasticsearch,集群名为production,下面是ES中log4j 2的部分配置:
# 配置RollingFile的附加器
appender.rolling.type = RollingFile
appender.rolling.name = rolling
# %ES_Home%/节点名.log就是日志文件的路径和名字,即/var/log/elasticsearch/production.log
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] %marker%.-10000m%n
# 滚动日志到/var/log/elasticsearch/production-yyyy-MM-dd-i.log,日志将在每个卷上压缩,i递增
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling.policies.type = Policies
# 使用基于时间的滚动策略
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
# 每1天滚动日志
appender.rolling.policies.time.interval = 1
# 在日界上对齐卷(而不是每隔二十四小时滚动)
appender.rolling.policies.time.modulate = true
# 使用基于大小的滚动策略
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
# 256 MB后滚动日志
appender.rolling.policies.size.size = 256MB
# 滚动日志时使用删除操作
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
# 仅删除与文件模式匹配的日志
appender.rolling.strategy.action.condition.type = IfFileName
# 该模式仅删除主日志
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
# 仅在我们累积了太多压缩日志时才删除
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
# 压缩日志的大小条件为2 GB
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB
【注意】可以使用.gz替换appender.rolling.filePattern属性中的.zip(使用zip格式压缩滚动日志),如果删除.gz扩展名,则日志将不会在滚动时进行压缩。
如果想指定时间段内保留日志文件,可以使用带有删除操作的翻转策略。
# 配置DefaultRolloverStrategy
appender.rolling.strategy.type = DefaultRolloverStrategy
# 配置删除操作以处理翻转
appender.rolling.strategy.action.type = Delete
# Elasticsearch日志的基本路径
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
# 处理翻转时应用的条件
appender.rolling.strategy.action.condition.type = IfFileName
# 从基本路径中删除文件(和全局${sys:es.logs.cluster_name}-*匹配的),这只需要删除已滚动的Elasticsearch日志,但不能删除已弃用和慢速日志
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
# 应用于与glob匹配的文件的嵌套条件
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
# 保留日志七天
appender.rolling.strategy.action.condition.nested_condition.age = 7D














 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









