







如果在你的程序里需要输入很多的内容,比如各类单据,如果在进入每一个录入框的时候都能自动把输入法切换到合适的状态将会是一个很酷的特性,相比炫丽的界面而言打字到手抽筋的录入人员们对此会更加感兴趣。在winform中切换输入法是很简单的事情:
这样子就能很轻松的吧输入法切换到智能ABC了。
但是这样子的效果是不完美的,这个方法不能指定IME的状态,也就是IME的转换状态。这个概念是只有远东地区的windows才存在的状态,因为对于英语国家来说输入根本不存在输入法,而法语,俄语等拉丁语系的拼音文字的 语言都只需要简单的修改键映射关系就行了,只有受中文影响的东亚地区有输入法的概念,比如日文和朝鲜文,为了方便输入,这些IME中都有很多状态,比如微软日文输入法:
日文输入包含了全角半角平假名,全角半角片假名等录入的状态,还包括了:
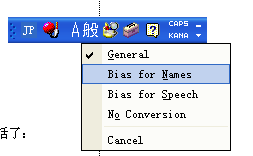
普通,名字,对话和不转换四种假名到当用汉字的转换模式
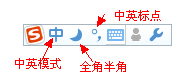
汉语的输入法简单一些,不存在对汉字的转换,不过也存在为了中英交替录入(牛逼哄哄的日本人喜欢用片假名替换英文所以不存在交替录入)而存在的中英录入模式转换,中英标点符号装换,还有全角半角的转换:
如果是用的很古老的智能ABC的话,那么还存在双打和标准模式的切换。
对于这些五花八门的输入法中的输入模式,如果在选择了确定要输入法,同时也要确定要唯一定位到输入的模式,那么 InputLanguage 类的功能就捉襟见肘了。
在windows的文字服务IMM中对IME提供了ConvertionStatus的 接口来确定输入法的工作模式,在Win32 API中就是
ImmGetConversionStatus和ImmSetConversionStatus
这两个函数都有三个参数,一个是输入法IME的句柄,一个是mode,一个是sentence,最重要的就是mode和sentence这两个参数了,他们就是确定输入法状态的数据。经过 测试发现,每个输入法的值都不一样,所以看MSDN去解析这两个int变量所对应的枚举值有哪些意义完全没必要,太复杂了,而我们只需要精确的切换到某个模式,只需要记录下这些模式下mode和sentence的值就行了。
下面是中文输入法的状态和mode值的对应关系表
双打模式(包括单双混合,比如微软输入法)
标准模式(全拼模式,比如智能ABC的标准模式)
由于不同的输入法对于模式的支持不同,比如搜狗支持的是标准模式,但是由于本身的功能又可以双打,但是设置模式却要用标准模式的值,而微软拼音是双打模式,而和同在双打模式智能ABC的sentence值又不一样,所以还是要根据具体的输入法测试后决定用什么数值来实现转换。
附1:
转换的代码:
首先注册Win32API的方法 这样就能把输入法确定为搜狗拼音,且为全角的数字符号和英文,且标点符号为中文标点。
附2:
日文输入法的值
日文输入法的假名和全半角模式由mode值控制
当用汉字的转化模式由 sentence 的值控制
附三:
棒子国输入法………没有用过,省略了吧。
但是这样子的效果是不完美的,这个方法不能指定IME的状态,也就是IME的转换状态。这个概念是只有远东地区的windows才存在的状态,因为对于英语国家来说输入根本不存在输入法,而法语,俄语等拉丁语系的拼音文字的 语言都只需要简单的修改键映射关系就行了,只有受中文影响的东亚地区有输入法的概念,比如日文和朝鲜文,为了方便输入,这些IME中都有很多状态,比如微软日文输入法:
日文输入包含了全角半角平假名,全角半角片假名等录入的状态,还包括了:
普通,名字,对话和不转换四种假名到当用汉字的转换模式
汉语的输入法简单一些,不存在对汉字的转换,不过也存在为了中英交替录入(牛逼哄哄的日本人喜欢用片假名替换英文所以不存在交替录入)而存在的中英录入模式转换,中英标点符号装换,还有全角半角的转换:
如果是用的很古老的智能ABC的话,那么还存在双打和标准模式的切换。
对于这些五花八门的输入法中的输入模式,如果在选择了确定要输入法,同时也要确定要唯一定位到输入的模式,那么 InputLanguage 类的功能就捉襟见肘了。
在windows的文字服务IMM中对IME提供了ConvertionStatus的 接口来确定输入法的工作模式,在Win32 API中就是
ImmGetConversionStatus和ImmSetConversionStatus
这两个函数都有三个参数,一个是输入法IME的句柄,一个是mode,一个是sentence,最重要的就是mode和sentence这两个参数了,他们就是确定输入法状态的数据。经过 测试发现,每个输入法的值都不一样,所以看MSDN去解析这两个int变量所对应的枚举值有哪些意义完全没必要,太复杂了,而我们只需要精确的切换到某个模式,只需要记录下这些模式下mode和sentence的值就行了。
下面是中文输入法的状态和mode值的对应关系表
双打模式(包括单双混合,比如微软输入法)
| 输入法状态 | mode值 |
| 中文输入-半角-中文符号 | -2147482623 |
| 中文输入-全角-中文符号 | -2147482615 |
| 中文输入-半角-英文符号 | -2147483647 |
| 中文输入-全角-英文符号 | -2147483839 |
| 英文输入-半角-中文符号 | -2147482624 |
| 英文输入-全角-中文符号 | -2147482616 |
| 英文输入-半角-英文符号 | -2147483648 |
| 英文输入-全角-英文符号 | -2147483640 |
标准模式(全拼模式,比如智能ABC的标准模式)
| 输入法状态 | mode值 |
| 中文输入-半角-中文符号 | 1025 |
| 中文输入-全角-中文符号 | 1033 |
| 中文输入-半角-英文符号 | 1 |
| 中文输入-全角-英文符号 | 9 |
| 英文输入-半角-中文符号 | 1024 |
| 英文输入-全角-中文符号 | 1032 |
| 英文输入-半角-英文符号 | 0 |
| 英文输入-全角-英文符号 | 8 |
由于不同的输入法对于模式的支持不同,比如搜狗支持的是标准模式,但是由于本身的功能又可以双打,但是设置模式却要用标准模式的值,而微软拼音是双打模式,而和同在双打模式智能ABC的sentence值又不一样,所以还是要根据具体的输入法测试后决定用什么数值来实现转换。
附1:
转换的代码:
首先注册Win32API的方法 这样就能把输入法确定为搜狗拼音,且为全角的数字符号和英文,且标点符号为中文标点。
附2:
日文输入法的值
日文输入法的假名和全半角模式由mode值控制
| 模式 | mode 值 |
| DirectInput | 25 |
| Hiragana | 25 |
| Full Width Katakana | 27 |
| Full Width Alphanumeric | 24 |
| Half Width Katakana | 19 |
| Half Width Alphanumeric | 16 |
当用汉字的转化模式由 sentence 的值控制
| 模式 | 值 |
| 般 | 8 |
| 名 | 1 |
| 话 | 16 |
| 无 | 0 |
附三:
棒子国输入法………没有用过,省略了吧。















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









