








There’s hardly anyone left in the world data science community who wouldn’t agree that the release of BERT was the most exciting event in the NLP field.
For those who still haven’t heard: BERT is a transformer-based technique for pretraining contextual word representations that enables state-of-the-art results across a wide array of natural language processing tasks. The BERT paper was acknowledged as the best long paper ? of the year by the North American Chapter of the Association for Computational Linguistics. Google Research released several pretrained BERT models, including the multilingual, Chinese, and English-language BERT.
At iPavlov we develop DeepPavlov — a conversational artificial intelligence framework that contains all the components required for building dialogue systems. And after the BERT release, we were amazed by a variety of tasks that can be solved with it.
We decided to integrate BERT into solutions for the three popular NLP tasks: text classification, tagging, and question answering. In this article, we’ll tell you in detail how to use the BERT-based named entity recognition (NER) in DeepPavlov.
Introduction to NER
Named-entity recognition (NER) is one of the most common tasks in NLP, and we can formulate it as:
Given a sequence of tokens (words, and possibly punctuation marks), provide a tag from a predefined tag set for each token in the sequence.
The tagged sentence below is the NER’s output in our demo, where in blue — person tag, green—location, yellow — geographic place, and grey — datetime.
![]()
The DeepPavlov NER model supports 19 tags: ORG (organization), GPE (countries, cities, states), LOC (location), EVENT (named hurricanes, battles, wars, sports events), DATE, CARDINAL, MONEY, PERSON, etc. The sentence processed by the DeepPavlov’s NER model in command line is shown below.
>> Amtech , which also provides technical temporary employment services to aerospace , defense , computer and high - tech companies in the Southwest and Baltimore - Washington areas , said its final audited results are due in late November .
['B-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O', 'B-GPE', 'O', 'B-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'O']To distinguish between the adjacent entities with the same tag, the BIO tagging scheme is used, where “B” denotes the beginning of an entity, “I” stands for “inside” and is used for all words comprising the entity except the first one, and “O” means the absence of an entity.
NER has a variety of business applications ?. For example, NER can facilitate the evaluation of resume at the HR department by extracting important information from resumes. Moreover, NER can be used in identifying relevant entities in customer request such as Product specifications, department or company branch details, so that the request is classified accordingly and forwarded to the relevant department.
How to use BERT-based NER model in DeepPavlov
Any pretrained model can be used for inference via both the command-line interface (CLI) and Python. Before using the model, make sure that all required packages are installed using the command:
python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]Where ner_ontonotes_bert_mult denotes the name of the configuration file.
You can interact with the model via Python code.
In addition, DeepPavlov contains a RuBERT-based model for processing Russian-language data. Overall, the BERT-based models showed substantial improvements over bi-LSTM-CRF-based models. Here you can see the performance of the English- and Russian-based models.
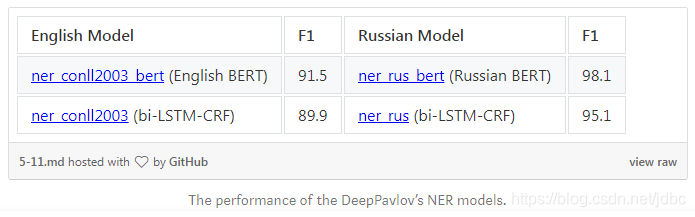
Multilingual Zero-Shot Transfer
The Multilingual BERT model allows to perform zero-shot transfer from one language to another. The model ner_ontonotes_bert_mult was trained on OntoNotes corpus (English) which has 19 types in the markup schema. You can test the model on different languages.
from deeppavlov import configs, build_model
ner_model = build_model(configs.ner.ner_ontonotes_bert_mult, download=True)
ner_model([
'Meteorologist Lachlan Stone said the snowfall in Queensland was an unusual occurrence '+
'in a state with a sub-tropical to tropical climate.',
'Церемония награждения пройдет 27 октября в развлекательном комплексе Hollywood and '+
'Highland Center в Лос-Анджелесе (штат Калифорния, США).',
'Das Orchester der Philharmonie Poznań widmet sich jetzt bereits zum zweiten '+
'Mal der Musik dieses aus Deutschland vertriebenen Komponisten. Waghalter '+
'stammte aus einer jüdischen Warschauer Familie.'])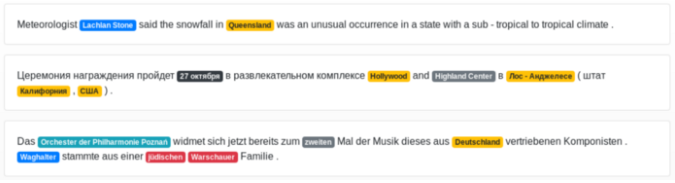
The multi-language model performance was evaluated on four NER test sets for German, Russian, Chinese,Vietnamese. These are the results of the transfer.
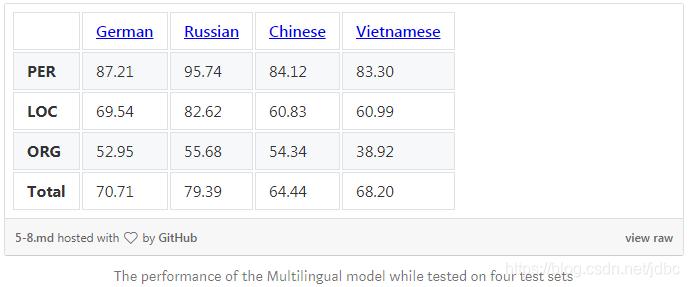
How to configure BERT for NER
The DeepPavlov NLP pipelines are defined in the separate configuration files under the config/faq folder. The config file consists of four main sections: dataset_reader, dataset_iterator, chainer, and train.
The common element of all BERT-based models is the BERT preprocessor (the bert_ner_preprocessor class in the case of NER) block in the chainersection of the configuration files. Unprocessed texts (i.e., “Alex goes to Atlanta”) should be passed to bert_ner_preprocessor for tokenization into subtokens, encoding subtokens with their indices, and creating tokens and segment masks. The tokens parameter itself contains a list of the sentence tokens ([‘Alex’, ‘goes’, ‘to’, ‘Atlanta’]), subword_tokens is tokens with special tokens ([‘[CLS]’, ‘Alex’, ‘goes’, ‘to’, ‘Atlanta’, ‘[SEP]’]).subword_tok_ids contains tokens ids, and subword_masks is a list with 0 for special tokens and 1 for sentence’s tokens ([0 1 1 1 1 0]).
{
"class_name": "bert_ner_preprocessor",
"vocab_file": "{BERT_PATH}/vocab.txt",
"do_lower_case": false,
"max_seq_length": 512,
"max_subword_length": 15,
"token_maksing_prob": 0.0,
"in": ["x"],
"out": ["x_tokens", "x_subword_tokens",
"x_subword_tok_ids", "pred_subword_mask"]
}So, this is pretty everything we wanted to tell you about our multilingual BERT-based NER. We hope this was helpful and you’ll be eager to use the DeepPavlov NER models ? You can read more about them here. Also feel free to test our BERT-based models by using our demo. And don’t forget DeepPavlov has a forum — just ask us anything concerning the framework and the models here, we’ll reach out to you back ASAP. Stay tuned!
Refer:














 3275
3275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









