






前段时间做过一个纯前端解析.docx文件的需求,只需要解析文件的内容展示在页面上即可,需求听上去还挺简单的,然而我还是踩了到了巨坑。
前端解析工具
- mammath
从各个网站上搜到了不少的解析方法,这里我发现了mammoth,这个插件功能还是很强大的,结合H5和mammoth,很快我就写下了一个解析docx文件的方法:
function parseStandFile(file){
var reader = new FileReader();
reader.onloadend = function(event) {
var arrayBuffer = reader.result;
mammoth.extractRawText({arrayBuffer: arrayBuffer}).then(function (resultObject) {
$result.innerHTML = resultObject.value
console.log(resultObject.value)
})
};
reader.readAsArrayBuffer(file);
}
ps: $result:文档文本显示的dom节点
到这一步,还是很顺利的,自己创建一个docx文件,上传展示都很顺利,然而,当我拿来客户的文件,上手操作的时候,发现解析出来竟让是一片空白(unbelievable)!!!
于是我又企图从茫茫互联网中获取答案,然而一无所获sad。但是在查找的过程中发现docx文件压缩之后能看到文件的构成,于是我压缩了目标文件,发现文件目录如下:

当我打开docProps/app.xml:

发现客户文件里的压缩文件跟我的似乎不太一样,可能是客户用的word版本跟我的不太一样之类的原因吧,然而需求还是要实现的,这时我发现压缩文件夹下面的word/document.xml里存放的就是docx文件的内容,所以我的思路是先解压docx文件这个小妖精,然后找包含内容的文件,最后进行xml文件的匹配解析
- JSZip
很容易在网上就能找到js解压缩的工具,对比了几个之后,我决定使用JSZip,使用方式也很简单,官网打开一目了然。于是我很快就写好了又一个解析方法:
JSZip.loadAsync($file.files[0]) //获取文件
.then(function(zip) {
let standalone
zip.forEach(function (relativePath, zipEntry){
parsePOIFile($file.files[0]) //解析文件内容,考虑兼容问题,单独写一个方法
})
function parsePOIFile(file){
JSZip.loadAsync(file)
.then(function(zip) {
var str = ''
zip.forEach(function (relativePath, zipEntry) {
if(zipEntry.name==='word/document.xml'){ //目标文件document
zip.file(relativePath).async("string").then(function (data) {
data.match(/<w:t>[\s\S]*?<\/w:t>/ig).forEach((item)=>{
str += item.slice(5,-6)
});
//以上match方式参考某网友,不记得是哪个blog了
$result.innerHTML = str
});
}
});
}, function (e) {
$result.append($("<div>", {
"class" : "alert alert-danger",
text : "Error reading " + file.name + ": " + e.message
}));
});
}
至此,客户文件就成功解析了。
然而,我发现,用我自己的office创建的文件,就不能解析了(土拨鼠的咆哮),毕竟两个文件内容不一样,于是我决定也兼容一下我的版本(强迫症使我劳累)
在代码zip.file(relativePath).async("string").then(function (data)中,我打印出来data寻找他们的区别,发现两种文件的docProps/core.xml内容,有这个明显的区别:
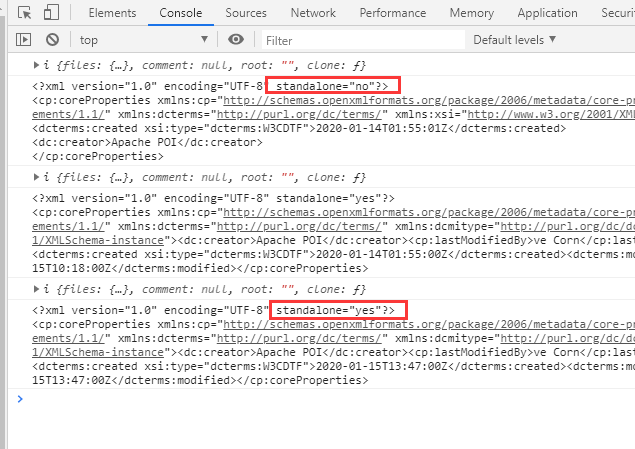
我决定获取该节点的standarlone属性,先获取到core.xml,然后执行不同的解析方法:
if(zipEntry.name==='docProps/core.xml'){
zip.file(relativePath).async("string").then(function (data) {
let parser=new DOMParser();
xmlDoc=parser.parseFromString(data,"text/xml");
standalone = xmlDoc.getElementsByTagName("cp:coreProperties")[0].getAttribute("xmlns:dcmitype")
if(standalone){
parseStandFile(file) //解析标准文件
} else {
parsePOIFile(file)
}
})
}
终于,两个文件都能成功解析了,心里非常有成就感,感悟就是:要从事物的本质思考问题(扶眼镜.jpg)

















 4051
4051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









