









要实现一个Http服务器并不是一件容易的事情,需要对网络IO十分熟悉,并且对Http协议的规范了如指掌。Http规范可以参考我的上一篇文章《一、Http协议解析》。
实现Http服务器并不是短短几十行代码就能实现的,当然,你要做得十分简陋我也就不多说了。所以我就不把大量的代码给贴出来,让人觉得长篇大论似的。这里我用图文的形式,尽量把Http服务器的实现过程详细的展示出来,希望做到言简意赅。
之前对Http规范的文章中已经提到,Http是基于TCP之上建立的,所以要实现Http服务器,首要的任务就是需要一个优秀的TCP服务端组件。我用的是Java语言,如果选择其他语言,实现原理其实也是一样的。
一、网络IO组件
既然TCP是基于Http的,网络IO组件当然也是实现Http服务器的基石啦。服务器能支持到的并发请求量,最关键的还是要看这个网络IO组件,一个优秀的网络IO框架能让服务器的TPS达到很高的级别。
想用一些成熟的开源框架肯定是不错的选择,比如Apache的MINA就是个不错的组件,目前很多公司都直接使用它,或者进行精简改良后再拿来使用。
如果自己实现也可以,针对自己的业务只实现其中的精华部分,让性能达到最佳。
在Java中如果用原生的Socket接口,需要自己实现线程队列,管理网络接收和读写,后面维护用户会话session都很麻烦的。通常用Java实现大并发的网络IO都使用NIO,虽然受限于JDK在Linux上的EPollArrayWrapper和EPollSelectorImpl实现,只能使用epoll的Level Triggered,比原生的socket接口要差点,但目前性能已经十分优秀,并且完全足够支撑大部分的场景了。

上图是一个网络IO组件的基本结构,将接受套接字单独用一个线程来处理,这样能大大提高由于读写时导致线程阻塞的损失的资源利用能力。读写线程的数量可以根据实际的场景中网卡的读写能力和网络包的平均大小来设置,默认可以就设置为CPU内核数量。
每次一个连接建立,接收器将套接字交给读写线程后,会随之生成一个Session对象,这个会话对象会一直伴随着整个连接的生命周期,直到断开。因为读写线程是对所有连接资源共享的,只有在网络IO需要发生时才会占用通道,所以业务逻辑任务中进行网络读写需要通过Session这个会话对象作为传输介质来完成。
二、请求报文解析
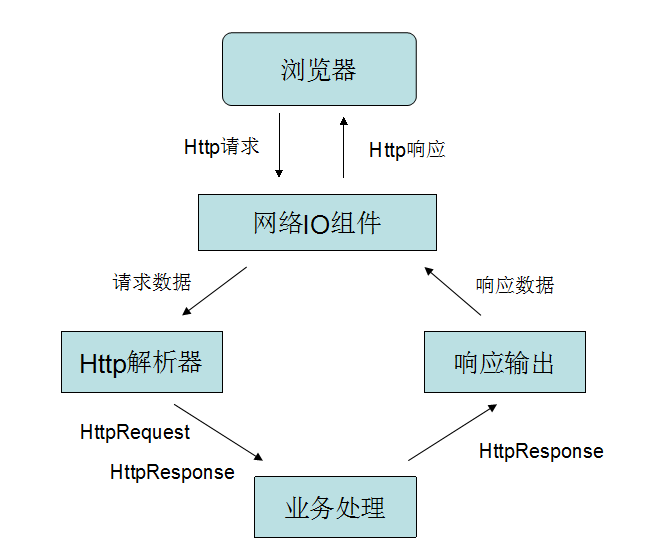
解析请求和响应输出都是基于上面的网络I/O组件。
当连接建立之后,首先从连接通道中读取数据,将数据交给“Http解析器”来解析。这里需要注意的是Http1.1使用的是长连接方式,所以有可能整个请求消息过大(超过缓冲区大小、网络MTU限制)等原因导致多次传输,如果Http解析器中解析过程发现后面消息丢失,可先将这次读取到的数据暂时保存在session(每次连接创建一个会话session,session一直保持直到连接断开)中,下次读取新数据的时候,如果上次读取有保存数据,将两次数据合并再进行解析。
这里暂时只考虑解析GET和POST请求方法,大部分的业务也只会涉及这两种方法。
在解析Http数据之前,先创建一个HttpRequest对象和一个HttpResponse对象,各自保存请求信息和响应信息。并且解析成功后将两个对象传递给后端程序处理(servlet、MVC框架等)。这两个对象贯穿一次请求响应的整个过程。对于这两个对象我们应该很熟悉了,平时使用一些框架的时候请求信息都是从HttpRequest对象中获取,要给响应用户的信息设置则是操作HttpResponse对象。
下面是HttpRequest类和HttpResponse类的简单结构示例:
public class HttpRequest {
private String version;
private String method;
private String uri;
private String url;
private Map<String,String> headers;
private Map<String,String> parameters;
private Map<String,Object> attributes;
}
public class HttpResponse {
private String version = “HTTP/1.1”;
private String statusCode = “200”;
private Map<String,String> headers;
}请求行
现在获得了整个请求的消息了(字节流),注意Http请求数据中的换行是CRLF(\r\n),首先解析到第一个换行前的字符串,就是该Http请求的请求行。
在上一篇中已经说过,它的格式是:
【请求方法】【空格】【请求URI】【空格】【协议版本】
将字符串中的请求方法、URI、Http版本保存到Request对象中。这里不要忘了解析保存URI地址中问号”?”后面的请求参数,将参数保存到HttpRequest对象的属性parameters(可以用HashMap<String,String>来存储)中。
请求头部
下面开始解析头部域,要知道头部中每一行是一个头域,最后一个换行(CRLF)是头部结束标识的空行,而在空行之后的所有数据就都是请求体了。所以解析的时候可以以换行符为界限,当换行前的字符串为空时表示头部结束,非空则字符串为一个头域,将其名称和值保存在HttpRequest对象的属性headers中(可以用HashMap<String,String>来存储)。如果解析到达头部结束标识(空行),并且请求方法是GET的话,后面的请求体就不需要解析了,因为GET请求没有请求体的。
这里需要注意的一点是,大多数浏览器在当请求的数据大于1k时,会将请求会分为两个,第一个请求的头域中包含Expect:100-continue,表示询问服务器是否愿意接受客户端的数据,这时我们可以直接用HttpResponse响应输出100状态码的数据:
【HTTP/1.1 100 Continue\r\n\r\n】
表示愿意让客户端发送余下的请求。所以要针对Expect:100-continue会做下特殊处理。
请求体
在头部结束标识的空行之后就是请求体开始的位置了,头域中content-length的值是请求体的长度,并且是POST请求方法,这时就能得到请求体数据了。请求体的格式也是按照name=value&name2=value的格式解析,然后将参数保存到HttpRequest对象的parameters中。
这里先不考虑文件上传的请求体格式,有兴趣的话可以自己去了解上传文件的消息体格式,而且一般文件上传下载最好用单独和文件服务器,不要和业务逻辑处理混合起来,这样会大大地占用进程的内存和网络带宽的。
上面的解析过程中如果发生错误,可以直接返回400错误状态码和相应页面内容,提醒客户端请求消息错误。
在上面的解析都完成了,后续就可以将HttpRequest、HttpResponse对象交给后端程序处理了。当后端程序处理完成后,再交由响应输出将数据传给IO组件传输给浏览器。
三、响应报文输出
上面的后端程序处理完成后,HttpResponse对象负责输出内容。
状态行
根据Response对象中的状态码输出相应的状态行。
【协议版本】【空格】【状态码】【空格】【服务器信息】
状态码和服务器信息在上一篇中已经说过,就不在多说了。
响应头部
然后输出HttpResponse的headers中保存的头部信息。这里的格式和解析的时候是一样的,在头部最后记得加上一个空行(最后一个头域后面跟着两个CRLF)。
响应正文
在上一篇的最后提到,如果是Http1.1协议,使用长连接的方式,浏览器不知道响应正文在何时结束,所以输出正文有两种方式:
1、通过头域中的Content-Length来判断:如果我们知道正文内容长度的情况下,可以向头域中增加Content-Length字段,这里我们直接输出响应正文内容即可。浏览器在解析响应的时候就可以通过Content-Length字段来区分正文块。
2、如果正文内容长度是未知的,头域中没有Content-Length来标识正文长度,这时我们就需要使用chunked编码方式:首先上面的响应头域中需要加上Transfer-Encoding:chunked,然后将内容分成一个个chunk块,在头部结束标识空行之后,先输入该chunk块的长度(十六进制),后面加一个CRLF,然后加上chunk块的内容,接着在加上一个CRLF......依次输出chunk块。
chunk块也可以分为多次传输,每次传输1个或多个。当所有内容都输出了,在最后个CRLF后面加上0和两个CRLF表示整个文档已输出完毕。
具体的正文体的格式为
【chunk块长度】【CRLF】
【内容】【CRLF】
......(如果有多个重复上面的chunk块)
【0】【CRLF】【CRLF】
下面是一个chunk编码的响应消息例子:
===========================
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1A
and this is the second one
0
=======================
注意以上所有的数据输出(从响应状态行到正文结束),都要根据设置的响应编码输出成字节流。可能是utf-8或gbk等:byte[] content = string.getBytes(“UTF-8”)。
到这里一个完整的Http服务器的实现流程算是完成了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









