







android Binder浅析
简介
Linux系统下每个进程都是拥有自己独立内存空间,相互之间隔离,不能直接去使用对方的进程内存空间;但是进程之间某些业务场景需要通信,而Linux进程间通信方式很多,包括共享变量 管道 信号量 消息队列以及Socket,但是在Android系统上,基于其移动端特性的考虑,引入了Binder跨进程通信,实现数据互通.
得益于互联网上的分享精神,才能够让我快速了解Binder通信机制的原理,在此感谢老罗的技术分享,本文在此基础进行Binder总结,对于一些细节性的问题,可以参考老罗的文章!
讲解Binder通信原理之前先谈谈相关的内核知识!
内核空间和用户空间
从32位操作系统的角度来看,它的虚拟内存空间范围可以寻址为2的32次方,也就是4G的寻址空间,而操作系统的内核程序,独立与其他的应用程序,可以访问受保护的资源以及硬件资源,而普通的程序则受到诸多限制,所以从地址上划分,将4G的空间高位1GB划分为内核空间,低位3GB的空间划分为用户空间,由各个进程使用,所以1GB的内核空间由各个进程共享,而4GB的用户空间则是各个进程划分使用
内核态和用户态
当一个进程在用户空间时它就是用户态,当他需要使用一些受保护的资源时,它会发起相应的系统调用,交给内核去之执行,这个时候就进入了内核态,内核态时对系统的各个资源访问将不受限制,随意访问,所以从系统安全的角度而言,划分两个空间是为了使进程不能随意执行内核指令,造成系统异常的保护措施
Binder实现IPC基础原理
通常两个AB进程通信在进程间通信时,数据会在A进程将数据从进程空间拷贝到内核空间,在内核空间传递给B进程,在B进程中再把数据从内核空间拷贝到进程空间,这样数据发生了一次传递,两次拷贝;而Binder通过其驱动实现同一物理页面同时映射内核和进程空间,减少一次拷贝,提高了数据传递效率.以下是Binder通信的框架模型:
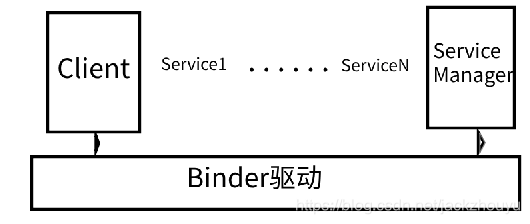
Binder通信分为三端:
- ServiceManager 所有服务的管理者
- 某一个Service服务端(android内部有很多Service)
- 需要服务的Client客户端
启动步骤
- 启动ServiceManager,并且通知底层Binder驱动,自己是所有服务的管理者
- 启动某一个具体的服务,并且将自己加入到ServiceManager的服务列表中去
- 客户端通过服务名,如media.player字符串去ServiceManager的服务list去查找,找到需要的Service服务后(这里只是拿到的一个代理BpService),使用代理服务去发起服务调用
按照以上三个步骤来具体讲解是如何去是实现的
启动ServiceManager
入口在service_manager.c的main函数里面
int main(int argc, char** argv)
{
struct binder_state *bs;
//打开binder驱动
bs = binder_open("/dev/binder", 128*1024);
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
//svcmgr_handler是一个函数指针
binder_loop(bs, svcmgr_handler);
}
从上面代码可以知道,首先会打开binder文件,返回一个binder_state数据结构的结构体,然后让通知binder驱动让自己成为binder通信上下文的管理者,最后开启一个loop循环,实时检测加入的服务,这里我们先看第一步,打开binder文件中去:
第一部分 — binder_open
struct binder_state *binder_open(const char* driver, size_t mapsize)
{
struct binder_state *bs;
struct binder_version vers;
//分配一个binder_state结构体
bs = malloc(sizeof(*bs));
if (!bs) {
errno = ENOMEM;
return NULL;
}
//打开binder文件,这个open函数最终会执行到binder驱动程序的open函数中去
bs->fd = open(driver, O_RDWR | O_CLOEXEC);
if (bs->fd < 0) {
fprintf(stderr,"binder: cannot open %s (%s)\n",
driver, strerror(errno));
goto fail_open;
}
//查询binder版本
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr,
"binder: kernel driver version (%d) differs from user space version (%d)\n",
vers.protocol_version, BINDER_CURRENT_PROTOCOL_VERSION);
goto fail_open;
}
bs->mapsize = mapsize;
//映射的内存地址,mmap函数进入binder驱动的mmap函数中去
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
if (bs->mapped == MAP_FAILED) {
fprintf(stderr,"binder: cannot map device (%s)\n",
strerror(errno));
goto fail_map;
}
return bs;
fail_map:
close(bs->fd);
fail_open:
free(bs);
return NULL;
}
以上的binder_open函数完成三件事情:
1. 打开binder驱动文件
2. 查询binder驱动系统版本
3. 映射binder驱动的映射地址
以上三个步骤都会进入binder驱动程序,进入内核态操作,所以我们要进入binder驱动程序去看看它做了哪些事情?进入之前我们必须了解会用到的几个结构体
Binder_State结构体主要是记录内存映射其实地址以及内存大小;
struct binder_state
{
int fd; //驱动文件标识
void *mapped; //映射的首地址
size_t mapsize;
};
打开binder文件函数和映射内存地址最终会调用到binder驱动程序的binder_open和binder_map函数,在底层驱动这块,主要是会创建一些结构体,为其赋值,而后在进程通信时,多数都是去判断对应的结构提内是否有任务,然后在针对性的去处理业务逻辑,这也应征了程序=数据结构+算法,所以先来看几个结构体吧!结构体的意思用法及意思请看代码注释:
binder驱动程序护当前进程下的binder状态的结构体,管理当前进程binder内存映射\内存管理\线程管理等等等很多东西
struct binder_proc {
struct hlist_node proc_node;
struct rb_root threads; 来自客户端的线程请求
struct rb_root nodes;
struct rb_root refs_by_desc;
struct rb_root refs_by_node;
int pid;
struct vm_area_struct *vma; 进程空间内存结构体
struct task_struct *tsk;
struct files_struct *files;
struct hlist_node deferred_work_node;
int deferred_work;
void *buffer; 内核空间映射起始地址
ptrdiff_t user_buffer_offset; 内核空间与进程空间地址偏移,两个空间地址通过这个偏移可以快速寻址
struct list_head buffers; 映射的虚拟内存通过一个个节点组成链表管理,加入到这个buffers
struct rb_root free_buffers; 空闲的内存节点
struct rb_root allocated_buffers; 被使用的内存节点
size_t free_async_space;
struct page **pages; 物理页面描述
size_t buffer_size; 内存大小
uint32_t buffer_free;
struct list_head todo;
wait_queue_head_t wait;
struct binder_stats stats;
struct list_head delivered_death;
int max_threads; 允许被访问的线程最大数
int requested_threads;
int requested_threads_started;
int ready_threads;
long default_priority;
};
对映射的内存采用一段一段的方式管理,每段用binder_buffer表示,
通过binder_buffer的entry节点连入到binder_proc的buffers
节点中去,同时binder_buffer的rb_node节点连入到binder_proc
的free_buffers和allocated_buffers节点,这两个节都是红黑树结构
,用于管理使用和未使用的;
struct binder_buffer {
struct list_head entry; /* free and allocated entries by addesss */
struct rb_node rb_node; /* free entry by size or allocated entry */
/* by address */
unsigned free : 1;
unsigned allow_user_free : 1;
unsigned async_transaction : 1;
unsigned debug_id : 29;
binder_transaction驱动层进程数据交互格式
struct binder_transaction *transaction;
传输数据时目标binder节点
struct binder_node *target_node;
保存的是binder_transaction_data中的data_size
size_t data_size;
保存的是binder_transaction_data中的offsets_size
size_t offsets_size;
保存的是binder_transaction_data中的buffer和offsets的数据,buffer在前,offsets在后
uint8_t data[0];
};
理解了上述结构体,我们就可以大致看得懂Binder的驱动程序了,先看看binder_open函数
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\n",
current->group_leader->pid, current->pid);
分配一个binder_proc的结构体,并且是在内核空间中
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
current可以理解为一个描述锁对象的东西
proc->tsk = current;
proc->vma_vm_mm = current->mm;
初始化任务队列,如果todo中有数据,说明有待处理的任务需要去处理
INIT_LIST_HEAD(&proc->todo);
初始化条件变量,用于阻塞进程
init_waitqueue_head(&proc->wait);
设置默认权限
proc->default_priority = task_nice(current);
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
proc->context = &binder_dev->context;
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
最后把proc赋给flip文件,以后需要时直接从flip中的private_data中去拿即可
filp->private_data = proc;
/**省略部分代码*/
return 0;
}
小结一下,binder_open主要就是在内核空间创建一个binder_proc结构体,并且为其初始化赋值,如task_current任务 待处理列表todo 阻塞条件变量wait等等,最后再把binder_proc赋值给flip的private_data保存,以后需要时拿出来使用即可
回到上面binder_open执行完后,开始进行mmap内存映射,这里最终会进入到binder驱动程序的binder_mmap函数,如下:
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
拿到上一个binder_open创建好的binder_proc结构体
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
vma是vm_area_struct类型,用于管理进程空间的内存
这里控制了需要映射的进程空间不能大于4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
如果是禁止映射的话,这里会返回失败
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
binder_proc的buffer指针指向的是内核空间映射内存收地址,如果收地址不为空,
说明已经映射了,不会再次映射了
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
获取映射的内核空间内存,赋值给area
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
映射内核空间首地址给proc的buffer
proc->buffer = area->addr;
计算映射的内核空间内存地址与进程空间地址之间的差值,以后两个空间寻址,直接用这个
差值快速寻址
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing()) {
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) {
pr_info("binder_mmap: %d %lx-%lx maps %p bad alignment\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
}
}
#endif
pages是用来描述物理内存结构的
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
binder_update_page_range函数主要是建立好同一物理页面同时
映射内核空间和进程空间,将映射的内核空间内存和进程空间内存关联
起来,因为这些内存都是划分成一个个结构体节点管理的,所以要把两个
关联起来
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
/**省略非关键部分代码**/
return ret;
}
小结一下:binder_mmap函数主要是映射好内核空间和进程空间内存,将他们组织起来,并把一些分配好的变量和引用赋值到binder_proc里面去,以后需要使用的时候也从binder_proc去拿就行了
第二部分 — binder_become_context_manager
让自己成为binder驱动的管理者
首先,该函数在framework层的binder.c里面,如下:
int binder_become_context_manager(struct binder_state *bs)
{
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}
ioctl意思可以理解为io控制函数,使用它可以进行系统调用,直接与系统内核打交道,这个函数最终会执行到binder驱动的binder_ioctl函数去,讲解这个函数之前不得不先了解几个结构体:
binder_thread
struct binder_thread {
当前线程所属进程的proc
struct binder_proc *proc;
rb_node节点连入binder_proc的threads节点链接
struct rb_node rb_node;
int pid;
当前线程状态
int looper;
正在处理的事务
struct binder_transaction *transaction_stack;
该线程待处理的数据列表
struct list_head todo;
uint32_t return_error; /* Write failed, return error code in read buf */
uint32_t return_error2; /* Write failed, return error code in read */
/* buffer. Used when sending a reply to a dead process that */
/* we are also waiting on */
wait_queue_head_t wait;
struct binder_stats stats;
};
然后,进入到binder驱动的binder_ioctl函数中去,如下:
flip就是打开binder驱动文件索引,cmd是命令参数BINDER_SET_CONTEXT_MGR arg命令参数
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
if (unlikely(current->mm != proc->vma_vm_mm)) {
pr_err("current mm mismatch proc mm\n");
return -EINVAL;
}
trace_binder_ioctl(cmd, arg);
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
binder_lock(__func__);
获取binder_thread,此函数会从binde_proc的threads变量去找,thread内部是一个红黑树结构,
统计了所有线程请求,第一次进去是找不到的,所以在函数内部为其创建一个新的binder_thread
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
所有进来的请求都是通过cmd条件去处理,这里省略了其他case,我们只关心BINDER_SET_CONTEXT_MGR条件
switch (cmd) {
case BINDER_SET_CONTEXT_MGR:
ret = binder_ioctl_set_ctx_mgr(filp);
if (ret)
goto err;
break;
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
/*省略部分code*/
return ret;
}
设置binder上下文管理者
static int binder_ioctl_set_ctx_mgr(struct file *filp)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
struct binder_context *context = proc->context;
kuid_t curr_euid = current_euid();
如果已经有管理者了,就直接退出
if (context->binder_context_mgr_node) {
pr_err("BINDER_SET_CONTEXT_MGR already set\n");
ret = -EBUSY;
goto out;
}
ret = security_binder_set_context_mgr(proc->tsk);
if (ret < 0)
goto out;
if (uid_valid(context->binder_context_mgr_uid)) {
if (!uid_eq(context->binder_context_mgr_uid, curr_euid)) {
pr_err("BINDER_SET_CONTEXT_MGR bad uid %d != %d\n",
from_kuid(&init_user_ns, curr_euid),
from_kuid(&init_user_ns,
context->binder_context_mgr_uid));
ret = -EPERM;
goto out;
}
} else {
context->binder_context_mgr_uid = curr_euid;
}
创建本进程的proc的binder实体为管理者
context->binder_context_mgr_node = binder_new_node(proc, 0, 0);
if (!context->binder_context_mgr_node) {
ret = -ENOMEM;
goto out;
}
因为这个binder实体被context引用,所以要给他相关的引用计数加1
context->binder_context_mgr_node->local_weak_refs++;
context->binder_context_mgr_node->local_strong_refs++;
context->binder_context_mgr_node->has_strong_ref = 1;
context->binder_context_mgr_node->has_weak_ref = 1;
out:
return ret;
}
小结一下:设置binder驱动上下文管理者,进入binder驱动,从打开的binder文件索引中取出binder_proc,并从该结构体中取出当前线程的binder_thread,这里因为第一次进入,会创建一个新的binder_thread,然后根据cmd命令进入binder_ioctl_set_ctx_mgr函数,创建一个binder实体,并赋值给binder_proc的context上下文管理
第三部分 — 开启循环binder_loop
这里开启循环后,将监听来自客户端的请求,主要是接受一些Service的注册和查找
同上,讲解下面代码时要先看看几个会用到的数据结构,才能更好的理解代码:
binder_write_read 位于kernel下的binder.h中
struct binder_write_read {
binder_size_t write_size; /* bytes to write */
binder_size_t write_consumed; 已消耗的长度
binder_uintptr_t write_buffer; 写入数据地址
binder_size_t read_size; /* bytes to read */
binder_size_t read_consumed; /* bytes consumed by driver */
binder_uintptr_t read_buffer; 读取数据地址
};
上面的write_buffer和read_buffer一般都是指向binder_transaction_data结构(记住一般哈,也可以不是哈),binder_transaction_data才是真正保存数据参数的结构,一般binder之间的数据传递都会用到这两个数据结构体,在上层会先把传递参数封装为binder_transaction_data,在封装为binder_write_read结构体,然后进入到binder驱动层时,会依次解开binder_write_read和binder_transaction_data
继续,我们看看binder_loop这块是如何实现的,细节都写到注释里面去了:
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
写入命令为BC_ENTER_LOOPER
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
if (res == 0) {
ALOGE("binder_loop: unexpected reply?!\n");
break;
}
if (res < 0) {
ALOGE("binder_loop: io error %d %s\n", res, strerror(errno));
break;
}
}
}
int binder_write(struct binder_state *bs, void *data, size_t len)
{
struct binder_write_read bwr;
int res;
将数据的读取命令弄为0
bwr.write_size = len;
bwr.write_consumed = 0;
bwr.write_buffer = (uintptr_t) data;
bwr.read_size = 0;
bwr.read_consumed = 0;
bwr.read_buffer = 0;
通过ioctl写入binder驱动
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
fprintf(stderr,"binder_write: ioctl failed (%s)\n",
strerror(errno));
}
return res;
}
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
thread = binder_get_thread(proc);
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
}
}
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
将用户空间的参数拷贝到内核空间
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"%d:%d write %lld at %016llx, read %lld at %016llx\n",
proc->pid, thread->pid,
(u64)bwr.write_size, (u64)bwr.write_buffer,
(u64)bwr.read_size, (u64)bwr.read_buffer);
如果写入参数大于0就调用binder_thread_write参数
if (bwr.write_size > 0) {
binder_thread_write内部也是switch-case语句,根据传入的bwr的命令来条件执行
这里主要进去后进入BC_ENTER_LOOPER,然后对binder_thread的loop变量赋值为
enter_loop循环
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
因为read_size为0,所以就不会执行了
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"%d:%d wrote %lld of %lld, read return %lld of %lld\n",
proc->pid, thread->pid,
(u64)bwr.write_consumed, (u64)bwr.write_size,
(u64)bwr.read_consumed, (u64)bwr.read_size);
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
写入的第一个命令是进入循环到此为止,后面进入循环loop后ioctl(bs->fd, BINDER_WRITE_READ, &bwr)也是读写命令,不同的是这次参数bwr的read_size有值了,所以在binder驱动层执行binder_ioctl_write_read函数时,会进入到binder_thread_read函数,如下:
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
/**/
主要是遍历当前线程的todo待处理事项,有就拿出来处理,然后根据命令cmd去条件执行
当然,里面还涉及到一些阻塞wait中断因子,因为不可能一直遍历消耗CPU资源
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
if (!list_empty(&thread->todo)) {
w = list_first_entry(&thread->todo, struct binder_work,
entry);
} else if (!list_empty(&proc->todo) && wait_for_proc_work) {
w = list_first_entry(&proc->todo, struct binder_work,
entry);
} else {
/* no data added */
if (ptr - buffer == 4 &&
!(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN))
goto retry;
break;
}
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work);
} break;
case BINDER_WORK_TRANSACTION_COMPLETE: {
/***/
} break;
case BINDER_WORK_NODE:
break;
}
小结一下:binder_thread_read和binder_thread_write是binder底层很重要的两个函数,binder通信时进行数据读写时都会用到这两个函数,在binder_thread_write函数中,一般会先找到target目标的binder_proc,将数据事务拷贝到target的binder_proc去,另一端读取时又从自己的binder_proc中取出数据,然后拷贝给自己的用户空间去执行
总结
至此,我们Binder第一步完成了,ServiceManager启动了,进入循环体后等待其他端的来访问了
内核中的内存分配指令
void *kmalloc(size_t size, gfp_t flags);在内核中分配size个字节的内存,该内存与物理内存存在连续的一一对应关系,只是有一个固定的偏移,分配地址不能超过128k,flags为分配的状态标志:
GFP_ATOMIC —— 分配内存的过程是一个原子过程,分配内存的过程不会被(高优先级进程或中断)打断;
GFP_KERNEL —— 正常分配内存;
GFP_DMA —— 给 DMA 控制器分配内存,需要使用该标志(DMA要求分配虚拟地址和物理地址连续)。
kzmalloc与kmalloc类似,只是分配内存后默认为其赋值为0
内核内存分配指令,分配的虚拟内存空间是连续的,但是在物理内存上则不一定是连续的,而且分配内存大小也没有限制,分配大的内存的时候可以用这个指令
Binder底层API
interface_cast
android8.0环境下
位于/frameworks/native/libs/binder/include/binder/IInterface.h
template<typename INTERFACE>
inline sp<INTERFACE> interface_cast(const sp<IBinder>& obj)
{
return INTERFACE::asInterface(obj);
}
该方法用于调用者泛型自身的asInterface方法,一般是对于obj的转换成自己需要的类型;在IServiceManager里面有用到过,在其内部是对obj再次封装成自己的类型BpServiceManager,也就是他的代理类
宏定义DECLARE_META_INTERFACE和IMPLEMENT_META_INTERFACE
/frameworks/native/libs/binder/IInterface.cpp
声明了这两个宏定义,前者自动为类添加一些属性和方法说明,后者则自动为属性赋值以及方法的具体实现,如下是两个宏定义的具体声明:
#define DECLARE_META_INTERFACE(INTERFACE) \
//为INTERFACE这个类声明一个类型为String16的字符串descriptor
static const ::android::String16 descriptor; \
//声明一个函数为asInterface(sp<IBinder>)的方法
static ::android::sp<I##INTERFACE> asInterface( \
const ::android::sp<::android::IBinder>& obj); \
//理解同上
virtual const ::android::String16& getInterfaceDescriptor() const; \
//##意思为字符串拼接,即声明一个IINTERFACE的构造方法和析构方法
I##INTERFACE(); \
virtual ~I##INTERFACE(); \
#define IMPLEMENT_META_INTERFACE(INTERFACE, NAME) \
//为descriptor赋值为NAME
const ::android::String16 I##INTERFACE::descriptor(NAME); \
const ::android::String16& \
I##INTERFACE::getInterfaceDescriptor() const { \
return I##INTERFACE::descriptor; \
} \
//asInterface方法的具体实现
::android::sp<I##INTERFACE> I##INTERFACE::asInterface( \
const ::android::sp<::android::IBinder>& obj) \
{ \
::android::sp<I##INTERFACE> intr; \
if (obj != NULL) { \
//queryLocalInterface是从sp里面获取真实对象,可理解为java的弱引用
intr = static_cast<I##INTERFACE*>( \
obj->queryLocalInterface( \
I##INTERFACE::descriptor).get()); \
//没有获取到就new一个,Bp的意思就是Binder Proxy,实质就是一个代理类
if (intr == NULL) { \
intr = new Bp##INTERFACE(obj); \
} \
} \
return intr; \
}
是不是很方便,两个宏定义就自动添加了许多东西
C API
void* mmap ( void * addr , size_t len , int prot , int flags , int fd , off_t offset )
文件映射函数,可以将文件或者对象映射到内存中,然后对映射内存进行读写操作,而不需要去read/write读写函数操作文件(这只是mmap其中一种使用目的)
addr: 映射区的开始地址,设置为0时表示由系统决定映射区的起始地址。
len: 映射区的长度。//长度单位是 以字节为单位,不足一内存页按一内存页处理
prot: 期望的内存保护标志,不能与文件的打开模式冲突
PROT_EXEC //页内容可以被执行
PROT_READ //页内容可以被读取
PROT_WRITE //页可以被写入
PROT_NONE //页不可访问
flags: 指定映射对象的类型,映射选项和映射页是否可以共享。
MAP_FIXED //使用指定的映射起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
MAP_SHARED //与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。
更多选项请点击
fd:有效的文件描述词。一般是由open()函数返回,其值也可以设置为-1,此时需要指定flags参数中的MAP_ANON,表明进行的是匿名映射。
off_toffset:被映射对象内容的起点。
int ioctl(int fd, ind cmd, …)
ioctl(inout/output control)用于设备输入输出控制的系统调用
fd: 打开设备的文件标识符
cmd: 操作的命令
后面的参数就是这个命令所需要的参数















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











