









前言
在实际数据库项目开发中,由于我们不知道实际查询时数据库里发生了什么,也不知道数据库是如何扫描表、如何使用索引的,因此,我们能感知到的就只有SQL语句的执行时间。尤其在数据规模比较大的场景下,如何写查询、优化查询、如何使用索引就显得很重要了。
那么,问题来了,在查询前有没有可能估计下查询要扫描多少行、使用哪些索引呢?
答案是肯定的。以MySQL为例,MySQL通过explain命令输出执行计划,对要执行的查询进行分析。
什么是执行计划呢?
简单来说,就是SQL在数据库中执行时的表现情况,通常用于SQL性能分析、优化等场景。
本文从MySQL的逻辑结构讲解,过渡到MySQL的查询过程,然后给出执行计划的例子并重点介绍执行计划的输出参数,从而理解为什么我们会选择文中建议的方案。
MySQL逻辑架构
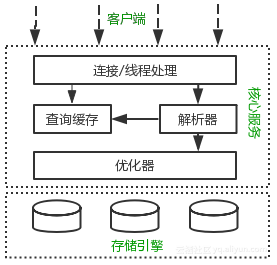
MySQL逻辑架构分为三层,如下图。
-
客户端
- 如,连接处理、授权认证、安全等功能
-
核心服务
- MySQL大多数核心服务均在这一层
- 包括查询解析、分析、优化、缓存、内置函数(如,时间、数学、加密等)
- 所有的跨存储引擎的功能也在这一层,如,存储过程、触发器、视图等
-
存储引擎
- 负责MySQL中的数据存储和读取
- 中间的服务层通过API与存储引擎通信,这些API屏蔽了不同存储引擎间的差异
重点解释下查询缓存:对于select语句,在解析查询之前,服务器会先检查查询缓存(Query Cache)。如果命中,服务器便不再执行查询解析、优化和执行的过程,而是直接返回缓存中的结果集。
MySQL查询过程
如果能搞清楚MySQL是如何优化和执行查询的,对优化查询一定会有帮助。很多查询优化实际上就是遵循一些原则让优化器能够按期望的合理的方式运行。
下图是MySQL执行一个查询的过程。实际上每一步都比想象中的复杂,尤其优化器,更复杂也更难理解。本文只给予简单的介绍。
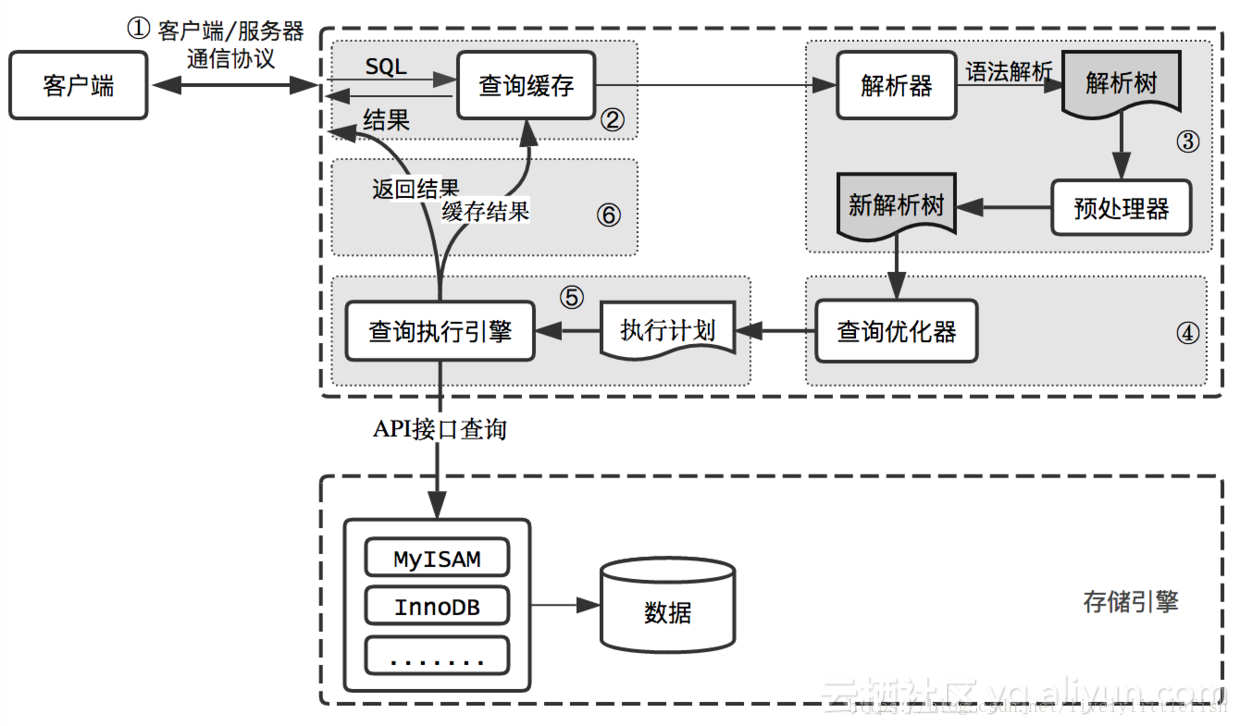
MySQL查询过程如下:
- 客户端将查询发送到MySQL服务器
- 服务器先检查查询缓存,如果命中,立即返回缓存中的结果;否则进入下一阶段
- 服务器对SQL进行解析、预处理,再由优化器生成对象的执行计划
- MySQL根据优化器生成的执行计划,调用存储引擎API来执行查询
- 服务器将结果返回给客户端,同时缓存查询结果
执行计划
优化与执行
MySQL会解析查询,并创建内部数据结构(解析树),并对其进行各种优化,包括重写查询、决定表的读取顺序、选择合适的索引等。
用户可通过关键字提示(hint)优化器,从而影响优化器的决策过程。也可以通过通过优化器解释(explain)优化过程的各个因素,使用户知道数据库是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和数据库表的schema、修改数据库配置等,使查询尽可能高效。
例子
看个例子。
mysql> explain select name, nickname, ctime from dt_user where city = 'shanghai' order by name;
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
| 1 | SIMPLE | dt_user | range | PRIMARY,idx_city_name | idx_city_name | 2945 | NULL | 55183 | Using index condition |
+----+-------------+------------+-------+--------------------------+---------------+---------+--------+---------+-----------------------+
1 row in set (0.00 sec)这个执行计划给出的信息是,该查询通过一个简单的给定范围的扫描,共扫描55183行,使用index condition条件在dt_user表中筛选出,扫描过程中使用PRIMARY和idx_city_name索引。
输出参数
输出各字段解释如下。更详细的信息请参考https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
-
id
- select查询序列号
- id相同,执行顺序由上至下;id不同,id值越大优先级越高,越先被执行
- select_type
查询数据的操作类型,有如下

- table
显示该行数据是关于哪张表 - partitions
匹配的分区 - type
表的连接类型,其值、性能由高到底排列如下

前5种情况都是理想的索引的情况。通常优化至少到range级别,最好能优化到ref。
- possible_keys
指出 MySQL 使用哪个索引在该表找到行记录。如果该值为 NULL,说明没有使用索引,可以建立索引提高性能 - key
显示 MySQL 实际使用的索引。如果为 NULL,则没有使用索引查询 - key_len
表示索引中使用的字节数,通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好显示的是索引字段的最大长度,并非实际使用长度 - ref
显示该表的索引字段关联了哪张表的哪个字段 - rows
根据表统计信息及选用情况,大致估算出找到所需的记录或所需读取的行数,数值越小越好 - filtered
返回结果的行数占读取行数的百分比,值越大越好 - extra
包含不适合在其他列中显示但十分重要的额外信息。常见的值如下

小结
数据库性能优化很多,本文只简单了介绍MySQL逻辑结构、查询过程和执行计划参数。根据执行计划输出的索引使用情况、扫描的行数可以预估查询效率,帮助我们重构查询、优化表结构或者索引,从而尽可能提供查询效率。
Reference
- 《高性能MySQL》
- https://juejin.im/post/59d83f1651882545eb54fc7e
- https://blog.csdn.net/chenshun123/article/details/79677037
- https://yq.aliyun.com/articles/599674
- https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
- https://dev.mysql.com/doc/refman/5.7/en/explain-extended.html
- https://dev.mysql.com/doc/refman/5.7/en/estimating-performance.html














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









