







1、HDFS 介绍
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
是Google GFS论文的强化版、HDFS具有良好的扩容性,高容错性、适合大量数据的存储。原理是将文件切割成等份的块数据,存储到多台的机器上。
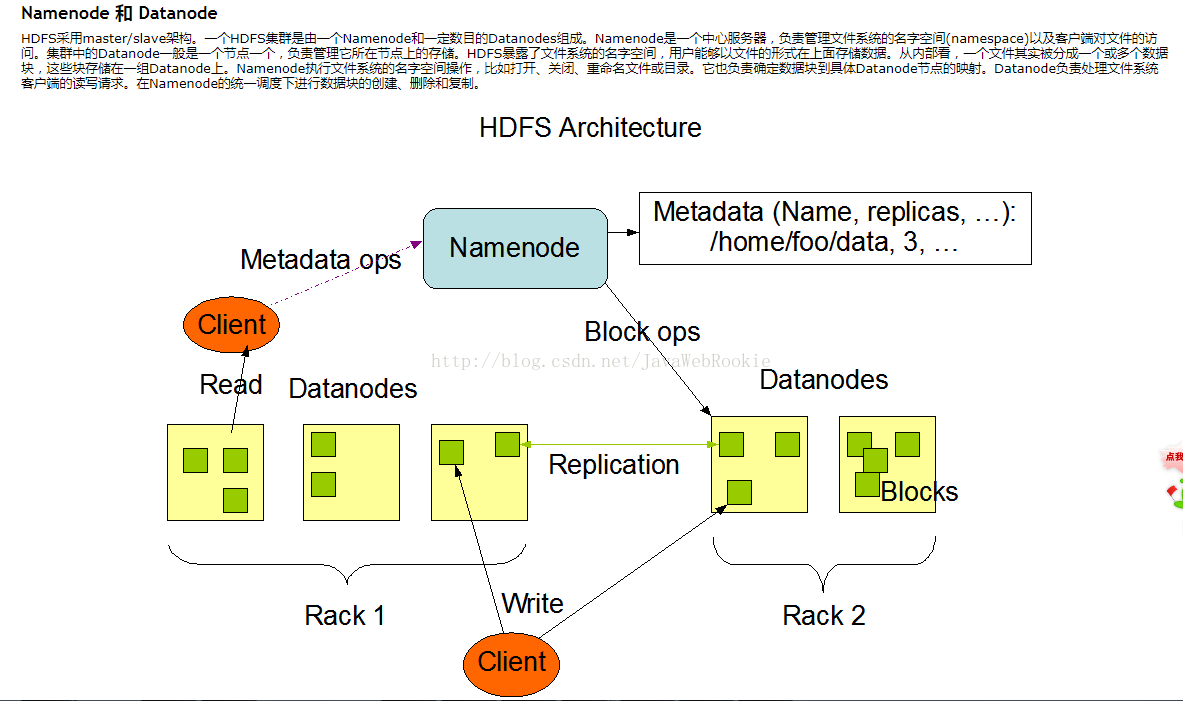
从架构图来看、其NameNode(NN)和DataNode(DN)是很重要节点,还有SecondaryNameNode(SNN)。
2、NameNode
NameNode是主节点,主要负责接收客户端的读写服务、NameNode会保存元数据(metadate)信息。元数据信息包括:文件包含的块(Block)、Block保存在DataNode的信息(在哪一个DataNode)、文件的权限信息、生成的时间、副本数、文件目录结构等。NameNode还管理数据的复制,它周期性的检查DataNode接收的心跳和块数据报告。如果接收到心跳报告说明DataNode是存活的,心跳报告上存放着DataNode的所有块数据信息。
NameNode的存储位置是在内存和本地磁盘。元数据信息在启动后会加载到内存,而本地磁盘有两个重要文件:fsimage(镜像文件)和edites(编辑日志),元数据信息和Block(块数据)的位置存储到(fsimage镜像文件)、日志记录存储到edites。
3、DataNode
DataNode 在本地文件系统是存储文件块数据、以及块数据的校验和。DataNode启动再NameNode注册后,会周期性的向NameNode发送所有块数据的报告。还有文件副本存放在DataNode上,并且由NameNode控制,NameNode会根据情况做出放块的位置。当读取文件时一般都先读取最近的副本数据,这样减少了消耗。
可以在DataNode上操作文件,创建、删除、重命名等,特别注意的是当文件写入后不能修改文件内容。
4、SecondaryNameNode
SecondaryNameNode 是用来监控HDFS状态的辅助后台程序,辅助NameNode工作,合并两个文件(定时周期性)。
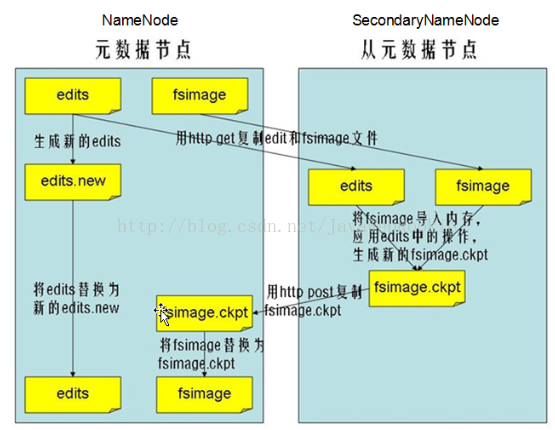
SecondaryNameNode的工作流程














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









