










1. swap的含义
在Linux里swap有两个意思:
1. 动词:交换。内存和磁盘的颠簸行为。
2. 名词:硬盘的swap分区。
没有文件背景的页面,即匿名页(anonymous page),如堆,栈,数据段等,不是以文件形式存在,因此无法和磁盘文件交换,但可以通过硬盘上划分额外的swap交换分区或使用交换文件进行交换。即上面wap作为名词的意思。Swap分区可以将不活跃的页交换到硬盘中,缓解内存紧张。
注意,即使没有swap分区,也会存在swap行为,因为有文件背景的页面(file-backed page)也会有swap,即第1点的磁盘和内存之间的交换。
对于有文件背景的页面,程序去读文件时,可以通过read也可以通过mmap去读。当你通过任何一种方式从磁盘读文件时,内核都会给你申请一个page cache,来缓存硬盘上的内容。这样的话,读过一遍的数据,本进程或其他进程下次再读的时候就直接从page cache里去拿,就很快了,提升系统的整体性能。因此用户的read/write实际上是跟page cache的相互拷贝。
而用户的mmap则会将一段虚拟地址(3G)以下映射到page cache上,这样的话,用户就可以通过读写这段虚拟地址来修改文件内容,省去了内核和用户之间的拷贝。
所以文件对于用户程序来讲其实只是内存,page cache就是磁盘中文件的一个副本。可以通过 “echo 3 > /proc/sys/vm/drop_cache” 来清cache。清掉之后,进程第一次读文件就会变慢。
通过free命令可以看到当前page cache占用内存的大小,free命令中会打印buffers和cached(有的版本free命令将二者放到一起了)。通过文件系统来访问文件(挂载文件系统,通过文件名打开文件)产生的缓存就由cached记录,而直接操作裸盘(打开/dev/sda设备去读写)产生的缓存就由buffers记录。
root@jchen:~# free
total used free shared buffers
Mem: 254316 68568 185748 0 6676
-/+ buffers: 61892 192424
Swap: 0 0 0实际上文件系统本身再读写文件就是操作裸分区的方式,用户态也可以直接操作裸盘,像dd命令操作一个设备名也是直接访问裸分区。那么,通过文件系统读写的时候,就会既有cached又有buffers。从图中可以看到,文件名等元数据和文件系统相关,是进cached,实际的数据缓存还是在buffers。例如,read一个文件(如ext4文件系统)的时候,如果文件cache命中了,就不用走到ext4层,从vfs层就返回了。
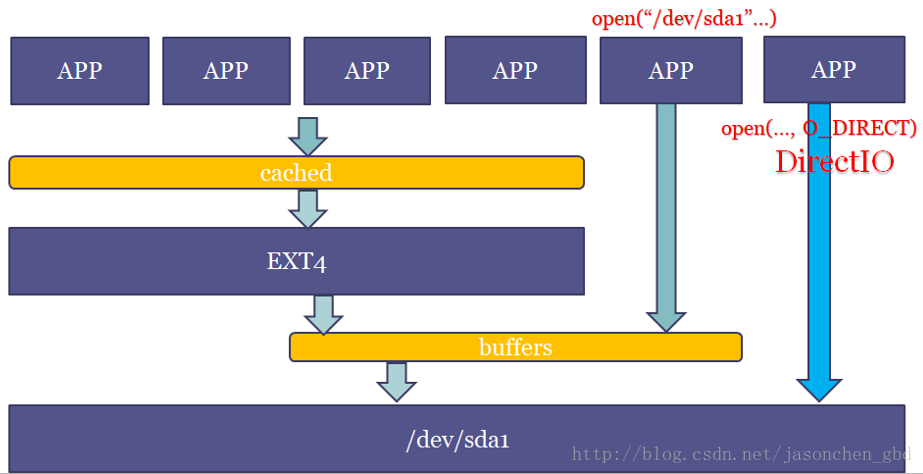
当然,还可以在open的时候加上O_DIRECT标记,做直接IO,就连buffers都不进了,直接读写磁盘。
free命令的第二行打印即是将buffers/cache作为可用内存统计到used和free的列。
2. 页面回收(reclaim)
2.1 回收时机
有文件背景的数据实际上就是page cache,但page cache不能无限增加,不能说慢慢的所有文件都缓存到内存了。肯定要有一个机制,让不常用的文件数据从page cache刷出去。内核中有一个水位控制的机制,在系统内存不够用的时候,会触发页面回收。
对于没有文件背景的页面即匿名页,比如堆、栈、数据段,如果没有swap分区,不能与磁盘交换,就要常驻内存了。这里需要特殊说明一下数据段,数据段实际上在磁盘文件里,如果一个程序的全局变量的某一页的数据都还没有被修改过,就没必要产生匿名页,而一旦被修改了,就变成匿名页了,因为你不能回写磁盘啊,不能下次重新执行程序的时候变量初始值变了……。
但是常驻内存的话,就会吃内存,可以通过给硬盘搞一个swap分区或硬盘中创建一个交换文件(swapfile)让匿名页也能交换到磁盘上。可认为是为匿名页伪造的文件背景。swap分区或swap文件实际上最终是到达了增大内存的效果。当然,如果频繁交换的话,被交换出去的数据的访问就会慢一些,因为要有IO操作了。
无论是有文件背景的页还是匿名页,交换(这里指换出)的时机有两个:
- 内核通过kswapd内核线程慢慢回收,回收的时机由水位控制。
- 人为地主动地进行drop_cache。由于第1点要等到内存不足的时候才swap,可以通过这种方式主动发起回收。
内核中有个CONFIG_SWAP选项,可以控制匿名页的交换,如果关掉这个选项,就不能使用swap分区和交换文件了。但有文件背景的页本来就在磁盘里,因此仍可以交换,不受该选项影响。也可以在开了CONFIG_SWAP的情况下,通过swapoff命令,将匿名页的swap功能关掉(如果此时swap分区里有内容,则会先换入),相应的使用swapon命令重新打开匿名页的swap功能。
2.2 水位(watermark)控制
内核中有三个水位:
- low:当剩余内存慢慢减少,触到这个水位时,就会触发kswapd线程的内存回收。
- min:如果剩余内存减少到触及这个水位,可认为内存严重不足,当前进程就会被堵住,kernel会直接在这个进程的进程上下文里面做内存回收(direct reclaim)。
- high: 进行内存回收时,内存慢慢增加,触到这个水位时,就停止回收。
由于每个ZONE是分别管理各自内存的,因此每个ZONE都有这三个水位。
swapness:
内存回收的过程就相应的会有page cache向磁盘或匿名页向swap分区回写的过程。回收的时候,是回收有文件背景的页还是匿名页呢,都会回收,但可通过/proc/sys/vm/swapness来控制让谁回收多一点点。这个值比较大时,就回收匿名页多一点点,比较小就反之。
所以swapness反映了是否积极地使用swap空间,而将swapness=0则意味着不再交换匿名页,除非当内存不足(free and file-backed pages < high watermark in a zone)的情况下才使用swap空间(这里的意思是,内存触到low之后就发起回收,直到内存回到high水位停止,但如果回收完file-backed页面都到不了high,就得开始回收匿名页了,这段时间内即使swapness=0也出现了回收匿名页的情况)。
另外需要注意,/proc/sys/vm/swapness是控制全局的swap特性的。cgroup的swapness优先级高些,如果一个cgroup的swapness关掉,全局的没关,那么这个cgroup里的进程的swap就是关掉的。也就是说,全局的swapness是控制不在cgroup里面的进程的swap特性的。
回收的过程是依据LRU,即最近最少使用的页会被回收,Linux内核一直在评估哪些是LRU的页面即最不活跃的页面。
root@none:~# cat /proc/meminfo
MemTotal: 254316 kB
MemFree: 185748 kB
Buffers: 6676 kB
Cached: 22716 kB
SwapCached: 0 kB
Active: 25472 kB <----
Inactive: 23164 kB <----
Active(anon): 19684 kB <----
Inactive(anon): 456 kB <----
Active(file): 5788 kB <----
Inactive(file): 22708 kB <----
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 0 kB
Writeback: 0 kB
AnonPages: 19272 kB
…… ……这里cat /proc/meminfo看到的active和inactive的内存就是指lru算法里面去评估的一个页面的使用情况(有没有被访问过),inactive的页面中最inactive的页面最先被回收。如果inactive的页都回收了但内存仍然不够,也会从active的页中回收相对最不活跃的页面。
所以我们就知道,如果lowmem被使用殆尽,触及low或min水位,内核的普通kmalloc就申请不到内存了,就会触发cache/buffers的回收和匿名页swap,再不行就OOM了。
注意sync和swap的区别哦。sync是回写脏页,即page cache被修改后与磁盘原文件内容不同步的页,回写完后内存也不会回收,回收还是要等到kswapd或direct reclaim。进程打开并使用一个文件后调用close(),是不会回写脏页的,要显示地调用sync()/fsync()。
再说一下tmpfs,tmpfs是存放临时文件用的,还用于linux的posix和sysv共享内存,共享内存这种进程通信方式底层就是tmpfs。它其实是没有文件背景的,因此如果有swap,就交换到swap分区,没有就常驻内存。但是在统计内存的时候,是把tmpfs占的内存统计到page cache的,这里就有点绕。所以有时你在drop_cache后发现cache/buffers仍然很大,可能就是因为tmpfs的内存无法回收。
另外对于内核空间,内核的内存,如代码、数据、申请的内存,一般是不能被回收的。内核产生的文件cache、一些数据结构如dentry和inode等充当缓存的内存这些是可以回收的。
如何计算水位
/proc/sys/vm/min_free_kbytes 是一个用户可配置的值,默认值是根据每个lowmem zone的内存大小算出来的(不是随着内存大小线性增长的)。这个值就决定了min的值,然后根据min算出来low和high水位的值。结果就是high>low>min。
在/proc/zoneinfo中可以看到每个zone的水位情况。具体计算方法见init_per_zone_wmark_min(void)函数。
比较特殊的是highmem,highmem的水位不是根据min_free_kbytes计算,而是将其min设置为一个很小值,因为低水位是为了给紧急内存使用(如处理OOM也要使用内存),而紧急内存(__GFP_HIGH和PF_MEMALLOC)的分配不会在highmem上进行,因此不用预留太多。low和high仍然和其他zone一样由min计算得出,因为highmem仍有内存回收机制。
在kmalloc的时候加上PF_MEMALLOC标记就可以忽略内存管理的水位限制分配内存。当然,内核关键代码会这样用,你自己的代码就不要加这个标记了。
/proc/sys/vm/lowmem_reserve_ratio 可以对低端内存做进一步保护。我们知道越低端内存越珍贵,lowmem_reserve_ratio可以让kernel申请内存的时候不至于出现低端内存快用完了而高端内存还有可用的情况。它实际上是在watermark的基础上又预留出一段内存:在因为申请highmem得不到内存而转为向lowmem申请的情况下,lowmem的min就会变得严格,可能会让高端内存先尝试内存回收在分配内存。
3. 脏页的回写
上面提到了要注意区别sync和swap,这里也讲一下。sync是用来回写脏页的,脏页不能在内存中呆的太久,因为如果突然断电没有写到硬盘的脏数据就丢了,另一方面如果攒了很多一起写回也会明显占用CPU时间。
控制脏页何时写回:
下面这些变量是整个系统的,见kernel/sysctl.c中的定义:
static struct ctl_table vm_table[] = {
……
};dirty_ratio: 一个写磁盘的进程所产生的脏页到达这个比例时,这个进程自己就会去回写脏页。
dirty_expire_centisecs: 脏页的到期时间,或理解为老化时间,单位是1/100s,内核中的flusher thread会检查驻留内存的时间超过dirty_expire_centisecs的脏页,超过的就回写。
dirty_writeback_centisecs: 内核的flusher thread周期性被唤醒(wakeup_flusher_threads())的时间间隔,每次被唤醒都会去检查是否有脏页老化了。如果将这个值置为0,则flusher线程就完全不会被唤醒了。
dirty_background_ratio: 如果脏页的数量超过这个比例时,flusher线程就会启动脏页回写。
因此可以看出,脏页回写的时机由时间(dirty_expire_centisecs/dirty_writeback_centisecs)和空间(dirty_ratio/dirty_background_ratio)两方面共同控制:
- 即使只有一个脏页,那如果它超时了,也会被写回。防止脏页在内存驻留太久。dirty_expire_centisecs这个值默认是3000,即30s,可以将其设置得短一些,这样掉电后丢失的数据会更少,但磁盘写操作也更密集。
- 不能有太多的脏页,否则会给磁盘IO造成很大压力,例如在内存不够做内存回收时,还要先回写脏页,也会明显耗时。
需要注意的是,在达到dirty_background_ratio后,flusher线程(名为“[flush-devname]”)开始回写,但由于写磁盘速度慢,如果此时应用进程还在不停地写磁盘,flusher线程回写没那么快,那么就会导致进程的脏页达到dirty_ratio,这时这个进程就会去回写脏页而导致write被堵住。也就是说dirty_background_ratio通常是比dirty_ratio小的。
脏页都是指有文件背景的页面,匿名页不会存在脏页。从/proc/meminfo的’Dirty’一行可以看到当前系统的脏页有多少,用sync命令可以刷掉。
补充:zRAM机制
不用swap分区,也可以用zRAM机制来缓解内存紧张: 从内存里拿出一段内存空间(compressed block),作为交换空间模拟硬盘的交换分区,用来交换匿名页,并且让kernel看到的物理内存大小不包括这段内存。而这段交换空间自带透明压缩功能,即交换到这块zRAM分区时,Linux会自动将这块匿名页压缩存放。系统访问这块页面的内容时,产生page fault后从交换分区去拿,这时Linux给你透明解压再交换出来。
使用zRAM的好处,就是访存比访问硬盘或flash的速度提高很多,且不用考虑寿命问题,并且由于这段内存是压缩后存储的,因此可以存更多的数据,虽然占用了一段内存,但实际可以存更多的数据,也达到了增加内存的效果。缺点就是压缩要占用CPU时间。
Android里面普遍使用了zRAM技术,由于zRAM牺牲了CPU时间,所以交换次数还是越少越好。像Android和windows,内存越大越好,因为发生交换的几率就小。这样两个进程相互切换(如微博和微信)时就会变得流畅,因为内存足够的话,后台进程无需被换进swap分区或被OOM杀掉。当然如果你只打打电话,就没必要大内存啦。














 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









